International Journal of Innovative Research in Computer and Communication Engineering
ISSN ONLINE(2320-9801) PRINT (2320-9798)
ISSN ONLINE(2320-9801) PRINT (2320-9798)
P.RAMYA1 and DR.NALINI2
|
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Innovative Research in Computer and Communication Engineering
Search queries on biomedical databases, such as Pub Med, frequently return a large number of results, only a small subset of which is applicable to the user. Classification and cataloging, which can also be united, have been suggested to improve this information overload problem. Result optimization and results categorization for biomedical databases are the focus of this work. A natural way to establish biomedical credentials is affording to their Mesh annotations. Mesh is a inclusive concept hierarchy used by Pub Med. In this paper, we present the BioIntelR (BIR) system, adopts the BioNav system enables the user to revolve large number of query results by organizing them using the Mesh concept hierarchy. First, BioIntelR (BIR) system prompts the user for the exploration criteria and the system automatically connects to a middle layer created at the application level which directs the query to the proper valid query path to select correct criteria of the search result from the biomedical database. The query results are organized into navigation tree. At each node expansion step, BIR system exposes only a small subset of the concept nodes, preferred such that the predictable user navigation cost is minimized. In disparity, to the previous systems, the BIR system outdoes and optimizes the query result time and reduces query result set for easy user navigation, Data Warehousing.
Keywords |
| Cooperating Data reflection and finding, Exploration Procedure, Graphical User Interfaces, Interface Styles. |
INTRODUCTION |
| The MEDLINE database, on which the PubMed search engine operates, contains over 18 million credentials, and the database is presently growing at the rate of 500,000 new citations each year. Other biological sources, such as Entrez Gene and OMIM, witness parallel development. As claimed in preceding work, the capability to rapidly survey this literature constitutes a necessary step toward both the design and the interpretation of any large scale experimentation. Biologists, chemists, medical and physical condition scientists are used to searching their domain literature – such as PubMed– using a keyword search crossing point. Currently, in a inquiring position where the user tries to find credentials relevant to her line of research and hence not known a priori, she submits an primarily extensive keyword- based query that typically returns a large amount of results. Consequently, the user iteratively refines the query, if she has an suggestion of how to, by calculation more keywords, and re-submits it, until a moderately small number of results are returned. This refinement process is problematic because after a number of iterations the user is not aware if she has over-specified the query, in which case pertinent credentials might be excluded from the final query consequence. As an example, a query on PubMed for “cancer” returns more than 2 million credentials. Even a more specific query for “prothymosin”, a nucleoprotein gaining attention for its putative role in cancer development, returns 313 credentials. The size of the query result makes it difficult for the user to find the credentials that she is most involved in, and a large quantity of exertion is exhausted searching for these consequences. Several solutions have been planned to address this problem Commonly referred to as in sequence overload. These approaches can be generally classified into two classes: ranking and cataloging, which can also be collective. BioNav belongs primarily to the organization class, which is perfect for this province specified the rich concept hierarchies (e.g., Mesh) available for biomedical data. We augment our categorization techniques with simple position techniques. BioNav organizes the query consequences into a dynamic hierarchy, the navigation tree. Each concept (node) of the hierarchy has a descriptive label. The user then navigates this tree structure, in a top-down fashion, exploring the concepts of interest while ignoring the respite. An instinctive way to classify the results of a query on PubMed is using the Mesh static concept hierarchy [18], thus utilizing the inventiveness of the US National Library of Medicine (NLM) to build and maintain such an inclusive arrangement. Each extract in MEDLINE is coupled with several Mesh concepts in two ways: (i) by being explicitly annotated among them, and (ii) by mentioning individuals in their content (see Section 7 for in sequence). Since these relations are provided by PubMed, a comparatively simple interface to navigate the query result would first attach the credentials to the corresponding Mesh concept nodes and then let the user navigate the navigation tree. Fig. 1 displays a snapshot of such an interface where shown next to each node label is the count of distinct credentials in the sub tree rooted at that node. A representative navigation starts by informative the children of the root ranked by their extract count, and is continual by the user intensifying on or more of them, skimpy their ranked children and so on, until she clicks on a concept and inspects the recommendation emotionally involved to it. A comparable interface and navigation technique is used by e-commerce sites, such as Amazon and eBay. For this example, we presume that the user will navigate to the three indicated concepts corresponding to three independent lines of research related to prothymosin. Our next part details about literature survey. Our third part details about system architecture. Our Forth part details about critical analysis. Our Fifth part details about conclusion. Our sixth part details about reference. |
LITERATURE SURVEY |
| Literature survey is the most important step in software growth process. Before increasing the tool it is essential to regulate the moment aspect, economy in company strength. Once these things satisfied, ten next steps are to determine which operating system and language can be used for developing the tool. Once the programmers start building the tool the programmers need lot of peripheral preserve. This support can be obtained from superior programmers, from book or from websites. Previous to construction the system the above consideration taken into account for developing the proposed system. |
| A. Query Search process module (or) Biomedical Search Systems: |
| PubMed– using a keyword search interfaces. Currently, in an examining development where the user tries to find credentials pertinent to her line of research and hence not known a priori, she submits a primarily broad keywordbased query that typically returns a large number of results. Consequently, the user iteratively refines the query, if she has an idea of how to, by adding more keywords, and re-submits it, until a comparatively small number of results are returned. This enhancement process is difficult because after a number of iterations the user is not aware if she has over-specified the query, in which case important credentials might be excluded from the final query result. Query on PubMed is using the Mesh stagnant concept hierarchy, thus utilizing the program of the US National Library of Medicine (NLM) to build and maintain such a complete structure. Each citation in MEDLINE is connected with several Mesh concepts in two ways: (i) by being explicitly annotated with them, and (ii) by mentioning those in their text. Since these relations are provided by PubMed, a reasonably straightforward interface to navigate the query result would first attach the credentials to the corresponding Mesh concept nodes and then let the user navigate the navigation tree. |
| B. Dynamic navigation tree module: |
| Navigation tree. Fig displays a snapshot of such an interface where shown next to each node label is the count of distinct credentials in the sub tree embedded at that node. A characteristic navigation starts by skimpy the children of the root ranked by their extract count, and is sustained by the user increasing on or more of them, informative their ranked children and so on, until she clicks on a concept and inspects the credentials emotionally involved to it. A related interface and navigation method is used by e-commerce sites, such as Amazon and eBay. For this example, we suppose that the user will navigate to the three indicated concepts corresponding to three independent lines of research related to prothymosin. BioNav introduces a dynamic navigation manner that depends on the particular query result at hand and is confirmed in Fig The query results are attached to the corresponding Mesh concept nodes as in Fig. but then the navigation profits differently. The key exploit on the interface is the development of a node that selectively reveals a ranked list of successor (not necessarily children) concepts, as an alternative of just showing all its children. |
| C.Hierarchy navigation web (interface) search module: |
| BioNav belongs primarily to the cataloging class, which is perfect for this domain given the rich concept hierarchies (e.g., Mesh) accessible for biomedical data. We supplement our organization techniques with simple position techniques. BioNav organizes the query results into a dynamic hierarchy, the navigation tree. Each perception (node) of the hierarchy has a expressive label. The user then navigates this tree arrangement, in a top-down approach, exploring the concepts of importance while ignoring the rest. |
| D. Query Workload online operation module: |
| On-Line Operation. Upon receiving a keyword query from the user, BioNav executes the similar query in opposition to the MEDLINE database and retrieves only the IDs. (Pub Med Identifiers) of the credentials in the query result. This is done using the ESearch effectiveness of the Entrez Programming Utilities (eUtils). eUtils are a compilation of web interfaces to PubMed for issuing a query and downloading the results with various levels of detail and in a multiplicity of formats. Next, the navigation tree is constructed by retrieving the Mesh concepts associated with each citation in the query result from the BioNav database. This is probable ever since Mesh concepts have tree identifiers encoding their location in the Mesh hierarchy, which are also improved from the BioNav database. This process is prepared once for each user query. |
SYSTEM ARCHITECTURE |
| A. ARCHITECTURE DIAGRAM |
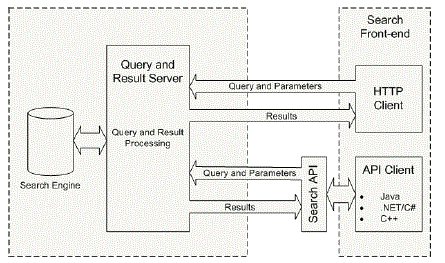 |
| The link between the information system and the user. It includes the increasing requirement and techniques for data Provision and those steps are necessary to put operation data in to a usable form for processing can be completed by scrutinizing the computer to read data from a written or printed document or it can occur by having people keying the data directly keen on the system. The design of input focuses on controlling the amount of input required, controlling the errors, avoiding impediment, avoiding additional steps and maintenance the procedure easy. The input is designed in such a way so that it provides security and luxury of use with absorbent the confidentiality. |
OBJECTIVES |
| 1. Input Design is the process of converting a user-oriented description of the input into a computer-based system. This design is significant to avoid errors in the data input process and show the correct direction to the management for getting correct information from the computerized system. |
| 2. It is achieved by creating user-friendly screens for the data entry to handle large quantity of data. The goal of designing input is to compose data entry easier and to be free from errors. The data admission screen is designed in such a way that all the data manipulates can be performed. It also provides record performance services. |
| 3. When the data is entered it will check for its authority. Data can be entered with the facilitate of screens. Appropriate communication are provided as when needed so that the user will not be in maize of instantaneous. Thus the purpose of input design is to create an input layout that is easy to follow. |
| A quality output is one, which meets the requirements of the end user and presents the information obviously. In any system results of dispensation are interconnected to the users and to other system during outputs. In output design it is untiring how the information is to be displaced for immediate need and also the hard copy output. It is the most important and express source information to the user. Proficient and intellectual output design rallies the system’s relationship to help user decision-making. |
| 1. Designing computer output should keep on in an organized, well supposed out manner; the right output must be developed while ensuring that each output element is designed so that people will find the system can use simply and efficiently. When analysis design computer output, they should Identify the specific output that is needed to come across the necessities. |
| 2. Select methods for presenting information. |
| 3. Create document, report, or other formats that contain information produced by the system. The output structure of an information system should accomplish one or more of the following objectives. |
| • Convey information about past actions, present position or projections of the |
| • Future. |
| • Signal significant procedures, opportunities, problems, or warnings. |
| • Trigger an action. |
CONCLUSION |
| Information overload is a major problem when searching biomedical databases such as PubMed, where characteristically a great number of credentials are resumed, of which only a small subset is appropriate to the user. In this paper, we presented the BioNav system to address this problem. Our solution is to organize the query results permitting to their connotations to concepts of the Mesh conception hierarchy, and present a dynamic navigation process that minimizes the information overload perceived by the user. When the user expands a Mesh concept on our web interface, BioNav reveals only a selective list of successor concepts, instead of only performance all its children, ranked based on their estimated relevance to the user's query. We properly confirmed the essential framework and the navigation and cost models used for the evaluation of our advance. Our difficulty result proved that the predicament of intensifying the navigation tree in a way that minimizes the user's navigation cost is NP-complete. A reasonable (for small trees) optimum algorithm and an efficient heuristic were developed. Experimental results validated the effectiveness of the proposed heuristic for diverse sets of queries and navigation trees, when compared to categorization systems using a static navigation method. The architecture of the BioNav system was implemented and is available at |
References |
|