Speech is one of the most promising models by which people can express their emotions like anger, sadness, and happiness. These states can be determined using various techniques apart from facial expressions. Acoustic parameters of a speech signal like energy, pitch, Mel Frequency Cepstral Coefficient (MFCC) are important in finding out the state of a person. In this project, the speech signal is taken as the input and by means of MFCC feature extraction method, 39 coefficients are extracted by using MFCC. The large amount of extracted features may contain noise and other unwanted features. Hence, an evolutionary algorithm called as Ant Colony Optimization (ACO) is used as an efficient feature selection method. By using Ant Colony Optimization technique the unwanted features are removed and only best feature subset is obtained. It is found that the total number of features extracted get reduced considerably. The software used is MATLAB 13a.
Keywords |
| Ant Colony optimization, MFCC, feature selection, speech recognition |
INTRODUCTION |
| Research in speech processing and communication for the most part, was motivated by people those desire to build
mechanical models to emulate human verbal communication capabilities. Speech is the most natural form of human
communication and speech processing has been one of the most exciting areas of the signal processing. Speech
recognition technology has made it possible for computer to follow human voice commands and understand human
languages. The main goal of speech recognition area is to develop techniques and systems for speech input to machine.
Most of today’s Automatic Speech Recognition (ASR) systems are based on some type of Mel-Frequency Cepstral
Coefficients (MFCCs), which have proven to be effective and robust under various conditions.To enhance the accuracy
and efficiency of the extraction processes, speech signals are normally pre-processed before features are extracted.
Speech signal pre-processing covers digital filtering and speech signal detection. |
| The objective of this paper is to optimize the features extracted from the Mel Frequency Cepstral Coefficients (MFCC)
using Ant Colony Optimization (ACO) algorithm. This can improve the performance of the Automatic Speech
Recognition (ASR). Automatic speech recognition has made enormous strides with the improvement of digital signal
processing hardware and software. Although significant advances have been made in speech recognition technology, it
is still a difficult problem to design a speech recognition system for speaker independent, continuous speech. One of the
fundamental questions is whether all of the information necessary to distinguish words is preserved during the feature
extraction stage. If vital information is lost during this stage, the performance of the following classification stage in the
ASR is inherently crippled and can never measure up to human capability. Thus, efficient techniques for feature
extraction and feature selection have to be used in order to increase the speed of recognition. As a result, the
performance of the Automatic Speech Recognition system can be improved. It is shown that as the number of iterations
increased, the number of features get reduced. Section II explains about the overview of Automatic Speech Recognition (ASR) is presented. In section III, extraction of features using MFCC is presented. The feature selection algorithm
called Ant Colony Optimization (ACO) is described in section IV. The results are discussed in section V. Conclusion
and future work is presented in section VI. |
OVERVIEW OF ASR |
| Speech Recognition (also known as Automatic Speech Recognition (ASR) or computer speech recognition) is the
process of converting a speech signal to a sequence of words which is shown in figure 1 and it is implemented as
algorithm in computer. |
| In the first step, the Feature Extraction, the sampled speech signal is parameterized. The goal is to extract a number of
parameters (‘features’) from the signal that has a maximum of information relevant for the following classification.
That means features are extracted that are robust to acoustic variation but sensitive to linguistic content. Put in other
words, features that are discriminate and allow distinguishing between different linguistic units (e.g., phones) are
required. On the other hand the features should also be robust against noise and factors that are irrelevant for the
recognition process (e.g., the fundamental frequency of the speech signal). |
| In the modeling phase the feature vectors are matched with reference patterns, which are called acoustic models. The
reference patterns are usually Hidden Markov Models (HMMs) trained for whole words or, more often, for phones as
linguistic units. HMMs cope with temporal variation, which is important since the duration of individual phones may
differ between the reference speech signal and the speech signal to be recognized. A linear normalization of the time
axis is not sufficient here, since not all phones are expanded or compressed over time in the same way. In between the
feature extraction and modeling phase, features selection algorithm is used. Algorithms like Evolutionary algorithms,
Genetic algorithm and Neural Network based algorithms can be used for selecting best subset among the whole feature
set. |
FEATURE EXTRACTION BY MFCC |
| Feature extraction can be understood as a step to reduce the dimensionality of the input data, a reduction which
inevitably leads to some information loss. Typically, in speech recognition, speech signals are divided into frames and
extract features from each frame. During feature extraction, speech signals are changed into a sequence of feature
vectors. Then these vectors are transferred to the classification stage. |
| MFCC is mostly used for Automatic Speech Recognition because of its efficient computation and robustness. Filtering
includes pre-emphasis filter and filtering out any surrounding noise using several algorithms of digital filtering. Finally
36 coefficients are extracted from the Mel Frequency Cepstral Coefficient Method. The block diagram representing
MFCC is shown in figure 2. MFCC consists of seven computational steps. Each step has its function and mathematical
approaches as discussed briefly in the following: |
| A. Pre–emphasis |
| This step processes the passing of signal through a filter which emphasizes higher frequencies. This process will
increase the energy of signal at higher frequency. |
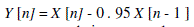 (1) (1) |
| Assume a = 0.95, which make 95% of any one sample is presumed to originate from previous sample. |
| B. Framing |
| The process of segmenting the speech samples obtained from analog to digital conversion (ADC) into a small frame
with the length within the range of 20 to 40 msec. The voice signal is divided into frames of N samples. Adjacent
frames are being separated by M (M<N). Typical values used are M = 100 and N= 256. |
| C. Hamming windowing |
| Hamming window is used as window shape by considering the next block in feature extraction processing chain and
integrates all the closest frequency lines. |
| y(n) = Output signal |
| x (n) = input signal |
| w(n) = Hamming window, then the result of windowing signal is shown below: |
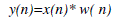 (2) (2) |
| D. Fast Fourier Transform |
| To convert each frame of N samples from time domain into frequency domain. The Fourier Transform is to convert the
convolution of the glottal pulse u[n] and the vocal tract impulse response h[n] in the time domain. This statement
supports the equation below: |
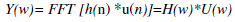 (3) (3) |
| E. Mel-Scaled Filter Bank |
| The filter bank analysis consists of a set of band pass filter whose bandwidths and spacing’s are roughly equal to
those of critical bands and whose range of the centre frequencies covers the most important frequencies for speech
perception The filter bank is a set of overlapping triangular band pass filter, that according to mel-frequency scale, the
centre frequencies of these filters are linear equally-spaced below 1 kHz and logarithmic equally-spaced above.
The speech signal consists of tones with different frequencies. For each tone with an actual Frequency, f, measured in
Hz, a subjective pitch is measured on the ‘Mel’ scale. We can use the following formula to compute the mels for a
given frequency f in Hz: |
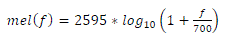 (4) (4) |
| F. Discrete Cosine Transform |
| This is the process to convert the log Mel spectrum into time domain using Discrete Cosine Transform (DCT). The
result of the conversion is called Mel Frequency Cepstrum Coefficient. The set of coefficient is called acoustic vectors.
Therefore, each input utterance is transformed into a sequence of acoustic vector. The IFFT needs complex arithmetic, the DCT does not. The DCT implements the same function as the FFT more efficiently by taking advantage of the
redundancy in a real signal. The DCT is more efficient computationally. |
FEATURE SELECTION BY ACO |
| The main focus of this algorithm is to generate subsets of salient features of reduced size. ACO Feature Selection
utilizes a hybrid search technique that combines the wrapper and filter approaches. In this regard, ACO Feature
Selection modifies the standard pheromone update and heuristic information measurement rules based on the above
two approaches. The reason for the novelty and distinctness of ACO Feature Selection algorithm versus previous
algorithms like PSO, GA, lies in the following two aspects. |
| First, ACO Feature Selection emphasizes not only the selection of a number of salient features, but also the attainment
of a reduced number of them. ACO Feature Selection selects salient features of a reduced number using a subset size
determination scheme. Such a scheme works upon a bounded region and provides sizes of constructed subsets that are
smaller in number. Thus, following this scheme, an ant attempts to traverse the node (or, feature) space to construct a
path (or, subset). However, a problem is that, feature selection requires an appropriate stopping criterion to stop the
subset construction. Otherwise, a number of irrelevant features may be included in the constructed subsets, and the
solutions may not be effective. To solve this problem, some algorithms, define the size of a constructed subset by a
fixed number of iteration for all ants, which is incremented at a fixed rate for following iterations. This technique could
be inefficient if the fixed number becomes too large or too small. Therefore, deciding the subset size within a reduced
area may be a good step for constructing the subset while the ants traverse through the feature space. |
| The main structure of ACOFS is shown in figure 3. However, at the first stage, while each of the k ants attempt to
construct subset, it decides the subset size r first according to the subset size determination scheme. This scheme guides
the ants to construct subsets in a reduced form. Then, it follows the conventional probabilistic transition rule for
selecting features as follows, |
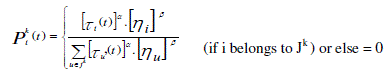 (5) (5) |
| where, |
| Jk = set of feasible features |
| ηi = pheromone value |
| τi = heuristic desirability associated with feature i |
| α and β = two parameters that determine the relative importance of the pheromone value and heuristic
information. |
| The approach used by the ants in constructing individual subsets during Subset Construction (SC) can be seen in figure
4. |
| A quantity of pheromone, on each node is given as: |
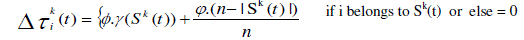 (6) (6) |
| where, |
| Sk(t) = feature subset found by ant k at iteration t |
| |Sk(t)| = feature Subset length. |
| The addition of new pheromone by ants and pheromone evaporation are implemented by the following rule applied to
all the nodes: |
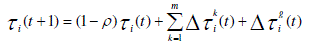 (7) (7) |
| where, |
| m = number of ants at each iteration |
| p(0,1) = pheromone trail decay coefficient. |
RESULTS AND DISCUSSIONS |
| A. Implementation of Feature Extraction Algorithm |
| Figure 5 represents the group of filters used in the proposed work. Totally 24 filters are designed in which filters with
cut off frequency upto 1 KHz are linear and above 1 KHz are logarithmic. Figure 6, shows the input speech signal for
the feature extraction stage. Figure 7, shows the Mel Frequency Cepstral Coefficient (MFCC) output for the applied
input speech signal. Initially Mel filter bank is implemented and then the MFCC output is obtained. |
| B. Implementation of Feature Selection Algorithm |
| In the implementation of ACO- Feature Selection algorithm, initially for 100 numbers of maximum iterations and for 6,
12, 13, 26 and 39 coefficients the best feature subset is obtained. Then the length of the best feature subset is
calculated. The above procedure is performed for 200 and 300 iterations also. The length of the feature subset is also
calculated for those MFCC coefficients separately for all 300 iterations. The total features taken are about 312. |
| The resulted values are tabulated and the ratio of length of feature subset obtained in 200 iterations and 300
iterationsfor 39 MFCC coefficients is calculated. Table 1 shows the length of the best feature subset for maximum
number of iterations 100, 200 and 300 for the corresponding number of Mel Frequency Cepstral Coefficients. |
| From the table, we have observed that the number of features get reduced to about 16.6% in 300 iterations compared to
100 iterations. Compared to other optimization algorithms the ACO performs well. |
CONCLUSION & FUTURE WORK |
| In this project, the problem of optimizing the acoustic feature set by Ant Colony Optimization (ACO) technique for
Automatic Speech Recognition (ACO) system is addressed. Some modifications of the algorithm are done and apply it
to larger feature vectors containing Mel Frequency Cepstral Coefficients (MFCC) and their delta coefficient, and two
energies. Ant Colony Optimization algorithm selects the most relevant features among all features in order to increase
the performance of Automatic Speech Recognition system. From the tabulated results it is observed that the number of
features get reduced when number of iterations increased and also number of MFCC coefficients increased. Compared
to number of features obtained in 100 iterations, the features get reduced to 16.6% in 300 iterations. Ant Colony
Optimization is able to select the more informative features without losing the performance. |
| Future work is to apply the best feature subset obtained from the proposed Ant Colony Optimization (ACO) algorithm
to the modeling phase. |
ACKNOWLEDGEMENT |
| Authors would like to thank Dr. S.Valarmathy and Ms. Kalamani for their support in implementation of this project. |
| |
Tables at a glance |
 |
| Table 1 |
|
| |
Figures at a glance |
 |
 |
 |
 |
| Figure 1 |
Figure 2 |
Figure 3 |
Figure 4 |
 |
 |
 |
| Figure 5 |
Figure 6 |
Figure 7 |
|
| |
References |
- A. Biem and S. Katagiri, âÃâ¬ÃÅCepstrum-based filter-bank design using discriminative feature extraction training at various levels,âÃâ¬Ã in Proc. IEEE Int. Conf. Acoustics, Speech, and Signal Processing, 1997, pp. 1503âÃâ¬Ãâ1506.
- B. Milner and X. Shao, âÃâ¬ÃÅPrediction of fundamental frequency and voicing from mel frequency cepstral coefficients for unconstrained speech reconstruction,âÃâ¬Ã in proc. of international conference IEEE Trans. Audio, Speech, Lang. Process., vol. 15, no. 1, pp. 24âÃâ¬Ãâ33, Jan. 2007.
- Christian Blum, âÃâ¬ÃÅAnt colony optimization: Introduction and recent trendsâÃâ¬ÃÂ, in Elsevier journal, Physics of Life Reviews 2 (2005) 353âÃâ¬Ãâ373.
- Chulhee Lee, Donghoon Hyun, Euisun Choi, Jinwook Go, and Chungyong Lee, âÃâ¬ÃÅOptimizing Feature Extraction for Speech RecognitionâÃâ¬ÃÂ, IEEE Trans. Audio, Speech, Lang. Process., Vol. 11, No. 1, pp.80, January 2003.
- D. R. Sanand and S. Umesh, âÃâ¬ÃÅVTLN Using Analytically Determined Linear Transformation on Conventional MFCCâÃâ¬ÃÂ,IEEE Transactions on Speech and Audio Processing, VOL. 20, NO. 5, pp.1573, JULY 2012.
- Daniele Giacobello, MadsGrÃÆæsbÃÆøll Christensen, Manohar N. Murthi, SÃÆørenHoldt Jensen and Marc Moonen, âÃâ¬ÃÅ Sparse Linear Prediction and Its Applications to Speech ProcessingâÃâ¬ÃÂ, IEEE Transactions on Speech and Audio Processing, Vol. 20, No. 5, pp.1644, July 2012.
- DimitriosDimitriadis, Petros Maragos and Alexandros Potamianos, âÃâ¬ÃÅOn the Effects of Filter bank Design and Energy Computation on Robust Speech RecognitionâÃâ¬ÃÂ,IEEE Transactions on Audio, Speech and Language Processing, Vol. 19, No. 6, August 2011.
- Dipmoy Gupta, RadhaMounima C. NavyaManjunath, Manoj PB , âÃâ¬ÃÅ Isolated Word Speech Recognition Using Vector Quantization (VQ âÃâ¬ÃÅ,in International Journal of Advanced Research in Computer Science and Software Engineering, Volume 2, Issue 5, May 2012 ISSN: 2277 128X, pp. 164-168.
- D. Giacobello, M. G. Christensen, M. N. Murthi, S. H. Jensen, and M. Moonen, âÃâ¬ÃÅEnhancing sparsity in linear prediction of speech by iteratively reweighted 1-norm minimization,âÃâ¬Ã in Proc. IEEE Int. Conf. Acoust., Speech, Signal Process., 2010, pp. 4650âÃâ¬Ãâ 4653.
- D. Chazan, R. Hoory, G. Cohen, and M. Zibulski, âÃâ¬ÃÅSpeech reconstruction from mel frequency cepstral coefficients and pitch frequency,âÃâ¬Ã in Proc. ICASSP, 2000, vol. 3, pp. 1299âÃâ¬Ãâ1302.
|