Keywords
|
| Feature extraction, forgered image detection, illuminant estimator, kNN classifier, machine learning |
INTRODUCTION
|
| In this digital age, images reach everywhere at a very high speed and frequency. With the availiability of low cost digital cameras, high speed internet facilities and high quality photo editing softwares, it is easier to manipulate digital images. Digital Image Forensics is still emerging research area that aims at revealing all the underlying facts about an image. In this paper, a forensic technique that focus on inconsistencies in the illumination color of images. |
| Before thinking about the actions to be performed in a questionable image, one must be able to detect whether there is any manipulation performed in that image [1].Various forgery detection techniques are available today. |
| Some of the image manipulation techniques are copy move, splicing, retouching etc. Among these image composition or splicing is most common. Image splicing is a technique of combining two or more images to create a fake image. An example for this is shown in figure 1.Here the images of two girls are combined to create a single image. The manipulation performed here is harmless. But in certain cases this type of manipulation will create serious issues. |
 |
| There are various techniques available for forgery detection. Among these illumination inconsistencies is the effective technique for splicing detection. This is because the proper adjustment of all the illumination conditions is hard to achieve and is time consuming when creating a fake image. The gray world illuminant estimator is used to create an intermediate representation called illuminant map. Then create all possible face pairs for each of the image. Then classify the illumination of each face pairs as either consistent or inconsistent. If any of the face pair is illuminated inconsistently then tag the image as manipulated. |
METHOD OVERVIEW
|
|
METHOD OVERVIEW
|
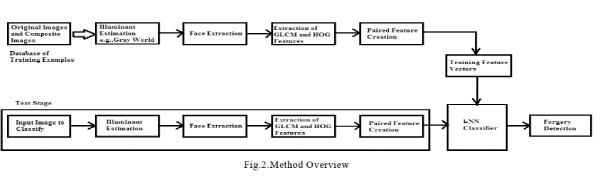 |
| Figure 2 shows the diagrammatic representation of the method. This method consists of five main components. |
| A) Dense Local Illuminant Estimation : The input image is segmented into regions of similar color i.e., superpixels. The illuminant color is estimated for each of the segment and a new image is created by recoloring each of the superpixel with the extracted illuminant color. The resulting intermediate representation is called illuminant map. |
| B) |
| C) Face Extraction : Each faces in the input image is extracted in this step. Face extraction can be performed using automatic or semiautomatic method. Here semiautomatic face detection is used. This is the only step where human interaction is required. The operator sets bounding box around each of the face in the image and crop each bounding box out of the illuminant map to obtain the illuminant estimate of the face region. |
| D) Computation of Illuminant Features : Both texture and edge based features are computed for all face regions. The texture features are computed using Gray Level Co-occurrence Matrix and edge features are computed using HOGedge. |
| E) Paired Feature Creation : Create all possible face pairs in an image to check whether any one of the face pair is inconsistently illuminated. Then construct joint feature vectors of all possible face pairs. |
| F) Classification : A machine learning approach is used to automatically classify the feature vectors. The kNN classifier is used for classification purpose. An image is considered as forgery if any one of the face pair in the image is classified as inconsistently illuminated. |
METHOD DETAILS
|
| The detailed description of each of the components is given below: |
| A. Dense Local Illuminant Estimation |
| The dense set of localized illuminant color is estimated by subdividing the input image into regions of approximately constant chromaticity [2]. These regions are called superpixels. Then illuminant color is estimated for each of the superpixel. The illuminant estimator used is generalized gray world illuminant estimator. |
| Generalized Gray World Estimate : In gray world average color of a scene is considered as gray. Any deviation from this assumption is due to the illuminant. |
| The color of the illuminant e is estimated as |
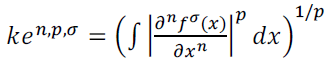 |
| Integration is performed over all the pixels in the image where x denote pixel co-ordinate, k is scaling factor, ∂ is differential operator, fσ(x) is the observed intensity at x and σ is the Gaussian kernel. Then recolor each of the superpixels with the estimated illuminant color. |
| In this equations three parameters are incorporated |
| • Derivative order n : The absolute value of the sum of derivatives of the image is considered instead of taking the average of the illuminants. |
| • Minkowski norm P: Greater robustness can be achieved by computing the P-th Minkowski norm of intensity values. |
| • Gaussian smoothing σ: Smooth the image prior to processing with a Gaussian kernel of standard deviation σ to reduce image noise. |
| B. Face Extraction |
| The illuminant color estimation is error prone and is affected by different materials in the scene. Local illuminant estimates are most discriminative when comparing objects of similar material. Therefore here consider the illuminant of each of the faces in the image [3].It can be performed either in automatic or semiautomatic method. Here semiautomatic face detection is used to avoid false detection of faces. |
| It is the only step where a human operator is required to draw bounding boxes around each of the faces in the image and crop the bounding boxes out of the illuminant map to obtain the illuminant estimates of only the face region. |
 |
| Figure 3 shows an original image and its gray world map .The gray world illuminant map for the two faces has the similar values. |
| C. Computation of Illuminant Features |
| Extraction is a reduction process in which the input data is transformed into a reduced representation. This transformation of input data into a set of features is called feature extraction. Both texture based and edge based features are extracted from each of the faces in the image. Texture feature extraction is based on Grey Level Cooccurrence Matrix (GLCM) and edge information is provided by a new feature descriptor called HOGedge. |
| Extraction of texture information |
| The Grey Level Co-occurrence Matrix, GLCM also called Gray Tone Spatial Dependency Matrix gives information about the occurrence of different combinations of pixel brightness values in a gray scale image.GLCM is a statistical method of by considering the spatial relationship of pixels. That means GLCM calculates how a pixel with gray level value i occur horizontally, vertically or diagonally to a nearby pixel with value j [4]. |
| The gray-level co-occurrence matrix shows certain properties about the spatial relationships of the gray levels in the texture image. |
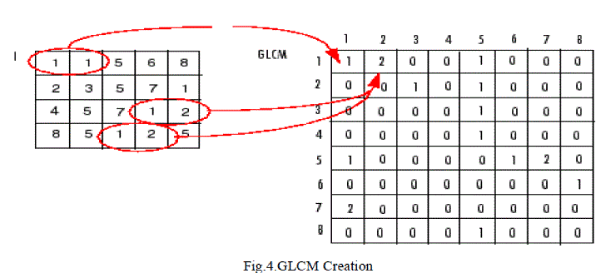 |
| Figure 4 shows the process used to create GLCM. In the output GLCM, the value at the position (1,1) is 1 because there is only one instance in the input image where two adjacent horizontal pixels have the values 1 and 1, respectively. The value is 2 in the position (1,2) in the GLCM because there are two instances where two adjacent horizontal pixels have the values 1 and 2.The value at glcm(1,3) is 0 because there are no instances of two adjacent horizontal pixels with the values 1 and 3. |
| Extraction of edge points |
| Edge points can be extracted using Canny Edge Detector [5].The statistics of these edges differ in original images and doctored images. These edge discontinuities are characterized by a feature descriptor called HOGedge. |
| At first extract equally distributed edge points and determine the HOG descriptor for each of the edge points. The computed HOG descriptors are summarized in a visual dictionary [6]. The appearance and shape of objects in an image are determined from the distribution of edge directions. Firstly divide the image into small regions called cells and compute local 1-D histogram of each cell. The feature vectors are constructed by combining and contrast-normalizing the histogram of all cells within a spatially large region. |
| D. PAIRED FEATURE CREATION |
| In this step all the face pairs in the image are detected and feature vector of each of the face is concatenated with other face in the pair. The idea behind this is that feature concatenation from two faces is different when one face is original and the other is spliced. If an image contain nf faces (nf ≥ 2), there are (nf (nf -1))/2 possible face pairs. |
| E. CLASSIFICATION |
| In this step illumination for each face pairs are classified as either consistent or inconsistent. If any of the face pair is illuminated inconsistently then tag the image as spliced one. Here classification is performed by k-Nearest Neighbor (kNN) classifier. The classification is machine learning based to improve the detection performance. The classifier stores all the training data and when a new data is given, the classifier look up its k nearest data points and labels the new data to the set that contains majority of its k neighbours. |
CONCLUSION
|
| In this paper a new method for detecting the forgery in digital images using illuminant color estimator has been proposed. Here the illuminant color is estimated by the generalized gray world illuminant estimator. The texture informations are extracted using GLCM and edge point informations are obtained from HOGedge algorithm. Then classification of face pairs are performed using KNN classifier. This method requires only a minimal user interaction and provide a correct statement on the authenticity of the image. |
ACKNOWLEDGMENT
|
| I take this opportunity to express my gratitude to all who have encouraged and helped me throughout the completion of this project. First and foremost, I thank the Lord Almighty for his blessing to complete this project work successfully. |
| I am extremely grateful to Mrs. Ann Jose, for her valuable suggestions and encouragement in completing the project. I would like to express my gratitude towards my parents and project coordinator Mrs. Lekshmi M S (Ilahia college of engineering and Technology) for their kind co-operation and encouragement which help me in completion of this project. |
| My thanks and appreciations also go to my colleague in developing the project and people who have willingly helped me out with their abilities. |
| |
References
|
- A. Rocha, W. Scheirer, T. E. Boult, and S. Goldenstein, “Vision of the unseen: Current trends and challenges in digital image and video forensics,” ACM Comput. Surveys, vol. 43, pp. 1–42, 2011.
- S. Rajapriya, S. Nima Judith Vinmathi, “Detection of Digital Image Forgeries by Illuminant Color Estimation and Classification,” International Journal of Innovative Research in Computer and Communication Engineering, Vol.2, Special Issue 1, March 2014
- C. Riess and E. Angelopoulou, “Scene illumination as an indicator of image manipulation,” Inf. Hiding, vol. 6387, pp. 66– 80, 2010.
- Mryka Hall-Beyar,GLCMTutorial,February 2007 [Online] Available: http://www.fp.ucalgary.ca/mhallbey/tutorial.htm ( February 21, 2007).
- J. Canny, “A computational approach to edge detection,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 8, no. 6, pp. 679–698, Jun. 1986.
- G. Csurka, C. R. Dance, L. Fan, J. Willamowski, and C. Bray, “Visual categorization with bags of keypoints,” in Proc. Workshop on Statistical Learning in Comput. Vision, 2004, pp. 1–8.
- Y. Ostrovsky, P. Cavanagh, and P. Sinha, “Perceiving illumination inconsistencies in scenes,” Perception, vol. 34, no. 11, pp. 1301–1314, 2005.
- S. Gholap and P. K. Bora, “Illuminant colour based image forensics,”in Proc. IEEE Region 10 Conf., 2008, pp. 1–5.
|