International Journal of Innovative Research in Computer and Communication Engineering
ISSN ONLINE(2320-9801) PRINT (2320-9798)
ISSN ONLINE(2320-9801) PRINT (2320-9798)
Boney cherian1, E.Hari Prasath2, Rahul P3
|
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Innovative Research in Computer and Communication Engineering
Personalized web search has denoted its success in improving the grade of different search services on the internet. The proof reveal that user’s disinclination to tell their personal information during search has becomes a major barricade for the wide build-up of pws.In this we study private safety in pws applications that representation user desire as hierarchical user profiles. Generalize profile by queries while reference user specified a private requirement using a pws framework ups. Two predictive metrics utility of personalization and the privacy risk are used for build – up of profile. For generalization we use greedy DP and greedy IL algorithm. The innovative outcome tells that greedy IL obviously outperforms greedy DP in terms of efficiency.
Keywords |
||||||
| Personalized web search, utility, risk, profile | ||||||
INTRODUCTION |
||||||
| The web search engine has overlong become the most main gateway for common people looking for useful data on the web. However users might occurrence non success when search engines return unrelated results that do not meet their real goal. Such unimportance is mostly due to the huge variety of users’ conditions and environment as well as the equivocation of texts. Personalised web search provides better search results, which are used for individual user needs. For this the user information has to be collected and analysed to figure out the user intention behind the issued query. | ||||||
| The results of PWS can be grouped into two types, namely click-log-based methods and profile-based ones. The clicklog- based method increments the bias of the clicked page in the history. This strategy works consistently and considerably well, but it requires repetition of the search queries by the users, which limits its applicability. But profilebased upper hand over click-log-based because of the usage of complicated user interest models generated from user profiling techniques. Profile based methods are generally effective but are reported to be unstable under some circumstances. | ||||||
| Both the two methods have its own advantages and disadvantages, but the profile based technique has demonstrated more effectiveness in improving the web search quality. It is achieved by filing the personal and behavioural details of the users, which is usually gathered from query history, click through data, browsing history, bookmarks, user documents and so on. Unfortunately such user data reveals a small picture of the user's personal life. Many privacy issues will rise from such insecurity of private data. So the privacy concerns have become the major barriers for wide flourishment of PWS services. | ||||||
1.1motivations: |
||||||
| In order to provide user privacy in profile based PWS, researcher’s have to consider two opposing properties .On the one hand, they try to increase the search quality with the help of user profile while on the other side they need to hide the privacy contents in the user profile .Some of the studies show that the users are willing to compromise privacy for better search results. In an ideal case, we can have smooth search results by using a small portion of user profile, namely a generalized profile. In general there is a trade-off between the search quality and level of privacy protection. | ||||||
| 1. The customization of privacy requirements do not take into account in existing system. | ||||||
| The user privacy to be overprotected while others insufficiently protected. For example the sensitive topics are detected using an absolute metrics called surprisal based on information theory, assuming that the less user interest document support more sensitive. This assumption can be doubted with a simple counterexample: if a user has large documents about sex the surprisal of this tittle led to a conclusion that sex is very general and not sensitive, the truth is opposite. The prior work can effectively address individual privacy needs during the generalization. | ||||||
| 2. While creating personalized search results many personalization techniques require muliterative user interactions. Ranks scoring, average ranks are usually refine the search results with some metrics which require multiple user interaction. This paradigm is, however, infeasible for runtime profiling as it will not only pose too much risk of privacy breach, but also demand prohibitive processing time for profiling. To measure the search quality and risk after personalization we need predictive metrics, without incurring iterative user interaction | ||||||
II. RELATED WORK |
||||||
| Personalized search could be promising thanks to improve search quality. This approach needs users to grant the server full access to non-public data on web that violates users’ privacy. During this paper, investigated the practicableness of achieving a balance between users’ privacy and search quality. First, associate algorithmic rule is provided to the user for collection, summarizing, and organizing their personal data into a hierarchal user profile, wherever general terms area unit stratified to higher levels than specific terms. Through this profile, user’s management what portion of their non-public data is exposed to the server by adjusting the min Detail threshold. an extra privacy live, exp Ratio, is projected to estimate the quantity of privacy is exposed with the desired min Detail price. This work targets at bridging the conflict desires of personalization and privacy protection, and provides an answer wherever users decide their own privacy settings supported a structured user profile. This edges the user within the following ways that. Offers a ascendable thanks to mechanically build a hierarchal user profile on the shopper facet. It’s not realistic to want that each user to specify their personal interests expressly and clearly. Thus, associate algorithmic rule is enforced to mechanically collect personal data that indicates associate implicit goal or intent. The user profile is made hierarchically so the higher-level interests area unit a lot of general, and therefore the lower-level interest’s area unit a lot of specific. During this approach, an expensive pool of profile sources is explored as well as browsing histories, emails and private documents. | ||||||
| A greedy formula may be a mathematical operation that recursively constructs a collection of objects from the tiniest potential constituent components. Greedy algorithms rummage around for easy, easy-to-implement solutions to advanced, multi-step issues by deciding that next step can offer the foremost obvious profit. Such algorithms area unit known as greedy as a result of whereas the best resolution to every smaller instance can offer an instantaneous output, the formula doesn’t take into account the larger downside as a full. Once a choice has been created, it's ne'er reconsidered. | ||||||
III. PROPOSED SYSTEM |
||||||
| A privacy-preserving personalized web search framework UPS is proposed, which can generalize profiles for each query according to user-specified privacy requirements. UPS could potentially be adopted by any PWS that captures user profile in a hierarchical taxonomy. The framework allowed user a specify customized privacy requirements via the hierarchical profile Relying on the definition of two conflicting metrics, namely personalization utility and privacy risk, for hierarchical user profile, Formulate the problem of privacy-preserving personalized search as Risk Profile generalization. Develop two simple but effective generalization algorithms, GreedyDP and GreedyIL. In GreedyDP uses the discriminating power and GreedyIL uses the information loss to support profiling. While the former tries to maximize the discriminating power (DP), the latter attempts to minimize the information loss (IL). By exploiting a number of heuristics, GreedyIL outperforms GreedyDP significantly. | ||||||
Design Considerations |
||||||
| • Construction of user profile | ||||||
| • Privacy Requirement customization | ||||||
| • Query topic matching | ||||||
| • Generalization using greedyDP and GreedyIL | ||||||
| • Performance evaluation | ||||||
| 3.1 Construction of user profile | ||||||
| The first step of the offline process is to make the first user profile in a very topic hierarchy H that reveals user interests. It presumptuous the user’s preferences area unit portrayed in a very set of plain text documents, denoted by D. To construct the profile, we have a tendency to take the subsequent steps: | ||||||
| 1 notice the several topic in R for each document d ∈ D. Thus, the preference document set D is reworked into a subject set T | ||||||
| 2 Construct the profile H as a topic-path trie with T, i.e., H = trie(T). | ||||||
| 3.2 Privacy Requirement customization | ||||||
| This procedure 1st requests the user to specify a sensitive-node set S ⊂ H, and therefore the various sensitivity worth sen(s) > zero for every topic s ∈ S. Next, {the cost|the worth|the price} layer of the profile is generated by computing the price value of every node t ∈ H as follows: | ||||||
| 1. For each sensitive-node, cost(t) = sen(t); | ||||||
| 2. For each non sensitive leaf node, cost(t) = 0; | ||||||
| 3. For each non sensitive internal node, cost(t) is recursively given by following equation during a bottom-up manner: | ||||||
| 3.3 Query topic matching | ||||||
| Given query q, the needs of query-topic mapping are 1) to cipher a nonmoving sub tree of H, that is termed a seed profile, in order that all topics relevant to q are contained in it; and 2) to get the preference values between q and every one topic in H. This procedure is performed within the following steps: | ||||||
| 1. Notice the topics in R that are relevant to q. It develops an efficient method to compute the relevance of all topics in R with q. These values is accustomed acquire a collection of non overlapping relevant topics denoted by T (q), specifically the relevant set. Need these topics to be nonoverlapping in order that T (q), beside all their antecedent nodes in R, comprises a query-relevant trie denoted as R (q). Apparently, T (q) is the leaf nodes of R (q). Note that R (q) is typically low fraction of R. | ||||||
| 2.Overlap R(q) with H to get the seed profile G0, that is additionally a nonmoving sub tree of H. for instance, by applying the mapping procedure on question “Eagles,” which can be obtained a relevant set T(Eagles). Overlapping the sample profile with its query-relevant trie R (Eagles) provides the seed profile Gb, whose size is considerably reduced, compared to the first profile. | ||||||
| The leaves of the seed profile G0 (generated from the second step) type a very attention-grabbing node set—the overlap between set T (q) and H. It denoted by TH (q), and clearly we've got TH (q) ⊂ T (q). Then, the preference worth of a subject t ∈ H is computed as following: | ||||||
| 1. If t may be a leaf node and t ∈TH (q), its preference prefH (t, q) is about to the long-run user support supH (q), which may be obtained directly from the user profile. | ||||||
| 2. If t may be a leaf node and t ∉TH (q), prefH (t, q) = 0. | ||||||
| 3. Otherwise, t isn't a leaf node. The preference worth of topic t is recursively aggregative from its child topics. Finally, it's simple to get the normalized preference for every t ∈ H. | ||||||
| 3.4 Generalization mistreatment greedyDP and GreedyIL | ||||||
| GreedyDP: Given the complexness of the matter, a additional sensible answer would be a near-optimal greedy algorithmic rule. Here introduce associate operator referred to as prune-leaf, which indicates the removal of a leaf topic t from a profile. Formally, which might denoted by the method of pruning leaf t from Gi to get Gi+1. Obviously, the optimum profile G* may be generated with a finite-length transitive closure of prune-leaf. | ||||||
| The first greedy algorithmic rule GreedyDP works in an exceedingly bottom up manner. Ranging from G0, in each ith iteration, GreedyDP chooses a leaf topic t ∈TGi (q) for pruning, attempting to maximize the utility of the output of this iteration, particularly Gi+1. throughout the iterations, It conjointly maintain a best profile so-far, that indicates the Gi+1 having the very best discriminating power whereas satisfying the δ -risk constraint. The unvaried method terminates once the profile is generalized to a root-topic. The best-profile-so-far are going to be the ultimate result (G*) of the algorithmic rule. The most downside of GreedyDP is that it needs recomputation of all candidate profiles (together with their discriminating power and privacy risk) generated from makes an attempt of prune-leaf on all t ∈TGi (q). This causes important memory needs and process value. | ||||||
| In greedy IL algorithmic program improves the potency of the generalization victimization heuristics supported many findings. One vital finding is that any prune-leaf operation reduces the discriminating power of the profile. In alternative words, the stateless person displays monotonicity by prune-leaf. Considering operation within the ith iteration, maximizing discriminative power is akin to minimizing the incurred info loss that is outlined as discriminative power. The higher than finding motivates United States to keep up a priority queue of candidate pruneleaf operators in drizzling order of the data loss caused by the operator. Specifically, every candidate operator within the queue may be a tuple. This queue, denoted by alphabetic character, allows quick retrieval of the simplest so- so much candidate operator. | ||||||
| The second finding is that the computation of IL is simplified to the analysis. The explanation is that, the second term (TS (q; G)) remains unchanged for any pruning operations till one leaf is left (in such case the sole selection for pruning is that the single leaf itself). What is more, take into account 2 potential cases (C1) t may be a node with no siblings, and (C2) t may be a node with siblings. The case C1 is straightforward to handle. However, the analysis of IL just in case C2 needs introducing a shadow relative of t. when if we tend to plan to prune t, we tend to truly merge t into shadow to get a brand new shadow leaf shadow0, beside the preference of t. The third finding is that, just in case C1 delineated on top of, prune-leaf solely operates on one topic t. Thus, it doesn't impact the IL of alternative candidate operators in Q. whereas just in case C2, pruning t incurs recomputation of the preference values of its relation nodes. GreedyIL traces the data loss rather than the discriminating power. This protects lots of procedure value. Within the worst case, all topics within the seed profile have relation nodes, then GreedyIL has procedure quality of O (|G0| * |TG0(q)|). However, this can be extraordinarily rare in observe. Therefore, GreedyIL is anticipated to considerably beat out GreedyDP.. | ||||||
3.5 Performance evaluation |
||||||
| The purpose of the utility metric is to predict the search Quality (in revealing the user’s intention) of the question q on a generalized profile G. the rationale for not measure the search quality directly is as a result of search quality depends mostly on the implementation of PWS computer programmer, that is difficult to predict. Additionally, it's too dearlywon to solicit user feedback on search results. or else, we have a tendency to remodel the utility prediction drawback to the estimation of the discriminating power of a given question Q on a profile G. the primary part of the utility metric referred to as Profile coarseness (PG), that is that the KL-Divergence between the chance distributions of the subject domain with and while not hq; Gi exposed. That is | ||||||
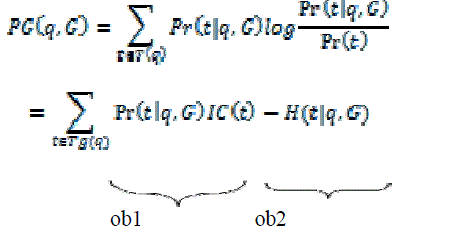 |
||||||
| Where the chance Pr (t | q; G) (referred to as normalized preference) is computed. It will justify this element will capture the primary 2 observations we tend to projected on top of, by rotten PG(q; G) into 2 terms that respect ob1 and ob2 singly. The primary term is thought-about because the expected IC of topics in TG (q). The other quantifies the uncertainty of the distribution of the user preference on topics in TG (q). Such uncertainty is sculptural as a penalty to the utility. The discriminating power is expressed as a normalized combination of PG (q; G) and TS (q; G) as follows: | ||||||
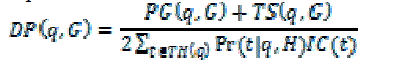 |
||||||
| Then, the personalization utility is outlined because the gain of discriminating power achieved by exposing profile G in conjunction with question alphabetic character, i.e., | ||||||
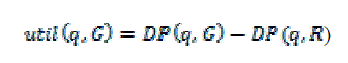 |
||||||
| When exposing G the privacy risk is outlined because the total sensitivity contained in it.The sensitive node is cropped and its antecedent node area unit preserved throughout the generalization. To evaluate the danger of exposing the ancestors. | ||||||
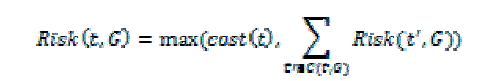 |
||||||
| Normalized risk may be obtained by dividing the unnormalized risk of the basis node with the whole sensitivity | ||||||
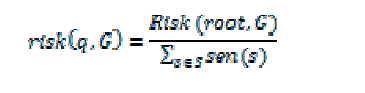 |
||||||
IV. RESULT |
||||||
| privacy-preserving personalised net search framework user customizable privacy-preserving search, which may generalize profiles for every question in step with user-specified privacy needs. GreedyDP and greedyIL square measure used for generalize profiles. Discriminating power is employed in greedyDP and knowledge loss is employed in greedyIL. When the discriminating power will increase info loss can decreases. GreedyDP have high discriminating power than greedyIL. GreedyIL have less risk compare to greedyDP. The average time for greedyIL is a smaller amount than greedyDP. So greedyIL is healthier than greedyDP. | ||||||
| In the above figure 4.1 shows the graph examination the discriminating power for greedyDP and greedyIL. The x axis denoted range of iteration and y axis denoted the discriminating power. GreedyIL have high discriminating power whereas scrutiny with greedyDP. In the figure 4.2 shows the graph scrutiny the danger occurring between greedyDP and greedyIL The x axis denoted range of iteration and y axis denoted risk. The greedyDP have high risk than greedyIL. So greedyIL is healthier than greedyDP | ||||||
| In the figure 4.3 shows the graph comparison the common time for greedyDP and greedyIL. The x axis denoted range of iteration and y axis denoted average time. The greedyDP have high average time whereas comparison with greedyIL. The greedyIL is best than greedyDP. | ||||||
V. CONCLUSION AND FUTURE WORK |
||||||
| This paper conferred a client-side privacy protection framework known as UPS for customized net search. UPS could doubtless be adopted by any PWS that captures user profiles in an exceedingly graded taxonomy. The framework allowed users to specify bespoken privacy needs via the graded profiles. It projected 2 greedy algorithms, specifically GreedyDP and GreedyIL, for the generalization. The experimental results disclosed that UPS might reach quality search results whereas conserving user’s bespoken privacy needs. The results additionally confirmed the effectiveness and potency of our resolution. This method is lacks find the richer relationship among topics (e.g., cliquishness, sequentially, and so on). Effective personalization of knowledge access involves 2 vital challenges: accurately characteristic the user context and organizing the knowledge in such some way that matches the actual context. To beat this problems and so as to scale back time intense of method, in our projected system proposing the metaphysics User Profiles and higher metrics to predict the performance of UPS. Metaphysics is formal naming and definition of the kinds and properties and interrelatedness of the entities that basically or essentially exist for a specific domain. To overcome this issues and in order to reduce time consuming of process, in our proposed system proposing the Ontological User Profiles and better metrics to predict the performance of UPS. Ontology is formal naming and definition of the types and properties and interrelationship of the entities that really or fundamentally exist for a particular domain. | ||||||
Figures at a glance |
||||||
|
||||||


