Keywords
|
| Decision tree learner, additive Cheroff bound, incremental learning, massive data streams, subsampling,,concept drifts |
INTRODUCTION
|
| The algorithm VFDT makes the assumption that training data is random sample drawn from a stationary distribution. Today large databases and data streams available for mining . They exits over month or years ,and underlying processes generating them changes during this time ,sometimes radically .For example ,a new product or promotion, a hackers attack, a holiday, changing weather conditions, changing economic conditions, or a poorly calibrated sensor could all lead to violations of this assumption. For classification systems, which attempt to learn a discrete functions given examples of its inputs and outputs, this problem takes the form of changes in the target function over time, and is known as concept drift. Traditional systems assume that all data was generated by a single concept. Traditional systems learn incorrect models when they erroneously assume that the underlying concept is stationary if it is drifting. |
| One common approach to learning from timing-changing data is repeatedly apply a traditional learner to a sliding window of w examples arrive they are inserted into the beginning of the window, a corresponding rapid number of examples is removed from the end of the window, and the learner is reapplied. As long as w is small relative to the rate of a model reflecting the current concept generating the data .If the window is too small , this may result in insufficient examples to satisfactorily learn the concept. Further ,the computational cost of reapplying a learner may be prohibitively high, if example arrive at a rapid rate and the concept changes quickly. |
| To meet these challenges we propose the CVFDT system ,which is capable of learning decision trees from high speed ,time changing data streams .CVFDT works by efficiently keeping a decision tree up-to-date with a window of examples. In a particular ,it is a able to learn a nearly equivalent model to VFDT would learn if repeatedly reapplied to a window of examples ,but in O(1) time instead of O(w)time per new example. In the next section we discuss the basics of VFDT system ,and in the following section we introduce the CVFDT system. |
LITERATURE REVIEW
|
| A. THE VFDT SYSTEM |
| The classification problem is defined as follows .A set of N training examples of the form (x ,y) is given ,where y is the discrete class label and x is a vector of d attributes ,each of which may be symbolic or numeric .The gThe goal is to produce from these examples a model y=f(x) which will be predict the classes y of future examples x with high accuracy . For examples ,x could be a description of a client ‘s recent purchases ,and y the decision to send that customer a catalog or not; or x could be a record of a cellular telephone call ,and y the decision whether it is fraudulent or not .One of the most effective and widely used classification method is decision learning .Learners of this type induce model in the form of decision trees ,where each node contains a test on an attribute ,each branch from a node corresponds to a possible outcome of the test ,and each leaf contains a class prediction .The label y=DT(x) for an example is x obtained by passing the example down from the root to a leaf, testing the appropriate attribute at each node and following the branch corresponding to the attributes value in the example. A decision tree is learned by recursively replacing leaves by test nodes, starting at the root. The attribute to test at a node is choosing the best one according to some heuristic measure. |
| We presented the VFDT ( Very Fast Decision Tree )system ,which is able to learn from abundant data within practical time and memory constraints .Thus ,only the first examples to arrive on the data stream need to be used to choose the spilt attribute at the root; subsequent ones are passed through the induced portion of the tree until they reach a leaf are used to choose a spilt attribute there, and so recursively. To determine the number of examples needed for each decision, VFDT uses a statistical result known as Hoeffding bounds or additive Chernoff bounds. After n independent observations of a real-valued random variable r with confidence 1-d ,the true mean of r is at least ? -€ ,where ? is the observed mean of the samples and |
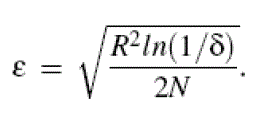 |
| Let G (Xi) be the heuristic that generated the observations. Let G(Xi) be the heuristic measure used to choose test attributes.(we use information gain).After seeing n samples at a leaf ,let Xa be the attribute with the best heuristic measure and Xb be the attribute with the second best. Let ΔG=G(Xa) –G(Xb) be a new random variable, the difference between the observed heuristic values. Applying the Hoeffding bound to ΔG ,we see that if ΔG > € ,we can confidently say that the difference between G(Xa) and G(Xb) is larger than zero ,and select Xa the split attribute. The count ni,jk the sufficient statistics needed to compute most heuristic measures; if other quantities are required ,they can be similarly maintained. When sufficient statistics fill the available memory, VFDT reduces its memory requirements by temporarily deactivating learning in the least promising nodes; these nodes can be reactivated later if they begin to look more promising than currently active nodes .VFDT employs a tie mechanism which precludes it from spending inordinate time deciding between attributes whose practical difference is negligible. |
THE CVFDT SYSTEM
|
| CVFDT (Concept –adapting Very Fast Decision Tree learner) is an extension to VFDT which maintains VFDT’s speed and accuracy to change in the example –generating process. Like other System with this capability , CVFDT works by keeping its model consistent with a sliding window of examples. However, it very does not need to learn a new model time from scratch every time a new example arrives ;instead, it updates the sufficient statistics at its nodes by incrementing the example the new counts corresponding to the new example arrives ;decrementing the counts corresponding to the oldest e xample in the window. This will statistically have no effect if the underlying concept is stationary. If the concept is changing ,some splits that previously passed the Hoeffding test will no longer do so ,because an alternatively attribute now has higher gain .In this case CVFDT begins to grow an alternative sub tree with the new best attribute at its root. When this alternative sub tree becomes more accurate on new data than the old one, the old sub tree is replaced by the new one. |
| • Increment count with new example |
| • Decrement old example |
| • Sliding window |
| • Nodes assigned monotonically increasing IDs |
| • Grows alternate more accurate => replace old |
| • O(w) better runtime than VFDT-window |
| 8) Return HT. |
| Tables 2 contain a pseudo-code outline of the CVFDT algorithm. CVFDT does some initializations, and then processes examples from the stream S indefinitely. As each example (x,y) is incorporated into the current model .CVFDT periodically scans HT all alternate trees looking for internal nodes whose sufficient statistics indicate that some new attribute would make a better test than the chosen spilt attribute. An alternate sub tree is started at each such node. |
| Table 2 contains pseudo-code for tree-growing portion of the CVFDT system. It is similar to the Hoeffding Tree Algorithm, but CVFDT monitors the validity of its old decisions by maintaining sufficient statistics at every node in HT .Forgetting an old example is slightly complicated by the fact that HT may have grown or changed since the examples was initially incorporated .Therefore, nodes are assigned a unique, monotonically increasing ID as they are created. When an example is added to W, the maximum ID of the leaves it reaches in HT and all alternate trees is recorded with it. An examples are forgotten by decrementing the counts in the sufficient statistics of every node the example reaches in HT whose ID is ≤ the sorted ID. |
| CVFDT periodically scans the internal nodes of HT looking for ones where the chosen spilt attribute would no longer be selected ;that is ,where G(Xa) -G(Xb) ≤ € and € > t . When it finds such a node a CVFDT known that it either initially made a mistake splitting on Xa or that something about the process generating examples has changed. |
EXPERIMENTAL RESULTS
|
| We are applying VFDT to mining the stream of web pages. |
FURURE SCOPE
|
| We plan to apply CVFDT to more real-world problems; its ability to adjust to concept changes should allow it to perform very well on a broad range of tasks. CVFDT may be a useful tool for identifying anomalous situations. Currently CVFDT discards sub trees that are out-of-date, but some concepts change periodically and these sub trees may become useful again – identifying these situations and taking advantage of them is another area for further study. Other areas for study include: comparisons with related systems; continuous attributes. |
CONCLUSION
|
| VFDT is a high-performance data mining system based on Hoeffding trees. Empirical studies show its effectiveness in taking advantage of massive numbers of examples. This application also uses CVFDT, a decision-tree induction system capable of learning accurate models from the most demanding high-speed, concept-drifting data streams. CVFDT is able to maintain a decision-tree up-to-date with a window of examples by using a small, constant amount of time for each new example that arrives. |
| The resulting accuracy is similar to what would be obtained by reapplying a conventional learner to the entire window every time a new example arrives. Empirical studies show that CVFDT is effectively able to keep its model up-to-date with a massive data stream even in the face of large and frequent concept shifts. |
ACKNOWLEDEMENT
|
| This is a great pleasure and immense satisfaction to express my deepest sense of gratitude and thanks to everyone who has directly or indirectly helped me . I express my my gratitude towards my project guide Prof.Rajesh Bharati ,for his suggestion and constant guildline during paper presention. |
| It is a privilege for me to thank my P.G. Cordinator Prof. Jyoti Rao for her constant support. |
| |
Tables at a glance
|
 |
|
|
|
| Table 1 |
Table 2 |
Table 3 |
Table 4 |
|
| |
References
|
- Geoff Hutten, Pedro Domingo’s, “Mining High-Speed Data Streams”, ACM.
- G. Hulten, L. Spencer, and P. Domingo’s. Mining time-changing data streams. In KDD’01, pages 97–106. ACM, 2001.
- Peipei Li, Xindong Wu, Xuegang Hu, “Learning from Concept Drifting Data Streams with Unlabeled Data”.
- G. Holmes, R. Kirkby, and B. Pfahringer. Moa: Massive online analysis. http://sourceforge.net/projects/moa-datastream , 2007.
- J. Gama, P. Medas, and P. Rodrigues. “Learning Decision Trees from Dynamic Data Streams.”, IEEE 2005.
- Chunquan Liang, Yang Zhang, Qun Song, “Decision Tree for Dynamic and Uncertain Data Streams”.
- L. Breiman, J. H. Friedman, R. A. Olshen, and C. J.Stone. Classi_cation and Regression Trees.Wadsworth, Belmont, CA, 1984.
|