Digital Image forgery is happening worldwide and it is considerd offensive.Today,however, powerful digital image editing software makes image modifications straightforward .There are many ways to categorize the image tampering which does not yield the accurate result. The proposed method uses SIFT(Scale Invariant Feature Transform) to detect and describe local features in images. When matching the feature points there will be lots of mismatches. The RANSAC(Random Sample Consencus) can be used to eliminate the mismatches by the transformation matrix of these feature points. For large database SR-PE(Scale –Rotation Invariant Pattern Entrophy) helps in tracking the spatial regularity of matching pattern formed by local keypoints . So SIFT algorithm along with SR-PE and RANSAC helps in finding the accurate matching pattern formed by local keypoints.
Keywords |
| Digital image forensics; Region Duplication Detection, Image Feature Matching, Keypoints |
INTRODUCTION |
| The process of creating fake image has been tremendously simple with the powerful computer graphics editing
software such as Adobe photoshop , corel paint shop and GIMP. There are different types of forgeries like image
retouching ,image splicing and copy move attack .The existing method is machine learning which requires minimal
user interaction .The technique is applicable to images containing two or more people and requires no expert
interaction for the tampering decision. Proposed method generates distinctive invariant features from images that can
be used to perform reliable matching between different views of an object or scene.. Image retouching does not affect
much because it increases the intensity of the images. Image splicing is the morphing of two or more images.Copy
move attack is more or less similar to image splicing in the fact that both techniques modify certain image region with
another image. |
RELATED WORK |
| A common manipulation in tampering the digital images is known as region morphing, where a cluster of pixels is
copied and pasted to a different area in the same image. In recent years several methods have been proposed to detect
the morphed areas for the purpose of image forensics. These methods are more effective for the detection of region
copy-move, where a group of pixels is copied to another location of the same image. |
| A copy move forgery a portion of an image is copied to different location on the same image. It is difficult to
distinguish and detect because the copied part has the properties like noise, colour and texture ,will be compatible
with the rest of the image. One method for detecting the copy-move forgery is by block-matching procedure, which
first divides the image into overlapping blocks. It hence detect the image blocks that where duplicated, instead of
detecting the whole duplicated region. Since the copied region would consist of many overlapping blocks and moving
the region means moving all the blocks by the same amount ,the distance between each duplicated pair would be the
same. In this way the decision of forgery can be made and detected. |
| Keypoints and features based on the SIFT algorithm are used to account for illumination changes in the detection
of copy-move region duplication. Here we describe a SIFT matching based detection method that locate the duplicate
keypoints with rotation, scaling and shearing . . But similar to, it does not provide the exact extent and location of the
detected duplicated region, but only displays the matched keypoints[1]. This technique is largely applied to simple
forgeries where humans couldn’t find any difficulty in finding the duplicated region and the performance on highly
challenging realist forgery images is largely unknown. The first step in collecting the image keypoints is to identify the distinctive image transform and robust to scaling and rotation. This is achieved by identifying the extrema in scale
space detection and the orientation is assigned to all the keypoints.The number of keypoints should be less than the
pixels, thus subsequent computation will not be wasted at locations with little image information. At each keypoint, a
SIFT feature vector is generated from the normalized histograms of local gradients in a neighbourhood of pixels of
that keypoint[2]. The size of the neighbourhood is determined by the scale of the keypoint, and all gradients are
aligned with the dominant orientation at the keypoint. From the illuminant based technique[3] the texture and the
edge features are extracted and which is then given to the machine learning approach for the automatic decision
making. The classification performance using SVM meta-fusion classifier is promising. Interpretation of the
illumination distribution as object texture for feature computation .An edge based characterization for illuminant
maps which detect edge attributes. The creation of benchmark dataset should contain 100 skilfully created forgeries
and 100 original photographs. |
| The keypoints [4] and feature based on scale invariant feature transform(SIFT) are used to account for illumination
changes in the detection of copy-move region duplication. The robustness of SIFT keypoints and features to image
distortions is not fully exploited, which prevents this method from being extended to detect affine transformed
duplicated regions. Image content is transformed into local feature coordinates that are invariant to translation,
rotation,scale and other imaging parameter. |
 |
| Proposed method detects the distorted duplicated region in the following modules: |
| Finding Image Keypoints |
| Keypoints Matching |
| Eliminating Mismatched keypoints |
| Estimation of Affine Transform |
| Identifying Duplicated Regions |
| A. Finding image keypoints |
| To extract the keypoints SIFT algorithm is used and it consist of following steps:- |
| 1.Scale space peak selection |
| This helps in identifying the location of peaks in scale space using the different smoothing version of the
same image. By varying the size of an image the interest point can be detected. The scale space is defined by L(x, y,
σ) and Gaussian filter by G(x, y, σ) with an input image I (x, y). Smoothening by Gaussian filter zero crossing appear.
When increasing the scale the zero crossing disappear .Given the scale space, the scale decreases and the zero
crossing break into two and merge each other. The whole spectrum of zero crossing is taken and interpreted and made
into more zero crossing. The nodes which is less stable is eliminated and top level description of several signals is
obtained using the stability criteria. For 2D we go for Laplacian of Gaussian(LoG) and it is obtained using different
sigma value. When looking at 3x3 neighbourhood we look the point above and below the centre point .comparing the
centre point with all other 27 points the maxima and minima is obtained .All scales must be examined to identify
Scale-Invariant Features. An efficient function is to compute the laplacian pyramid (Difference of Gaussian).The .
The relationship between D and G can be understood from the heat diffusion equation |
 |
| 3. Orientation assignment |
| One or more orientations are assigned to each keypoint location based on local image gradient directions. All future
operations are performed on image data that has been transformed relative to the assigned orientation, scale, and
location for each feature, thereby providing invariance to these transformations. To achieve rotation invariance
compute central derivatives gradient magnitude and direction of L(smooth image) at the scale of keypoint (x,y).
Create histogram of gradient directions, within a region around the keypoint, at selected scale |
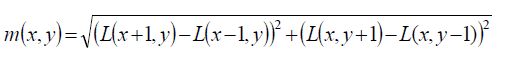 |
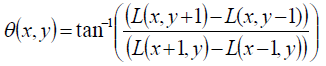 |
| Create a weighted direction histogram in a neighbourhood of a keypoint of 36 bins. Each of this will be of 10 degrees.
Select the peak as direction of the keypoint. Introduce additional keypoints (same location) at local peaks(within 80%
of maximum peak) of the histogram with different direction. In the case of peaks within 80% of highest peak,
multiple orientation assigned to keypoints. About 15% of keypoints has multiple orientations assigned which
significantly improves stability of matching. |
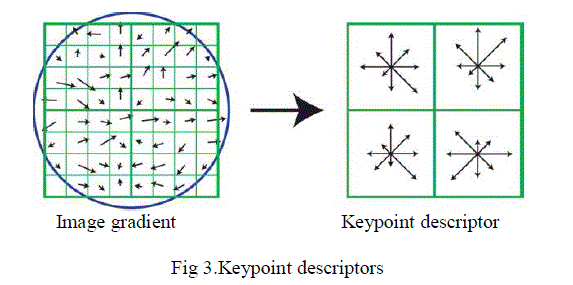
| 4. keypoint descriptor |
| Possible descriptor Store intensity samples in the neighbourhood which is sensitive to lightening changes ,3D object
transformation and use of gradient orientation histograms.Each histogram entry is weighted by gradiant magnitude
and a Gaussian function with σ equal to 0.5 time the width of the descriptor window . To ensure the obtained feature
vector invariant to rotation and scaling, the size of the neighbourhood is determined by the dominant scale of the
keypoint, and all gradients within are aligned with the keypoint’s dominant orientation dominant orientation.
Furthermore, the obtained histograms are normalized to unit length, which renders the feature vector invariant to local
illumination changes. |
 |
| B. Matching key-point |
| The detected keypoints are matched using Scale –Rotation invariant Pattern Entrophy algorithm.Its effectiveness
is mainly based on large dataset. we describe an algorithm, namely Scale-Rotation invariant Pattern Entropy (SRPE),
for the detection of near-duplicates in large-scale database. SR-PE is a novel pattern evaluation technique
capable of measuring the spatial regularity of matching patterns formed by local keypoints. To demonstrate our work
in large-scale dataset, a practical framework composed of three components: bag-of-words representation, local
keypoint matching and SR-PE evaluation, is also proposed for the rapid detection of near-duplicates. |
| The followings steps are:- |
| 1.Find a set of distinctive key-points |
| 2.Define a region around each key-point |
 |
| 3.Extract and normalize the region content |
| 4. Compute a local descriptor from the normalized region |
| 5.Match local descriptors |
| C. Eliminating the mismatched keypoints |
| We use SIFT for matching the keypoints with the help of affine transform parameters and it is unreliable for
large mismatched keypoints.To find out the unreliable keypoints we use Random Sample Consensus which run N
times to detect the unreliable keypoints and the following steps are:- |
| 1. Select sample of m points at random |
| 2. Calculate model parameters that fit the data in the sample |
| 3. Calculate error function for each data point |
| 4. Select data that support current hypothesis |
| 5. Repeat sampling |
| This measure performs well because correct matches need to have the closest neighbour significantly closer
than the closest incorrect match to achieve reliable matching. For false matches, there will likely be a number of other
false matches within similar distances due to the high dimensionality of the feature space. We can think of the
second-closest match as providing an estimate of the density of false matches within this portion of the feature space
and at the same time identifying specific instances of feature ambiguity. we obtain two sets of region pairs
corresponding to scale and rotation channels respectively. |
| D. Estimation of Affine transform |
| To generalize transforms such as rotation, scaling and shearing that are supported in most photo-editing
software, we model the distortion as affine transform of pixel coordinates. Given two corresponding pixel locations
from a region and its duplicate as |
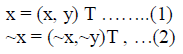 |
| respectively, they are related by a 2D affine transform specified by a 2x2 matrix T and a shift vector x0 as: |
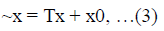 |
| or more explicitly. We need at least three pairs of corresponding keypoints that are not collinear. In practice, due to
imprecise matching, it may not be satisfied exactly, and we form the least squares objective function using matched
keypoints and searching for T and x0 that minimize it. |
| E. Identifying duplicated regions |
| Estimate of the original and duplicated pixels is compared and a more effective measure is obtained by
comparing the distance of the closest neighbour to that of the second-closest neighbour. If there are multiple training
images of the same object, then we define the second closest neighbour as being the closest neighbour that is known
to come from a different object than the first, such as by only using images known to contain different objects. This
measure performs well because correct matches need to have the closest neighbour significantly closer than the
closest incorrect match to achieve reliable matching. For false matches, there will likely be a number of other false
matches within similar distances due to the high dimensionality of the feature space. We can think of the secondclosest
match as providing an estimate of the density of false matches within this portion of the feature space and at
the same time identifying specific instances of feature ambiguity. |
CONCLUSION |
| Region duplication is becoming an important issue and our paper describe an efficient method to solve this
problem.Our method is based on SIFT features which helps in matching the keypoint.For elliminating the unreliable
keypoints RANSAC algorthim performs well because correct matches need to have the closest neighbour
significantly closer than the closest incorrect match to achieve reliable matching. For false matches, there will likely
be a number of other false matches within similar distances due to the high dimensionality of the feature space.The
result conclude that it is effective and robust in conditions like noise, and different JPEG qualities. Compared to other
method where only matched key points are shown as detection results, we further estimate the transform between duplicated regions based on SIFT features and recover the complete region contours using correlation map.Thus for
future work,we consider by using different different specification such as PCA-SIFT or histograms of oriented
gradients, and combining with other detection schemes based on intrinsic signal statistics patterns to provide strong
cues when image keypoints and features are not sufficient. |
| |
References |
- B.L.Shivakumar1 Lt,Dr. S.SanthoshBaboo,âÃâ¬Ã Detecting Copy move forgery in digital images:âÃâ¬Ã A Survey and Analysis of current Method, Global Journal of computer science and technology,Vol. 10 Issue 7 Ver.1.0 September 2010.
- Xunyu Pan and SiweiLyu, âÃâ¬ÃÅRegion duplication detection using image feature matchingâÃâ¬ÃÂ,IEEE Transaction on Information forensics and security, VOL. X, NO. X, XX 2010.
- WeiqiLuo, Jiwu Huang and GuopingQiu âÃâ¬ÃÅRobust Detection of Region-Duplication Forgery in Digital ImageâÃâ¬ÃÂ, IEEE Transaction on Information forensics and security, 2006.
- SevincBayram, HusrevTahaSencar ,NasirMemon âÃâ¬ÃÅAn efficient and robust method for detecting copy move forgeryâÃâ¬Ã IEEE Transaction on Information forensics and security,2009.
- A.C. Popescu and H.Farid. âÃâ¬ÃÅExposing digital forgeries by detecting duplicated image regionsâÃâ¬ÃÂ. Technical Report TR2004-515, Department of Computer science, Dartmouth College, 2004.M. Young, The Technical Writer's Handbook. Mill Valley, CA: University Science, 198
|