International Journal of Advanced Research in Electrical, Electronics and Instrumentation Engineering
ISSN ONLINE(2278-8875) PRINT (2320-3765)
ISSN ONLINE(2278-8875) PRINT (2320-3765)
Angel Mathew1 and Preethy Prince Thachil2
|
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Advanced Research in Electrical, Electronics and Instrumentation Engineering
Speaker identification is a biometric system. In speaker identification the task is to determine the unknown speaker identity by selecting one from the whole population. The key idea is that it uses fuzzy clustering, to partition the original large population into subgroups. Clustering is done based on some features of the speeches. For a speaker under test, first conduct the fuzzy clustering based classification. Then apply MFCC + Neural network identification approach to the selected leaf node to determine the unknown speaker.
Keywords |
| Fuzzy clustering, MFCC, Neural Networks |
INTRODUCTION |
| Identify a person from the sound of their voice is known as speaker identification [1]. There are two types of identification process. They are closed set identification and open set identification. In the closed set identification process set of registered speakers will be there, whereas in the open set the speaker will not be there in the database. |
| In speaker identification, human speech from an individual is used to identify who that individual is. There are two different operational phases. They are training phase and testing phase. In training the speech from verified speaker need to be identified, is acquired to train the model for that speaker. This is carried out usually before the system is deployed. In testing the true operation of the system is carried out where the speech from an unknown speaker is compared against each of the trained speaker models. |
| There are different techniques used for the identification process [2], [3]. In order to accomplish large population speakers and to identify the speakers in the correct group fuzzy clustering approach [4] has been used. Based on the features, the speakers can be separated into different group. At each level of the tree, we use a speech feature to do speaker clustering, i.e., a node (or a speaker group) splits into several child nodes (or speaker subgroups) at its lower level. In this process, speakers with similar speech feature are put into a same child node whereas speakers with dissimilar speech feature are put into different child nodes. Then, each child node contains a smaller population size than its parent node. Thus, at the bottom level, each speaker group at the leaf node has a very small population size and the population reduction is achieved. At the bottom level, we select one and only one speaker group at the leaf node that the speaker belongs to and apply MFCC + Neural Network to the selected speaker group for speaker identification. The advantage of our approach is that 1) we only apply MFCC + Neural Network to the speaker group at the leaf node with a very small population size instead of applying it to the original large population, 2) less computational complexity, and 3) more accurate. |
| Speaker recognition is the process of automatically recognizing who is speaking on the basis of individual information included in speech waves. Similar to a biometric system, it has two sessions:- |
| ïÃâ÷ Enrollment session or Training phase |
| In the training phase, each registered speaker has to provide samples of their speech so that the system can build or train a reference model for that speaker. |
| ïÃâ÷ Operation session or Testing phase |
| During the testing (operational) phase, the input speech is matched with stored reference model(s) and recognition decision is made.For this we have initially taken a database of 5 different speakers and recorded 5 samples of the same text speech from each speaker. Then we have extracted pitch, pulse width, skewness, peak average ratio, zero crossing, energy of the speeches as a part of the feature extraction process. And for feature matching purpose fuzzy clustering is taken place. And for the identification purpose MFCC and neural network is applied. Finally evaluate the performance between the exciting method and also with this proposed method. All this work has been carried out using MATLAB 2010. |
FUZZY CLUSTERING |
| In large population speaker identification, it’s feasible to use hierarchical decision tree for population reduction because human speech does contain many useful features that can be used to cluster speakers into groups. Speaker groups do exist that speakers sharing with a similar speech feature are in a same group whereas speakers having different speech features are from different groups. For example, speakers with different genders can be distinguished by using pitch feature [5]; based on different movement patterns of the vocal cords, different speaker groups could be obtained; Many emerging features which are independent from MFCC may indicate different speaker groups [6]. In summary, human speech has many different attributes and it’s feasible to cluster speaker into groups by using various speech features. At each level of our hierarchical decision tree, we try to find different speaker groups by examining a certain attribute of speech. To achieve good performance, features used in our approach for clustering should meet the following requirements: 1) a good feature should be very capable of discriminating different groups of speakers; 2) features used at different levels of the tree should be independent from each other; 3) all features should be robust to additive noise. |
| A. Feature Description |
| All features we used fall into the category of vocal source feature. The source-filter model of speech production [7] tells us that speech is generated by a sound source (i.e., the vibration of vocal cords) going through a linear acoustic filter (i.e., the combination of the vocal tract and the lip). MFCC mainly represents the vocal tract information. The vocal source is believed to be an independent component from the vocal tract and is able to provide some speakerspecific information. This is why we are interested in extracting vocal source features for speaker clustering. The first feature we derived is pitch or fundamental frequency. The rest of five features are all related to the vocal source excitation of voiced sounds. We extract them from the linear predictive (LP) residual signal [8]. |
| B. Feature Extraction |
| In this section, we will specify how the six features are extracted from the speech signal. |
| 1) Pitch Extraction: Pitch is calculated using cross correlation function. The samples are overlapped. By doing the overlapping samples, no information from the samples will be lost. It uses a 30msec segment and it chooses a segment at every 20msec so it overlaps at every 10mses. In the range of 60 Hz to 320 Hz [9] maximum autocorrelation is found out. |
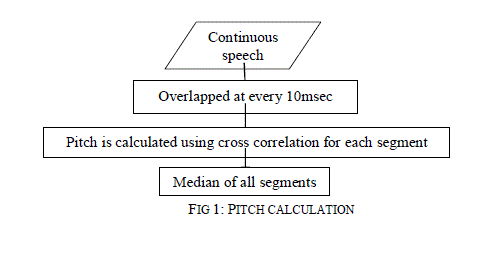 |
| 2) Vocal Source Features Extraction: The vocal source features are only derived from voiced speech frames. Given a continuous speech as the input, it is decomposed into short-time frames. The algorithm for vocal source feature extraction is as follows: |
 |
MFCC + NEURAL NETWORKS |
| After obtaining the features, we have to identify the speaker. In order to identify the speaker MFCC [12] and neural network approach is applied. Since this approach is applied to the last node of the clustered output, the number of speakers will be reduced as compared to the parent node. So that it will function properly. |
| 1) MFCC: MFCC (mel-frequency cepstrum coefficients) is based on the human peripheral auditory system. The human perception of the frequency contents of sounds for speech signals does not follow a linear scale. Thus for each tone with an actual frequency measured in Hz, a subjective pitch is measured on a scale called the ‘Mel Scale’.The mel frequency scale is a linear frequency spacing below 1000 Hz and logarithmic spacing above 1kHz.As a reference point, the pitch of a 1 kHz tone, 40 dB above the perceptual hearing threshold, is defined as 1000 Mels. A compact representation would be provided by a set of mel-frequency cepstrum coefficients (MFCC), which are the results of a cosine transform of the real logarithm of the short-term energy spectrum expressed on a mel-frequency scale. |
| Fmel=2595 log10 (1+f/100) |
 |
 |
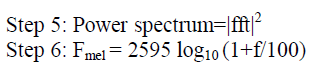 |
| 2) Neural Network: Neural network [13] is a machine that is designed to model the way in which brain performs a particular task or function of interest and network is usually implemented by using electronic components or is simulated on software in a computer. |
| To achieve good performance neural network employ a massive interconnection of simple computing cells referred to as neurons or processing units. It resembles the brain in two aspects 1) knowledge is acquired by network from its environment through a learning process. 2) Interneuron connection known as synaptic weights are used to acquire knowledge. |
| The procedure used to perform the learning process is called a learning algorithm, the function of which is to modify the synaptic weights of the network in an orderly fashion to attain a desired design objective. |
| The algorithm used in the Neural Network is backpropagation algorithm with adaptive learing Rate.the multilayer perceptrons have been applied successfully to solve some difficult and diverse problems by training them in a supervised manner with a highly popular algorithm known as back propagation algorithm. |
| The network consists of source nodes. The constitute the input layer, one or more hidden layer of computation nodes and an output layer of computation nodes. The input signal propagates through the network in a forward direction, on a layer by layer basis. These neural networks are commonly referred to as multilayer perceptrons. |
| Two kinds of signals are identified in the multilayer perceptron networks. A function signal is an input signal that comes in at the input end of the network, propagates forward through the network and emerges at the output end of the network as an output signal. An error signal originates at an output neuron of the network and propagates backward through the network. |
| An artificial neuron is a device with many inputs and one output. The neuron has two modes of operation; the training mode and the using mode. In the training mode, the neuron can be trained to fire (or not), for particular input patterns. In the using mode, when a taught input pattern is detected at the input, its associated output becomes the current output. If the input pattern does not belong in the taught list of input patterns, the firing rule is used to determine whether to fire or not. |
| Back propagation learning consists of two passes through different layers of the network, a forward pass and a backward pass. In the forward pass an input vector is applied to the input nodes of the network and its effect propagates through the network layer by layer. Finally a set of outputs is produced as the actual response of the network. During the forward pass the synaptic weights of the networks are not altered. In the backward pass, on the other hand, the synaptic weights are all adjusted in accordance with an error correction rule. Specifically the actual response of the network is subtracted from a desired response to produce an error signal. This error signal is then propagated backward through the network against the direction of synaptic connection, hence the name error back propagation. The synaptic weights are adjusted to make the actual response of the network move closed to the desired response in a statistical sense. The learning process performed with the algorithm is called back propagation learning. |
| The adaptive learning rate says that the human brain performs the formidable task of sorting a continuous flood of sensory information received from the environment. New memories are stored in such a fashion that existing ones are not forgotten or modified. The human brain remains plastic and stable. |
CONCLUSION |
| As the most of the speaker identification technique, approach based on MFCC and Neural Network also performs well. But as the population increases the performance degrades such as accuracy decreases and computational complexity increases. To improve the performance in the large population fuzzy clustering approach is applied. In this approach it partitions the large population of speakers into very small group and determines the speaker group at the leaf node to which a speaker under test belongs. To this leaf node MFCC and neural network approach is applied. |
RESULT |
| My thesis work is based on identifying an unknown speaker given a set of registered speakers. Here I have assumed the unknown speaker to be one of the known speakers and tried to develop a model to which it can best fit into. In the first step the speakers are clustered according to the features using fuzzy clustering. From 25 speakers, 22 speakers are correctly identified. And also time taken is also very less. |
ACKNOWLEDGMENT |
| I take this opportunity to express my gratitude to all who have encouraged and helped me throughout the completion of this study. First and foremost, I thank the Lord Almighty for his blessings by which I could successfully complete this project work. My special gratitude goes to the Principal Prof. Dr. BABU KURIAN, who gave me an opportunity to conduct such a study. I also express my heartfelt gratitude to Mr. Robin Abraham, Head of the Department of Electronics and Communication. I am extremely grateful to Mrs. Angel Mathew (Assistant Professor, Department of Electronics and communication), for her valuable suggestions and encouragement throughout work. |
References |
|