Keywords
|
| Logic Link Control, Media Access Control. |
INTRODUCTION
|
| With the proliferation of PDAs and other wireless devices, wireless traffic is probably at an all time high [1]. Wireless Local Area Networks or WLANs are also experiencing their share of a fair amount of traffic growth Concurrently, the use of multimedia application on wireless devices have also surged thus making multimedia traffic over WLANs a common phenomenon. However, it is the bandwidth intensive multimedia traffic that takes the most brunt when a WLAN is overloaded. Longer packet delay, jitter and lower throughput deteriorate the video quality significantly at the receiving end, thus diminishing the user experience [2]. Extensive work has been carried out on analysis of the bit rate variation of streaming video packets over WLAN networks and detailed study of their performance has been tabulated [3][4]. I have performed extensive experiments to study the performance of high bit rate streaming video streaming under variously congested wireless network conditions. Like [5], And concluded that received video loses its quality miserably under congested wireless networks. |
| The results of this experiments also led us to conclude that the primary reason for this to happen was the loss of particular packets of the encoded video frames which play the most significant role in decoding the video stream. This led to propose a novel scheme to enhance the QoS requirement and hence protect the quality of the video stream at the receiver’s end. Based on the prior study, I have devised a scheme where we prioritize packets within a given video stream. We associate highest priority to those particular video packets that are crucial in the video decoding process and allocate preferential network resources to these preferred video packets thus protecting them from network calamities like packet loss and extensive delays. We also ascertain that we do not starve other traffic in the network. |
| Unlike most other work in the literature [5][6][7] that focus mainly on IEEE 802.11e-like mechanisms to enhance QoS in multimedia traffic,ours is independent of the underlying wireless technology. Also, the scope of these studies is limited solely to the 802.11 MAC sub layer while ours is not. In our work we focus a little higher in the 802.x stack and use the interface between IEEE 802.2 Logical Link Control (LLC) layer and IEEE 802.11 Medium Access Control (MAC) layer to make amendments to the protocol. This is particularly interesting because this makes our work portable across all kinds of low bandwidth MAC wireless protocols such as Bluetooth and ZigBee. |
| This work is particularly significant because available literatures and publications [6][7][8] do not talk about possible QoS implementations between the protocol layers. Interface queues between the protocol layers offers best effort service (FIFO) to all data packets and do not classify/categorize the type of packets passing through it. In this paper we do classify packets and provide priority to most significant video packets. Extensive simulation performed on the Netsim platform, shows that the proposed scheme improves the quality of video streaming significantly while impacting other concurrent audio streaming and FTP traffic insignificantly. The rest of this paper is organized as follows: Section II discusses the basics of virtual bottleneck concept over 802.11 protocol stack respectively. Section III streaming architecture and outlines the video QoS enhancing algorithm. Section IV.discuss the scheduling technique. Section V shows the experimental setup .Section Finally, we conclude the paper in Section VI. |
RELATED WORK
|
| The approach proposed for application aware support of H.264 SVC delivery over WLANs is illustrated in Figure 1. In this paper we restrict our investigation to the case of “downlink video streaming”. This is representative of a videoon- demand scenario, where end users connected to a WLAN hotspot independently access one or more video servers placed in the wired network. |
| The idea behind the Virtual Bottleneck (VBN) illustrated in Figure 1 is very simple, but practical and effective. It emerges from the observation that MAC-layer frame losses only rarely occur in a Wireless LAN because of channel quality impairments. In fact, starting from Auto Rate Fall- back [6], several rate adaptation mechanisms [7] have been proposed to improve frame delivery, by estimating the channel quality and/or measuring the experienced frame loss ratio, and then switching to a suitable modulation scheme. The 802.11 MAC function retransmits MAC frames corrupted because of channel errors or channel access collisions. As a result, a MAC frame is lost completely only if it reaches a maximum number of retransmissions. In the 802.11 standard, this is a relatively large value (the default settings being 4 – Short Retry Limit – and 7 – Long Retry Limit – retransmissions, depending on the length of the MAC frame [5]). Therefore, in normal conditions, the MAC frame loss ratio seen by higher layers is typically low. It only becomes significant if severe channel degradation occurs, so harshly that even rate adaptation to the minimal available transmission rate is not sufficient. |
| We can thus assume that the majority of all MAC frame losses occur at the AP buffer. Loss events clearly occur when the load offered to the AP is greater than the maximum throughput available at the AP. In general, the time-varying capacity CAP (t) depends on i) the number of stations com- peting with the AP for channel access and ii) the individual transmission rates of all competing stations [8]. |
| The Virtual BottleNeck is a traffic control box placed in the wired network before the AP. It intercepts all the traffic offered to the AP itself. Its goal is to enforce a traffic throttling function devised to prevent the traffic offered to the AP from overflowing the available capacity CAP (t) . Provided that the throttling function is able to follow the variations in time of the AP capacity, and provided that a sufficient AP buffering capability is available and a sufficient bandwidth margin is deployed between the traffic offered by the VBN and the actual AP capacity, the ultimate result is that the AP buffer will never saturate, and hence no frame loss will occur at the AP itself. Rather, all the losses will occur inside the VBN box. Several mechanisms exist for the run-time estimation of the available AP capacity and the consequent dynamic control of the throttling function, e.g., [17], [18], [19], [20]. However, the details of this estimation are outside the scope of the present paper. Here, we are interested in taking full advantage of the VBN in exploiting application layer information for scheduling traffic. We remark that since the VBN is a separate control entity, it can easily be deployed in any pre-existing WLAN infrastructure with legacy Access Points. If the WLAN supports 802.11e Quality of Service enhancements (as is the case in our experimental set-up), these can be exploited by configuring the VBN to set the IP Type Of Service (TOS) field to the value 160 (for WMM - Wireless Multimedia - compliant APs) so that MAC frame transmission occurs with EDCA video access category. |
PROPOSED ALGORITHM
|
| In this section, we describe briefly the different CLD categories used in wireless video streaming. Further details on this topic are detailed in [18]–[20]. We then describe the Q-learning approach used in the CLD and applied to the medical video streaming. |
| A. Wireless Cross-Layer Adaption Scheme |
| The CLD refers to protocol and model architecture design which exploit the dependence between layers to obtain optimum gains. This is not against the layering concepts; actually it is an attached model to the open system interconnection OSI) model. Cross-layer systems use different models and algorithms that depend on the architecture that is being used in such implementation. In this part, we are going to review the cross-layer architectures and choose one particular model that fits best In general, crosslayer systems perform three major tasks: data abstracting, optimizing, and reconfiguration. Abstraction and reconfiguration strictly depend on the system model and the interaction between the layers, and optimization algorithms and protocols are used for allocating the optimal solution. The most significant crosslayer models are shown as follows [13]. |
| 1) Integrated Approach: this model takes an optimal decision based on all information, parameters, and requirements, which are received from the different layers. Despite other approaches, all layers can send their required quality, and there is not only a unique layer to dictate the quality to the other layers. Therefore, this model should provide different requirements for different layers; this makes this approach the best suit- able method for the current application. However, this approach needs a real-time optimization method to provide the optimal layer values. |
| In general, a cross layer can add computation complexities for finding the optimal QoS strategy because the number of QoS strategies is increasing in comparison to layer architecture. Formulas (1)–(3) show this fact [20] |
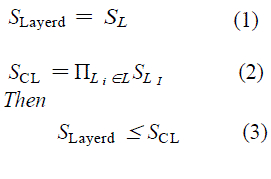 |
| where SLaye rd and SCL are QoS strategies in layered and cross- layer architecture, respectively, L is set of the layers, and Li is ith layer. In this paper, for decreasing real-time computational complexity, we use a RL algorithm. |
| B. Problem Formulation and the Q-Learning Approach |
| As explained in the earlier section, we adopted the use of Q-learning as an RL method to find the best action for different cross-layer parametric variations. In this approach, RL agents learn how to act so as to maximize a numerical reward signal. The process of optimizing in cross layer is based on a discrete-time Markov decision process, which is a stochastic process modeled by a finite number of states S. For each state S, a finite set of actions A is possible. By selecting the action αk ∈ A at the time step k, we incur a cost/reward c(Sk , αk ).The schematization of this method is A policy in the agent (π) consists of the assignment of an action αk in correspondence with the state Sk at each time step k. The cross- layer optimizer (CLO) acts as the decision maker, known as the agent that monitors the environment state and assigns actions accordingly. When the agent releases this action, the environment’s state changes; the agent receives the new environment’s state and immediate reward or cost as a consequence of the previous action. Based on this information, the agent updates its knowledge database. |
| The process is repeated until the agent reaches an optimal policy π that assigns optimal actions leading the environment to a state that satisfies the system requirements. The objective of the agent is to find an optimal policy resulting in the action αk for each Sk , which satisfies the cost function [2], [20]. |
| The principle of the Q-learning approach is based on a trial and repeat process. An agent tries an action at a particular state and evaluates its consequences in terms of the immediate rewards or cost it receives, and then estimates the value of the state to which it is taken. By trying all actions in all states repeatedly, the Q matrix will be created to be referred for finding the best action in a specific situation. The Q and reward matrices are monitored to be updated if required [2], [20]. |
| After indicating the legal actions and states for every possible state and action, we will calculate its cost by a cost function, which is defined in (4). If state-action pair (Sk , αk ) has been determined, an immediate cost is defined by the cost function [1]. Sk includes video stream quality and link quality (Vk , Lk ), and Sk is created after abstracting the state. In total we use 216 states. , and 27 actions for each state; it means cost function needs about 216 × 27 actions to be ready; this process needs to be done at the beginning only. Then, during the online process, the Q matrix will be scanned and an action will be selected based on the state condition of the system. The Q-relearning process will be done as a background process. This concept is described elsewhere [24]. |
SCHEDULING TECHNIQUE
|
| A) H.263 |
| An H.263 stream is a sequence of NALUs. A NALU is formed by a header and a payload carrying the actual encoded video frame. The NALU header contains information about the NALU type and its relevance in the decoding process. From the information reported in the NALU header (see full details in [9], or [13]), we are specifically interested in the three parameters called dependency id (DID), temporal id (TID), and quality id (QID). Each parameter determines a specific scalability facility. DID allows Coarse Grain Scalability, TID allows Temporal Scalability and QID allows Medium Grain Scalability. |
| Coarse Grain Scalability (CGS) provides the ability to coarsely adapt a video performance; e.g., video’s spatial resolution from CIF to 4CIF. The video should be encoded with a suitable set of coarse enhancement sub-streams, called dependency-layers. DID is the identification of the dependency-layer of the NALU. The decoding of a NALU belonging to the dependency-layer did > 0 depends on NALUs of dependency-layer did − 1, with the same value of TID and QID. Following this dependency rule, we can coarsely reduce video quality by removing NALUs with a DID greater than a specific value. For simplicity, we do not consider Coarse Grain Scalability in the rest of this paper. However, extending our work to CGS is straightforward. |
| Temporal Scalability provides the ability to adapt the video frame-rate. The TID specifies the temporal-layer of the NALU, i.e., the “frame-rate sub-stream”. A NALU belonging to the temporal-layer tid > 0 and with qid = 0 depends on NALUs of temporal-layer tid − 1, with the same DID and QID. Following this rule, a frame-rate scaling should be accomplished by removing NALUs with a TID greater than a specific value Medium Grain Scalability (also called progressive refinement) allows the adaptation of video quality (i.e., PSNR). The video should be appropriately encoded with a set of quality enhancement sub-streams, called quality-layers. A qualitylayer reduces the encoding quantization error, and thus improves the PSNR. The QID identifies the quality-layer of the NALU. A NALU belonging to the quality-layer qid > 0 depends on NALUs of quality-layer qid − 1, with the same DID and TID. Following this dependency rule, the quality scaling should be accomplished by removing NALUs with a QID greater than a specific value. Overall, with reference to temporal and medium grain scalability, the dependency rules can be summarized as follow, where the arrow means “depends on” |
| (tid > 0, qid = 0) → (tid − 1,qid = 0) |
| (tid ≥ 0, qid > 0) → (tid, qid − 1) |
| B.H.263 application Scheduler |
| The design target of our proposed application-aware scheduler is to exploit H.263 SVC NALU types and their dependencies to |
| 1) accomplish an efficient usage of the wireless resource by avoiding to transfer NALUs that will not be decoded by the receiver because of missing dependencies; |
| 2) provide a smooth adaptation of the video quality versus changes in the available capacity CAP (t) or the offered load of the video traffic. |
| These two goals can be accomplished through a priority queuing discipline, dedicating a separate queue to each possible TID-QID combination. Considering that the default range for TID values is from 0 to 4, and considering two additional enhancement quality-layers (i.e., QID values in the range from0 to 2), we deploy 5 × 3 = 15 limited-size queues, with queue #0 having the highest priority and queue #14 having the lowest one, as shown in Figure 2. An incoming NALU is delivered to a queue #n according to the following classification rule: |
| n = 5qid + tid |
EXPERIMENTAL RESULTS
|
| The experiments are based on an indoor WLAN deployment with 5 stations associated to an AP. All stations experience good average channel conditions (the distance to the AP is less than 2 meters in LOS conditions) and support the maximum 11 Mbps 802.11b physical layer rate with no losses. The VBN has been throttled to 6.0 Mbps, a value just below the measured MAC throughput at the AP of about 6.3 Mbps. This guarantees, as we confirmed in subsequent measurements, that no MAC frames are lost at the AP buffer. Moreover, we also perform tests with the WLAN physical layer rate reduced to 2 Mbps; in this cases the VBN is throttled to 1.5 Mbps. For the evaluation, results are reported in terms of a video quality metric (PSNR) as well as a delivery efficiency metric. |
| A) Impact of VBN |
| Figure 3 shows the Y-PSNR (luminance) over time, measured for the video stream SVC (A) delivered to the first user with and without VBN scheduling, with respect to the original, pre-encoding raw video. The PSNR is compared to two reference curves: i) the ideal PSNR (top curve labeled “all layers”) of the stream for the case of no NALU loss, where the resulting PSNR depends only on the degradation due to the encoding process, and ii) the PSNR provided by the base layer only (labeled “base layer”), assuming that all base layer NALUs are received and all NALUs of other layers are dropped. |
| Figure 3 confirms that the delivery performance of H.263 SVC is poor without application-aware scheduling enforced by the VBN, i.e., when MAC frames, and as a consequence NALUs, are dropped randomly. A sudden severe PSNR degradation occurs under overload conditions. The resulting video frequently “freezes” (meaning that several video frames were lost), and the overall video quality is unacceptable. |
| With an average total video rate of 2.86 Mbps, this happens when three streams are delivered. The PSNR does not degrade further when additional streams are admitted. This is due to the fact that the PSNR given by the comparison of two random frames from the same test sequence is around 15 dB, as confirmed by further experiments (not shown here). Thus, this is the lowest PSNR value we can expect. Conversely, the application-aware scheduler allows for a smooth degradation of the H.264 SVC stream. When all 5 users share the channel, they achieve an average rate of 700 kbps per user. The PSNR approaches that of the base layer alone, which is the expected behavior, given that the base layer uses on average 650 kbps. |
| The figure above describes the transmitted video is received successfully at the receiver side Many clients can access video at the same time but the approach here we are using is video streaming without cross-layer approach and VBN, so the quality of video of the received video frames is not good and more jitter is present. |
| The figure above describes the transmitted video is received successfully at the receiver side. Many clients can access video at the same time but the approach here we are using is video streaming over WLAN with cross-layer approach and VBN,so the quality of video of the received video frames is very good and here we will get jitterless video. |
CONCLUSION AND FUTURE WORK
|
| I have presented a comparative analysis study of optimized cross-layer video streaming over WLAN.WLAN provides a better performance in terms of fps, frame Size and PSNR which is given in term of 85% efficiency, missing frames are 2-4 and average 34.67%. My future work is to use the H.264 CODEC for the video processing in the server to get improvised frames and right now I am just streaming the video and in future I will be carry out work on streaming video and audio both parallel. |
ACKNOWLEDGEMENT
|
| I would like to express my sincere gratitude to my Institution Sri Taralabalu Jagadguru Institute of Technology, Guide and Staff members for their continuous support for this survey and finally my friends for their coordination in this work. |
Figures at a glance
|
 |
 |
 |
 |
 |
| Figure 1 |
Figure 2 |
Figure 3 |
Figure 4 |
Figure 5 |
|
| |
References
|
- T. Kwon, H. Lee, S. Choi, J. Kim, D.-H. Cho, S. Cho, S. Yun, W.-H.Park, and K. Kim, “Design and Implementation of a Simulator Based on a Cross-Layer Protocol between MAC and PHY Layers in a WiBroCompatible IEEE 802.16e OFDMA System,” IEEE Communications Magazine, vol. 43, no. 12, pp. 136-146, Dec. 2005.
- J. –Y. Pyun, “Channel-Adaptive Mobile Streaming Video Control over Mobile WiMAX Network,” in Korean Proc. of the Institute of Electronics Engineerings of Korea (IEEK), vol. 46 CI, no. 5, pp. 37-43,Sep. 2009.
- A. Y. P. Fallah, P. Nasiopoulos, H. Alnuweiri, “Efficient Transmission of H.264 Video over Multirate IEEE 802.11e WLANs”, EURASIP Journal on Wireless Communications andNetworking, 2008
- Chuan Heng Foh, Yu Zhang, Zefeng Ni, Jianfei Cai, King Ngi Ngan, “Optimized Cross-Layer Design for Scalable Video Transmission Over the IEEE 802.11e Networks”, IEEE Trans. on Circuits and Systems for Video Technology, Vol. 17, No. 12, Dec. 2007
- IEEE Standard 802.11-2007, IEEE Standard for Information technology-Telecommunications and information exchange between systems - Local and metropolitan area networks-Specific requirements - Part 11: Wireless LAN Medium Access Control (MAC) and Physical Layer (PHY) Specifications; June 2007
- A. Kamerman, L. Monteban, “WaveLAN-II: A high performance wirelessLAN for the unlicensed band”, Bell Labs Technical Journal, 1997, volume2, issue 3, pp. 118-133.
- K. Ramachandran, H. Kremo, M. Gruteser, P. Spasojevic, I. Seskar, “Scalability Analysis of Rate Adaptation Techniques in Congested IEEE 802.11 Networks: An ORBIT Testbed Comparative Study”, IEEE WoWMoM2007.
- M. Heusse, F. Rousseau, G. Berger-Sabbatel, A. Duda, “Performance anomaly of 802.11b”, IEEE Infocom, 2003.
- Joint Video Team (JVT) of ISO/IEC MPEG and ITU-T VQEG, Joint Scalable Video Model. Doc. JVT-X202, July 2007.
- Joint Scalable Video Mode - reference software:http://ip.hhi.de/imagecomG1/savce/downloads/SVC-Reference- Software.htm
- T.Zahariadis, “ASTRALS Project presentation”, IBC 2007, Amsterdam, September 2007
- I. Kofler,M. Prangl, R. Kuschnig, H. Hellwagner, “An H.264/SVC- based adaptation proxy on a WiFi router”, 18th ACM Int. Workshop on Network and Operating Systems Support for Digital Audio and Video
- (NOSSDAV), Braunschweig, Germany, May 2008, pp. 63-68.
- R. Kuschnig, I. Kofler, M. Ransburg, H. Hellwagner,“Design optionsand comparison of in-network H.264/SVC adaptation”, J. of VisualCommun. and Image Representation, Vol. 19, No. 8, Dec. 2008, pp. 529-542.
- M.Eberhard, L.Celetto, C.Timmerer, E. Quacchio, H.Hellwagner, F.S. Rovati, “An interoperable streaming framework for Scalable Video Coding based on MPEG-21”, 5th Int. Conf. on Visual Information Engineering, Aug. 2008. VIE 2008, pp.723-728
- D. Wu, Y. T. Hou, Y. Q. Zhang, “Scalable video coding and transportover broadband wireless networks”, Proc. IEEE, vol. 89, no. 1, pp. 6- 20,2001.
- G. Bianchi, A. T. Campbell, R. Liao, “On utility-fair adaptive services in wireless networks”, 6th Int. Workshop Quality of Service (IWQOS’98), Napa Valley, CA, May 1998
- H. K. Lee, V. Hall, K. H. Yum, K. Kim, E. Kim,“Bandwidth estimation in wireless LANs for multimedia streaming services”, IEEE Int. Conf. onMultimedia and Expo (ICME), 2006.
- C. Sarr, C. Chaudet, G. Chelius, I. Lassous, “A node-based available bandwidth evaluation in IEEE 802.11 ad hoc networks”, 11th Int. Conf. on Parallel and Distributed Systems (ICPADS), 2005.
- S. Shah, K. Chen, K. Nahrstedt, “Available bandwidth estimation in ieee 802.11-based wireless networks”, ISM CAIDA Workshop on BandwidthEstimation (BEst), 2003.
- M. Neilsen, K. Ovsthus, L. Landmark, “Field trials of two 802.11 residual bandwidth estimation methods”, IEEE Int. Conf. on Mobile Adhoc and Sensor Systems (MASS), 2006
|