Scientific databases and web databases maintain large and diverse data. Real-world databases contain over hundreds or even thousands of relations and attributes. Old predefined query forms don't seem to beable to satiate various ad-hoc queries from users on those databases. A novel user’s feedback relevant dynamic database query form interface is implemented, which is able to dynamically generate query forms result. The system is to capture a user’s preference and rank query form components, helping him/her to take decisions. The generation of a query form is an iterative process and is guided by the user. The ranking of form components is based on the captured user preference. A user can fill the query form and submit queries to view the query result at each iteration. In this way, a query form results could be dynamically refined till the user satisfies with the query results.
Keywords |
| Query form, user interaction, query form generation |
INTRODUCTION |
| One of the most extensively used user interfaces for querying databases to access information is query form. Historicquery forms are configured and predefined by developers or Database Administrator in different informationmanagement systems. With the fast development of web information and scientific databases, new databases becomevery huge and difficult. In natural sciences, like genetics and diseases, the databases have variety of entities forchemical and/or biological data resources. Diversekinds of web databases have thousands of structured web entities.Therefore, it is difficult to plan a set of static query forms to answer various ad-hoc database queries on those difficultand complex databases. |
| Existing tools for database management and development, such as SAP and Microsoft Access,users create customizedqueries on databases. However, the design of customized queries entirely depends on user’s manual editing .If a user isnot familiar with the database schema prior to, those hundreds or thousands of data attributes would confuse him/her. |
| 1.1 Approach |
| A user’s feedback relevant dynamic query form system is implemented, a query interface which is capable ofdynamically generating query forms for users. Users in database retrieval are often willing to perform many rounds ofactions (i.e., refining query conditions) before identifying the final candidates. |
| The essence of this is to capture user interests during user interactions and to adapt the query results iteratively. It startswith a basic query form which contains very few primary attributes of the database. Figure 1 shows user’s feedbackrelevant dynamic query form system’sflow. The basic query form is then iteratively enriched via the interactionsbetween the user and our system till the user is content with the query results. |
RELATED WORK |
| Customized Query Form:Existing database clientsand tools make great efforts to help developers design and generatethe query forms, such as EasyQuerySAP, Microsoft Access and so on. They deliver visual interfaces for developers tocreate or customize query forms. The difficulty of those tools is that, they are provided for the professional developerswho are familiar with their databases, not for end-users .Proposed a system which allows end-users to customize theexisting query form at run time. However, an end-user may not be aware with the database. For huge database schemais, it is difficult for them to catch appropriate database entities and attributes and to create desired query forms. |
| Auto-completion for Database Queries:In user interfaces have been developed to assist the user to type the databasequeries based on the query load, the data distribution and the database schema. Different from this which focuses onquery forms, the queries in their work are in the forms of SQL and keywords. |
QUERY FORM |
3.1 Interface for Query form |
| Each query form corresponds to an SQL query template. A query form F is defined as a tuple (AF, RF, σF, (RF)),which represents a database query template as follows:F= (SELECT A1,A2, ...,AkFROM (RF) WHERE σF ),where AF= {A1,A2, ...,Ak} are k attributes for projection, k >0.RF= {R1,R2, ...,Rn} is the set of n relations (or entities) involved in this query, n >0. Each attribute in AFbelongs to onerelation in RF. σFis a conjunction of expressions for selections (or conditions) on relations in RF. (RF) is a joinfunction to generate a conjunction of expressions for joining relations of RF. |
| In the user interface of a query form F, AFis the set of columns of the result table. σFis the set of input components to befilled by users. Query forms allow users to fill parameters to produce different queries. RFand (RF) are not visible inthe user interface, which are usually created by the system according to the database schema. For a query form F,(RF) is automatically constructed according to the foreign keys among relations in RF. Meanwhile, RFis determined byAFand σF. RFis the union set of relations which contains at least one attribute of AFor σF. Hence, the components of query form F are actually determined by AF and σF. Only AFand σFare visible to the user in the user interface. In this,the focus is on projection and selection components of a query form. |
| 3.2 Ranking Estimation |
| The user’s desired result is returned by query form. Two measures to evaluate the quality of the query results: precisionand recall . Query forms yield different queries by different inputs, and different queries can output different queryresults and achieve different precisions and recalls, so expected precision and expected recall is used to evaluate theexpected performance of the query form. Expected proportion of the query results which are interested by the currentuser is the expected precision. Expected proportion of user interested data instances which are returned by the currentquery form is the expected recall. The user interest is estimated based on the user’s click-through on query resultsdisplayed by the query form. |
| 3.2.1 Ranking of Attributes |
| Suggesting projection components is actually suggesting attributes for projection. The current query form be Fi, thenext query form be Fi+1. Let AFi = {A1,A2, ...,Aj}, and AFi+1 = AFi∪{Aj+1}, j+1 ≤ |A|. Aj+1 is the projection attributesuggest for the Fi+1, which maximizes FScoreE(Fi+1). FScoreE(Fi+1) is obtained as follows: |
| |
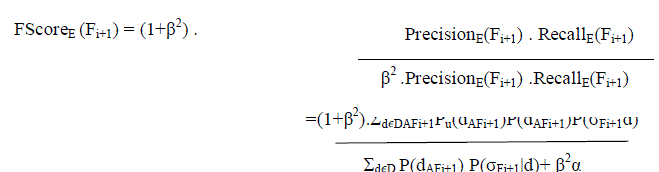 |
| Adding a projection component Aj+1 does not affect the selection part of Fi. Hence, σFi+1 = σFi and P(σFi+1|d) = P(σFi|d).Since Fi is already used by the user, estimate P(dAFi+1)P(σFi+1|d) as follows. For each query submitted for form Fi, keepthe query results including all columns in RF. Clearly, for those instances not in query results their P(σFi+1|d) = 0 and donot need to consider them. For each instance d in the query results, simply count the number of times they appear in theresults and P(dAFi+1)P(σFi+1|d) equals the occurrence count divided by N. |
| Pu(dAj+1|dAFi) is not visible in the runtime data, since dAj+1 has not been used before Fi+1.The conditional probabilityPu(dAj+1|dAFi) is estimated from following approach. |
| • Workload-Driven based approach: The conditional probability of Pu(dAj+1|dAFi) could be estimated from queryresults of historic queries. If a lot of users queried attributes AFi and Aj+1 together on instance d, then Pu(dAj+1|dAFi) mustbe high. |
| • Schema-Driven based approach: The database schema implies the relations of the attributes. If two attributesare contained by the same entity, then they are more relevant. |
| The schema graph is utilized to compute the relevance of two attributes. A database schema graph is denoted by G =(R,FK,ξ,A), in which R is the set of nodes representing the relations, A is the set of attributes, FK is the set of edgesrepresenting the foreign keys, and ξ : A → R is an attribute labelling function to indicate which relation contains theattribute |
| 3.2.2 Ranking Entities |
| The ranking score of an entity is just the averaged FScoreE(Fi+1) of that entity’s attributes. Intuitively, if one entity hasmany high score attributes, then it should have a higher rank. |
| 3.3 Relevant selection based on user feedback |
| The selection attributes must be relevant to the current projected entities, otherwise that selection would bemeaningless. Therefore, first the relevant attributes is find out for creating the selection components. |
| 3.3.1 Relevant Attribute Selection |
| The relevance of attributes in system is measured based on the database schema as follows. |
| Relevant Attributes: For a database query form F with a schema graph G=(R,FK,ξ,A), the relevant attributes is: Ar(F)= {A|A ∈ A, ∃Aj∈ AF, d(A,Aj) ≤ t}, where t is a user-defined threshold and d(A,Aj) is the schema distance. The choice of t depends on how compact of the schema is designed. For instance, some databases put all attributes ofone entity into a relation, then t could be 1. Some databases separate all attributes of one entity into several relations,then t could be greater than 1. |
| 3.3.2 Ranking Selection Components |
| For enriching selection form components of a query form, the set of projection components AFis fixed, i.e., AFi+1 = AFi.Therefore, FScoreE(Fi+1) only depends on σFi+1. To find the best selection component for the next query form, the firststep is to query the database to retrieve the data instances. P(σFi+1|d) depends on the previous query conditions σFi. IfP(σFi|d) = 0, P(σFi+1|d) must be 0. In order to compute the P(σFi+1|d) for each d ∈ D, no need to retrieve all datainstances in the database. The set of data instances D' ⊆ D is only needed such that each d ∈ D' satisfies P(σFi|d) >0. Sothe selection of One-Query’s query is the union of query conditions executed in Fi. One-Query adds all the selectionattributes into the projections of the query. |
| Query Creation: |
| Data: Q = {Q1, Q2, ….} is the set of previous queries executed on Fi |
| Result: Qone is the query of One-Query |
Methods |
| beginσone← 0for Q ε Q doσone← σone σQAone← AFi Ar (Fi)Qone← GenerateQuery (Aone, σone) |
| When the system receives the result of the query Qone from the database engine, it calls the second algorithm of One-Query to find the best query condition the system. The pseudocode for finding best" ≤ " condition is as follows:Find Finest Less Equation Condition |
| Data: α is the fraction of instances desired by user, DQone is the query result of Qone, As is the selection attribute.Result: S* is the best query condition of As |
| Begin// Sort by As into an ordered set DsortedDsorted← Sort (DQone, As)s* ← Ø, fscore* ← 0n← 0, d← αβ2for i ← 1 to |Dsorted| dod← Dsorted [i]s← “As<= dAs”// compute fscore of “As<= dAs”n ← n + Pu (dAFi) P (dAFi) P (σFi | d) P(s|d)d ← d+ P (dAFi) P (σFi | d) P(s|d)fscore ← (1+β2). n/dif fscore >= fscore* thens* ← sfscore* ← fscore |
| 3.4 Evaluation |
| To evaluate the quality of the query results mainly : precision and recall is used. Different inputs through query formsproduce different queries, and different queries produce different query results and achieve different precisions andrecalls, so to evaluate the expected performance of the query form expected precision and expected recall is used. Theexpected proportion of the query results which are interested by the current user is Expected precision |
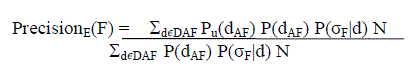 |
| The expected proportion of user interested data instances which are returned by the current query form is calledExpected recall |
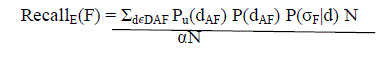 |
| Considering both precision and recall, Fscore is derived as follows: |
| |
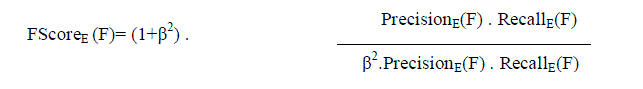 |
| |
| The user interest is based on the user’s click-through on query results displayed by the query form. |
RESULTS |
| The query form captures user’s feedback. User select components and on that selection basis query result is generated.User can refine component selection for a refined query results. The basic query form is enriched iteratively through theinteraction between the user and the system until the user is satisfied with the query results. Ranking of formcomponents is done and query results are generated |
| In the above figures, user selects desired column component and row component in query form for the desired results. More refined row component selection is done for the refined query results. Finally after making the relavantcomponent seleciton refined query results is obtained. |
CONCLUSION AND FUTURE WORK |
| A user’s feedback relevant dynamic query form generation is done which helps users dynamically generate queryforms. The vitalnotion is to use a probabilistic model to rank form components based on user preferences. Userpreference is captured using both historical queries and run-time feedback such as click. The ranking of formcomponents makes it easier for users to customize query forms. As future work, this approach can be extended to nonrelationaldata. Multiple methods to capture the user’s interest for the queries besides the click feedback is planned todevelop. For instance, a text-box can be added for users to input some keywords queries. |
Figures at a glance |
 |
 |
 |
 |
 |
| Figure 1 |
Figure 2 |
Figure 3 |
Figure 4 |
Figure 5 |
|
| |
References |
- Liang Tang, Tao Li ; Yexi Jiang; Zhiyuan Chen, âÃâ¬ÃÅDynamic Query Forms for Database QueriesâÃâ¬ÃÂ, Knowledge and Data Engineering, IEEETransactions on (Volume:26 , Issue: 9 )
- 2.EasyQuery.http://devtools.korzh.com/eq/dotnet.
- A. Nandi and H. V. Jagadish âÃâ¬ÃÅAssisted querying using instantresponseinterfacesâÃâ¬ÃÂ. In Proceedings of ACM SIGMOD, pages1156âÃâ¬Ãâ1158, 2007
- 4.Yun Zhou and W. Bruce Croft âÃâ¬ÃÅRanking Robustness: A Novel Framework to Predict Query PerformanceâÃâ¬Ã CIKMâÃâ¬Ãâ¢06, November 5âÃâ¬Ãâ11, 2006,
- Arlington, Virginia, USA
- Ricardo Baeza-Yates, BerthierRibeiro-NetoâÃâ¬ÃÅModern information retrievalâÃâ¬Ã Publish Addison âÃâ¬ÃâWesley
|