Fault dependency (D-matrix) is a systematic diagnostic model which is used to catch the fault system data and its causal relationship at the hierarchical system-level. It consists of dependencies and relationship between observable failure modes and symptoms associated with a system. Proposed system describes an ontology based text mining method for automatically constructing and updating a D-matrix by mining thousands of repair verbatim data (typically written in unstructured text) collected during the diagnosis episodes. First we construct fault diagnosis ontology and then employ text mining method to identify dependencies. The proposed method will be implemented as a prototype tool and validated by using real-life data collected from the automobile domain.
Keywords |
| Fault diagnosis; fault detection; information retrieval; dependency-matrix; text mining. |
INTRODUCTION |
| A complex system interacts with its surrounding to execute a group of tasks by maintaining their performances
within an appropriate vary of tolerances. Any variation of a system from its acceptable performance is treated as a fault.
The fault detection and diagnosis (FDD) is performed to observe the faults and diagnose the root-causes to reduce the
period of time of a system. Because of ever growing technological sophistication that's embedded within the vehicle
systems, for example refined computer code embedded systems [1], diagnostic sensors, internet, etc. the method of
FDD becomes a difficult activity within the event of component or system malfunction. |
| Unsurprisingly, when each diagnosis episode the lessons learnt are maintained in many databases (e.g., the error
codes are hold on in on-board computers of aircrafts or automobiles) to observe and diagnose the faults. One usually
book unbroken diagnosis information comes within the form of unstructured repair verbatim (also brought up as patient
medical records in medical business or service technician records in part, automotive, power plants and producing
industries), that supply rich diagnostic info. It consists of symptoms equivalent to the faulty components, the observed
failure modes, and therefore the repair actions taken to repair the faults. Hundreds of thousands of such repair verbatim
are collected and there is urgent need to mine this information to improve fault diagnosis (FD). However, the
overwhelming size of the repair verbatim information restricts a capability of its effective utilization within the method
of FD. |
| Text mining is gaining a heavy attention because of its ability to mechanically discover the data assets buried in
unstructured text. During this paper, we tend to propose a text mining method to map the diagnostic info extracted from
the unstructured repair verbatim in a very D-matrix [3]. The D-matrix is one amongst the quality diagnostic models laid
out in IEEE Standard. This framework catches causal connections between symptoms and failure modes in structured
fashion. This framework is called as Dependency or Diagnosis framework (D-matrix). A failure modes contains root
cause of a system and symptoms contains a set of fault codes, diagnostic trouble codes, automated tests, technician
tests, observed symptoms, etc. |
| Typically the process of fault diagnosis begins with the extraction of the error codes that are present in the
system and based on the observed error codes the technicians follow some diagnostic procedure along with their
experience to identify the nature of faults. During FD, different data types are collected, like error codes, diagnostic
trouble codes faulty associated with the target system, repair verbatim, and so on. This collected data is then
transmitted to the database. This data can be mined to construct diagnosis matrix models. Such models can be used
by the technicians and stakeholders to find accuracy of fault detection. |
RELATED WORK |
| This section mainly concentrates on how fault detection and diagnosis (FDD) is done to detect the faults
through D-matrix framework related to the automobile domain. In existing fault models, the knowledge which was
embedded in the unstructured repair verbatim (unstructured text) data have improved the performance of fault
diagnosis by introducing an approach for constructing D-matrices based on an ontology-based text mining
method[1]. |
| In the [11], [12], [13], [4], the limited efforts are done to create a D-matrix by analyzing unstructured repair
verbatim. Recently [16] the tool is proposed which discovers the knowledge from the on-board diagnosis by using
the ontology-based data mining. The onboard diagnosis collects the real time data and integrates onboard ECUs.
This model is assumed to be static and complete. But in real world, due to engineering changes and design, new
vehicle structure and vehicle architecture is launching. The vehicles launch new symptoms and failure modes.
Some of the tools suffer some drawbacks related to the symptoms and fault parts. |
| To develop a D-matrix framework, a method is proposed that analyze the unstructured repair verbatim data by
using ontological text mining methods associated with the multiple systems in parallel. Previously D-matrix
frameworks were constructed manually. So this method overcomes the problems in the real life industry of having
to construct model manually. |
| Traditionally, the D-matrices are constructed by using the knowledge buried in the field failure data. The data
includes historical data, engineering data, and sensory data, error codes [11], [12], [13], [4], [14], [15], but the
authors have not provided any perception for new symptoms and failure modes which are observed for the first
time and their insertion in the D-matrix models. The periodic or prior knowledge is necessary for constructing Dmatrix
fault diagnosis model to make it more accurate. |
| The subject matter expert generally detects the anomalies by manually working and sorting the field failure data
using spreadsheets which is time consuming and labor-intensive process. Therefore a data-driven framework is
develop [2] which automatically detect the unusual activity that leads to fault and saves a significant expert’s time.
This framework is developed so that they could completely work on analyzing anomalies and taking proper
actions. |
| Variation Reduction Adviser (VRA) which is an internal General Motors (GM) system contains information
related to fault occurred in the process, their root cause and possible solutions. An ontology based diagnosis is use
for capturing diagnostic information [3]. But, ontology is restricted to thesaurus consisting of sets of phrases from
the automobile domain. The output is a set of records containing diagnosis information that can be use to form fault
diagnosis model. |
| A maturation approach is proposed in [4] which represent Timed Failure Propagation Graph (TFPG) models.
Here diagnostic period based on standardized diagnostic information to determine statistical inconsistencies
between the problems encountered in process and thus correcting the diagnostic model. This model identifies new
dependency and erroneous dependency. In this approach, diagnostic D-matrix model is map with the Time Failure
Propagation Graph which includes the faulty or false alarms. The authors in [5] addressed a new methodology for
transformer fault diagnosis, which is based on the idea of exchanging information with formal, explicit and
machine accessible descriptions of meaning using the Semantic Web. This ontology model has identified the
necessary facts, reason of fault, repair suggestion and fault source. |
| Further in [6] the researcher worked on developing D-matrices from dissimilar information format and data
sources. The D-matrices is classified based on their data source and the imperfectness of symptoms. They have
considered for both boolean-value and real-valued [0, 1] D-matrices. |
| The fault diagnosis D-matrix models have been used successfully in aerospace industry [9], [10] to identify the
dependencies among failure modes, symptoms, and repair claims by analyzing the structured service manual data. |
PROPOSED WORK |
| Our methodology consists of ontological text mining method. The fault diagnosis ontology is formalized by using
the ontology development methodology. It captures the terms and the relations observed in the automobile fault diagnosis domain. The concepts system, subsystem, and part formalize the main parts that are under focus during fault
diagnosis. The concept FailureMode forms the system level engineering faults observed during the root-cause
investigation, Further, the concept attributes e.g., hasCause (fault cause) capture the domain specific data with the
internal structure of the ontology and a minimal set of attributes are used to formalize the concepts. |
| Mainly our methodology contains two main module namely document pre-processing steps and extraction of
relevant terms with probability calculations involved in ontological text mining method. Figure 1. shows the flow
diagram of the proposed work. |
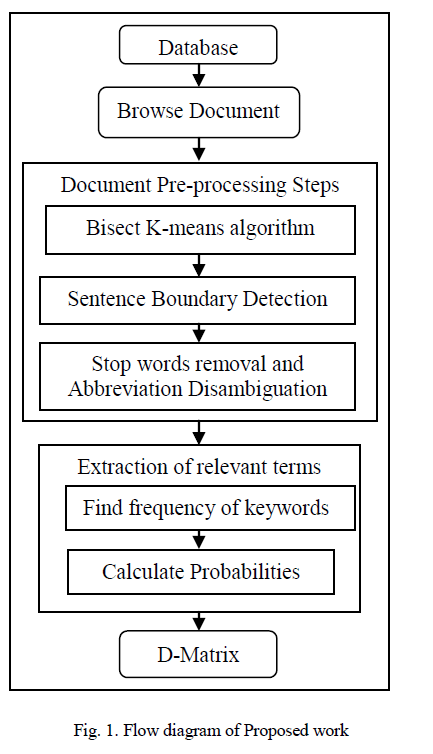 |
Document preprocessing step |
| Due to the many kinds of noises observed in our knowledge the task of identifying the main building blocks of Dmatrix,
like fault components, symptoms, and failure modes becomes a non-trivial exercise. The document
preprocessing helps to remove the data that is irrelevant for our analysis and it provides a selected context [26] for the
consistent and shared interpretation of the data. Initially, the preprocessing steps consist of bisect k-means clustering
algorithm. This algorithm has following steps—the sentence boundary detection (SBD) splits a repair verbatim into
separate sentences, the stop words are deleted to get rid of the non-descriptive terms, and also the lexical matching
identifies the correct that means of abbreviations. The abbreviation disambiguation helps to find out the repeated word
data count. Afterwards the terms from the processed repair verbatim are matched. |
| A typical repair verbatim (VehicleP ck.A for hard startS after codes P0451S...P0452S to found PCM has internal−
ShortFM. Replaced A PCMP and0.3olh is claimedA) consists of multiple components P, symptoms S, failure modes FM,
and actions A and it's necessary to spot the right associations between them for constructing a D-matrix. We have a
tendency to take the perspective that the terms that are showing in an exceedingly same sentence represent high relatedness in comparison with those that are written in separate sentences. In sentence boundary, each repair verbatim
is split into completely different sentences by verifying its starting and end. The task of identifying the sentence
boundary is called as the sentence boundary detection (SBD) in natural language processing. Many approaches have
been projected to identify the SBD and a few crucial instances include Satz system [27], Alembic [28], mxTerninator
[29], and Punkt [30]. The in-house SBD heuristics are developed to see the sentence boundary by mistreatment a
amount as a boundary delimiter and such periods are considered that are used to specify the sentence endings by
successfully ignoring different instances during which they're used to specify the abbreviations. |
| Having split every repair verbatim, the non-descriptive stop words (for example, a, an, the), that don't seem to be
member of the critical component, symptom, or failure mode phrases area unit deleted to reduce the noise. In our data,
some abbreviations, like Abbri, have different meanings based on the context in which they are used, for example, TPS:
Tire Pressure Sensor or Tank Pressure Sensor and it is difficult to identify their correct meaning before constructing the
D-matrices with the terms. In literature survey, different approaches have been proposed to handle the abbreviation
disambiguation problem, for example, [31]–[33] either by using the Naive Bayes, or decision trees, or Support Vector
Machines algorithms. |
Extraction of relevant terms |
| After the preprocessing steps, the critical terms which are useful for constructing D-matrix, i.e., symptoms and
failure modes are extracted by using the extraction of relevant terms. Initially, the relationship between the relevant
symptom-failure mode pairs that seems to be causal is identified to make sure that only the correct pairs are extracted.
The existing approaches [34] for frequent item sets mining ignores the order during which the term phrases are
recorded in documents, but we should maintain such ordering to grasp however the fault identification is performed.
The frequently occurring terms i.e. fault parts are considered as keywords/constant in fields of symptoms, failure
modes and repair action. The number of such keywords in symptoms, failure modes and repair action is calculated for
finding frequency. The frequency is found on the basis of the maximum occurrence of the fault part in the repair data. |
| The contextual information i.e., parts, symptoms, failure mode and actions are used to estimate the conditional
probabilities. As the D-matrix catch component and system level dependencies between a single and multiple failure
modes with a single and multiple symptoms (a set of fault codes, observed symptoms, etc.) in a structured way. Using
bayes theorem, these dependencies among failure modes (f1, f2, etc.) in parts (p1, p2, etc.) and symptoms (s1,s2, etc.)
allow us to state a set of failure modes causing symptoms. The causal weights (d11, d12, etc.) are contained at the
intersection of a row and a column indicates a probability of detection. In the binary D-matrix, all the probabilities have
a value of either 0 or 1, where 0 indicates no detection and 1 indicates complete detection. |
| After formation of different D-matrices, each of these can be represented as graph such that whatever the common
patterns are appearing in graphs can be combined into a single graph. |
RESULTS |
| The D-Matrix framework is created using proposed methodology. The real-life data is collected from the
automobile car system. A text driven D-Matrix is created using the symptoms shown in column and failure mode in
rows. 0 and 1 represents the probability of detection of faults. The components of car are taken that have faults
occurred during fault diagnosis and detection. Fig. 2 shows the text driven D-Matrix of the car system components. |
 |
CONCLUSION |
| In this paper an ontology-based text mining methodology is proposed to construct the D-matrix by automatically
mining the unstructured repair verbatim text data collected during fault diagnosis. Text driven D-matrix have more
impact for constructing the D-matrix framework. This framework helps the service technician to detect the faults
related to complex system and diagnose it. This dependency model (D-Matrix) contains symptoms, failure modes and
their causal relationship. Using probabilistic approach, fault detection has become easier. Development of a graph from
D-matrix gives better visualisation and analysis. |
References |
- Dnyanesh G. Rajpathak, Satnam Singh, ―An Ontology-Based Text Mining Method to Develop D-Matrix from Unstructured Text‖, IEEE ,trasactions on system, man and cybernetics : systems, vol. 44, no.7, pp. 966-977, Jul. 2014.
- S. Singh, H. S. Subramania, and C. Pinion, ―Data-driven framework for detecting anomalies in field failure Data‖, in Proc. IEEE Aerosp.Conf., pp. 1–14, 2011.
- R. Chougule and S. Chakrabarty, ―Application of ontology guided search for improved equipment diagnosis in a vehicle assembly plant‖, in Proc. IEEE CASE, pp. 90–95, 2009.
- S. Strasser, J. Sheppard, M. Schuh, R. Angryk, and C. Izurieta, ―Graph based ontology-guided data mining for d-matrix model maturation,‖ in Proc. IEEE Aerosp. Conf., pp. 1–12, 2011.
- D. Wang, W. H. Tang, and Q. H. Wu, ―Ontology-based fault diagnosis for power transformers‖, in Proc. IEEE Power Energy Soc. Gen.Meeting, pp. 1–8, 2010.
- S. Singh, S. W. Holland, and P. Bandyopadhyay, ―Trends in the development of system-level fault dependency matrices‖, in Proc. IEEE Aerosp.Conf., pp. 1–9, 2010.
- T. J. Felke and J. F. Stone, ―Method and Apparatus for Developing Fault Codes for Complex Systems Based on Historical Data‖, US Patent, 003318 A1, Jan. 2004.
- S.P. Eagleton and T. Felke, ―Method and Apparatus using Historical data to Associate Deferral Procedures and D-matrix‖, US Patent, 6,725,137 B2, Apr. 2004.
- T. Felke, ―Application of model-based diagnostic technology on the Boeing 777 airplane‖, in Proc. 13th AIAA/IEEE DASC, pp. 1–5, 1994.
- G. Ramohalli, ―The Honeywell on-board diagnostic and maintenance system for the Boeing 777‖, in Proc. IEEE/AIAA DASC, pp. 485–490, 1992.
- E. Miguelanez, K. E. Brown, R. Lewis, C. Roberts, and D. M. Lane, ―Fault diagnosis of a train door system based on semantic knowledge representation railway condition monitoring‖, in Proc. 4th IET Int.Conf., pp. 1–6, 2008.
- J. Sheppard, M. Kaufman, and T. Wilmering, ―Model based standards for diagnostic and maintenance information integration‖, in Proc. IEEE AUTOTESTCON Conf., pp. 304–310, 2012.
- M. Schuh, J. Sheppard, S. Strasser, R. Angryk, and C. Izurieta, ―Ontology-guided knowledge discovery of event sequences in maintenance data‖, inProc. IEEE AUTOTESTCON Conf., pp. 279–285, 2011.
- S. Deb, S. K. Pattipati, V. Raghavan, M. Shakeri, and R. Shrestha, ―Multi-signal flow graphs: A novel approach for system testability analysisand fault diagnosis‖, IEEE Aerosp. Electron. Syst.., vol. 10,no. 5, pp. 14–25, May 1995.
- S. Singh, A. Kodali, K. Choi, K. R. Pattipati, S. M. Namburu, S.C. Sean, D. V. Prokhorov, and L. Qiao, ―Dynamic multiple faul t diagnosis: Mathematical formulations and solution techniques‖, IEEE Trans. Syst., Man Cybern. A, Syst. Humans, vol. 39, no. 1, pp. 160–176,Jan. 2009.
- M. Schuh, J. W. Sheppard, S. Strasser, R. Angryk, and C. Izurieta, ―A Visualization tool for knowledge discovery in maintenance event sequences‖, IEEE Aerosp. Electron. Syst. Mag., vol. 28, no. 7, pp. 30–39, Jul. 2013.
- P. M. Frank and J. W¨ unnenberg, ―Robust fault diagnosis using unknown input observer schemes‖, in Proc. Fault Diagnosis Dynamical Syst.: Theory Appl., pp. 47–98, 1989.
- N. Viswanadham and R. Srichander, ―Fault detection using unknown input observers‖, Control-Theory Ad. Tech., vol. 3, pp. 91–101, 1987
- P. M. Frank, ―Fault detection in dynamic systems using analytical and knowledge-based redundancy—a survey and some new results‖, Automatica, vol. 26, no. 3, pp. 459–474, 1990.
- A. S. Willsky, ―A survey of design methods for fault detection in dynamic systems‖, Automatica, vol. 12, no. 6, pp. 601–611, 1976.
- V. Venkatasubramanian and S. H. Rich, ―An object-oriented two-tier architecture for integrating compiled and deep-level knowledge for process diagnosis‖, Comput. Chem. Eng., vol. 12, no. 9–10, pp. 903–921, 1988.
- C. Charniak and D. McDermott, Introduction to Artificial Intelligence. Reading, MA, USA: Addison Wesley, 1985.
- V. R. Benjamins, ―Problem-solving methods for diagnosis and their role in knowledge acquisition,‖ Int. J. Expert Syst.: Res. Appl., vol. 8, no. 2, pp. 93–120, 1995.
- M. Iri, K. Aoki, E. O’Shima, and H. Matsuyama, ―An algorithm for diagnosis of systems failures in the chemical process‖, Comput. Chem. Eng., vol. 3, nos. 1–4, pp. 489–493, 1979.
- T. Umeda, T. Kuriyama, E. Oshima, and H. Matsuyama, ―A graphical approach to cause and effect analysis of chemical processing systems‖, Chem. Eng. Sci., vol. 35, no. 12, pp. 2379–2388, 1980.
- M. Agosti and N. Ferro, ―Annotations as context for searching documents‖, inProc. Int. Conf. Concept. Library Inf. Sci.—Context: Nature, Impact Role, LNCS, pp. 155–170, 2005.
- D. D. Palmer and M. A. Hearst, ―Adaptive multilingual sentence boundary disambiguation‖, Comput. Linguist., vol. 23, no.2, pp. 241–318, 1997.
- J. B. Aberdeen, D. Day, L. Hirschman, P. Robinson, and M. Vilain, ―MITRE: Description of the alembic system used for MUC-6‖, inProc. Conf. Message Understand., pp. 141–155, 1995.
|