International Journal of Innovative Research in Computer and Communication Engineering
ISSN ONLINE(2320-9801) PRINT (2320-9798)
ISSN ONLINE(2320-9801) PRINT (2320-9798)
Satya Ranjan Dash1 and Satchidananda Dehuri2
|
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Innovative Research in Computer and Communication Engineering
Post Operative patient dataset is a real world problem obtained from the UCI KDD archive which is used for our classification problem. In this paper different classification techniques such as Bayesian Classification, classification by Decision Tree Induction of data mining and also classification techniques related to fuzzy concepts of soft computing is used for implementation of our dataset. The parameters used to comparison of different algorithms are RMSE, ROC Area, MAE, Kappa Statistics, time taken to build the model, Relative Absolute Error, Root Relative Squared Error, and the percentage value of classifying instances.
Keywords |
||||||||
| feature extraction, LPC, MFCC, VQ, Gujarati database | ||||||||
I. INTRODUCTION |
||||||||
| The Speech recognition is the analytic subject of speech processing in machines. Human speech recognition is thousands of year’s old and known better as automatic speech recognition (ASR). Speech recognition systems have been developed for the languages like Hindi [1] [2], Malayalam [3] [4], Tamil [5], Marathi [6], Telugu [7], Panjabi [8], Urdu [9], etc…, in India. Isolated speech recognition using MATLAB® is done for Gujarati words. In relative work [10] Dr. C. K. Kumbharana has completed Gujarati word detection for “àêÃâ¢, àêÃÅ¡, àêð, àêä and àêî”, using MFCC function. | ||||||||
| The study is performed with two different feature extraction algorithms and used training and testing data from distinct words like àêÃâ àêà(Eight), àêäàëÃÂàêðàêã (Three) and àêÃâàëÃÂàêÃÅàêðàêäàëÃ⬠(Gujaraati), etc. Each speaker had spoken the 10 words with 0 to 10 numbers and some word with 5 utterances of each. So, for four speakers, total 200 utterances of the words were recorded. The isolated words in Gujarati were recorded using built in microphone of laptop using the RecordPad Software [11] and stored in .wav format. The data had been recorded in closed rooms where background noise was present. This kind of recording of the speech data in such noisy environment will be useful in robust automatic speech recognition system. | ||||||||
| The paper is divided into five sections. Section I gives introduction. The feature extraction using MFCC and LPC is describes in Section II and Section III, respectively. The results are analysed in Section IV followed by conclusion and future work in Section V. | ||||||||
II. FEATURE EXTRACTION USING MFCC |
||||||||
| Mel Frequency Cepstral Coefficient (MFCC) was introduced by Davis and Mermelstein in the 1980 AD. It is very common and one of the best method for feature extraction method especially for automatic speech and speaker recognition system. An application of hand gesture recognition, MFCC was used as feature extractor by converting input image into 1D signal with SVM classifier [12]. The MFCC coefficients can be used as audio classification features to improve the classification accuracy, is used for the music features, and then BPNN algorithm recognizes the music classes [13]. | ||||||||
| Before introduction of MFCCs, Linear Prediction Coefficients (LPCs) and Linear Prediction Cepstral Coefficients (LPCCs) and were the main feature type for ASR [14]. MFCC is used in speaker verification with speaker information like, contents and channels [15]. MFCCs are a feature widely used in automatic speech and speaker recognition. There is computation for extracting the cepstral features parameters from the Mel scaling frequency domain. The steps of MFCC are given bellows, | ||||||||
| As shown in figure-1, the signal is passed through very first stage of emphasizes which will increase the energy of the signal at higher frequency to compensate the high-frequency part that was suppressed during the sound production mechanism of humans. Now, the boosted signal is segmented into frames of 20~30 ms of the frame size with overlap of 1/3~1/2. Here, the sample rate is 8 kHz and the frame size is 256 sample points are used, then the frame duration is 256/8000 = 0.032 sec = 32ms. Each frame will be multiplied with a hamming window in order to keep the continuity of the first and the last points in the frame. MATLAB® provides the command for generating the curve of a Hamming window, also. There is FFT performed to obtain the magnitude frequency response of each frame which is assumed of periodic within frame. The triangular bandpass filters are used to extract an envelope like features. The multiple the magnitude frequency response by a set of triangular bandpass filters to get the log energy of each triangular bandpass filter which will give nonlinear perception for different tones or pitch of voice signal. The Mel frequency M(F) related to the common linear frequency f is by the following equation[16]: | ||||||||
| M(F) = 1125 * ln (1 + f / 700) … … … (1) | ||||||||
| Then Discrete Cosine Transform (DCT) is applied on the log energy to have different mel-scale cepstral coefficients. The DCT converts the signal from frequency domain into a time domain. Because, the features are similar to cepstrum, it is referred to as the mel-scale cepstral coefficients. MFCC can be used as the feature for speech recognition. For better performance can generated by adding the log energy and perform delta operation. As new features in MFCC, Delta cepstrum can be generated which has advantage in the time derivatives of energy of signal. It can use for finding the velocity and acceleration of energy with MFCC. MFCC base speaker recognition system in MATLAB® can significantly increase the accuracy rate of training and recognition, and reduce the data required by calculation at higher recognition rate [17]. | ||||||||
III. FEATURE EXTRACTION USING LPC |
||||||||
| Linear predictive coding (LPC) method was developed in the 1960s by [18] and being used for speech vocal tracing because it represents vocal tract parameters and the data size are very suitable for speech compression. [19]. In this paper, a modified LPC coefficients approach is used for speech processing for representing the spectral envelope of speech in compressed form. This method gives encoding good quality speech at low bit rate and provides accurate estimates of speech parameters by describing the intensity, the residue signal. The information can be stored or transmitted somewhere else. A dialect-independent wavelet transform (WT) is based Arabic digits classier is proposed wavelet transformed with the LPC and the classier by probabilistic neural network (PNN) [20]. There was speaker’s classification between male and female using nearest neighbour method, calculating Euclidean distance from the Mean value of Males and Females of the generated mean. There are 13 MFCCs and 13 LPCs coefficients are computed for Audio portion is extracted from Indian video songs [21]. | ||||||||
| There are basic four steps of LPC processor, Pre-emphasis where the digitized speech signal is flatten to make less susceptible to finite precision effects signal processing. In second step of frame blocking, the output signal is blocked into frames of N samples, with adjacent frames separated by no. of M samples. In Windowing, there is to window each individual frame so as to minimize the signal discontinuities at the starting and ending of each frame, same as in MFCC. Autocorrelation Analysis will auto correlate each frame of windowed signal in order to give highest autocorrelation value. In final step of LPC Analysis converts each frame of p + 1 autocorrelations into LPC parameter set by using Durbin’s method. In equation, each sample of the signal x(n) is expressed as a linear combination of the previous samples x( n − i )it is called linear predictive coding [22]. Here, ai are the predictor coefficients. | ||||||||
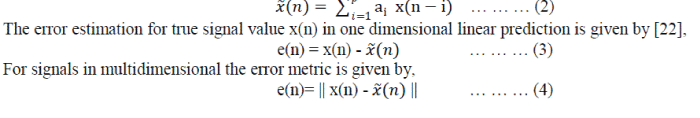 |
||||||||
| LPC and MFCCs coefficients combined can use for dynamic or runtime feature extraction. These both combine can use as feature vector for Emotions of speaker identified like Angry, Boredom, neutral, happy and sad [23]. The Hindi alphabet is done for emotion identification using syllables occur in the pattern Consonant Vowel Consonant (CO3VCO3) [24]. | ||||||||
IV. RESULT ANALYSIS |
||||||||
| Vector quantization (VQ) is used for comparing the trained data with new entered input data. It is a classical quantization technique that allows the modeling of probability density functions by the distribution of vectors. It divides a large set of points called vectors into groups having approximately the same number of points closest to them. The density matching property of VQ is powerful for identifying the density of large and high-dimensioned data [25]. All data points are represented by the index of their closest centroid which can be used for lossy data correction and density estimation. Vector quantization is the self organizing map model. | ||||||||
| Using MFCC and LPC Features are extracted for the Gujarati words. The training data sets for the vector quantization are obtained by recording utterances of Gujarati words. The entered data are compared with already stored datasets. The comparison of both algorithms for three words is given in below charts. | ||||||||
| The recognition accuracy is achieved by LPC is above 85%, shown in chart-1. The recognition accuracy is achieved by MFCC is more above 95%, shown in Chart-2. | ||||||||
| So, MFCC can bring better feature for Gujarati language tutor application in speech recognition. The input speech that matches trained database is converted into related text, and results are shown below figure 2 (a) describes digit 8,(b) describes digit 3, (c) describes word “Gujarati”,(d) describes word “attack”, (e) describes words “Gujarati” and “Ahmadabad”, (f) describes words ”attack” and “Hiral” (a name) in Gujarati language. | ||||||||
V. CONCLUSION AND FUTURE WORK |
||||||||
| The approach is to implement for isolated speech recognition system for Gujarati language. The MFCC and LPC are used as speech feature extractor. The algorithms are followed by VQ method for testing, helps to conclude that MFCC is more accurate feature extractor for verity speech signals. The present work was limited to phonemes of Gujarati only. The further study can be done for continuous speech recognition using MFCC Features extraction algorithm and Hidden Markov Model (HMM) for testing and modeling purpose. The very large vocabulary speech recognition (VLSR) using MFCC with PLP Features extraction algorithm and HMM combined with Artificial Neural network (ANN) for better classification. | ||||||||
ACKNOWLEDGMENT |
||||||||
| A Special thanks to Prof. Dr. Mayur M.Vegad of BVM engineering college, who insist a lot towards sincere and preeminent work. | ||||||||
Figures at a glance |
||||||||
|
||||||||
References |
||||||||
|



