INTRODUCTION
|
| MANY-TASK Computing (MTC) paradigm [1] embraces different types of high-performance applications involving many different tasks, and requiring large number of computational resources over short periods of time. These tasks can be of very different nature, with sizes from small to large, loosely coupled or tightly coupled, or compute-intensive or data-intensive. Cloud computing technologies can offer important benefits for IT organizations and data centers running MTC applications: elasticity and rapid provisioning, enabling the organization to increase or decrease its infrastructure capacity within minutes, according to the computing necessities; pay as-you-go model, allowing organizations to purchase and pay for the exact amount of infrastructure they require at any specific time; reduced capital costs, since organizations can reduce or even eliminate their in-house infrastructures, resulting on a reduction in capital investment and personnel costs; access to potentially “unlimited” resources, as most cloud providers allow to deploy hundreds or even thousands of server instances simultaneously; and flexibility, because the user can deploy cloud instances with different hardware configurations, operating systems, and software packages. Computing clusters have been one of the most popular platforms for solving MTC problems, specially in the case of loosely coupled tasks (e.g., high-throughput computing applications). However, building and managing physical clusters exhibits several drawbacks: 1) major investments in hardware, specialized installations (cooling, power, etc.),and qualified personal; 2) long periods of cluster underutilization; and 3) cluster overloading and insufficient computational resources during peak demand periods. Regarding these limitations, cloud computing technology has been proposed as a viable solution to deploy elastic computing clusters, or to complement the in-house data center infrastructure to satisfy peak workloads. For example, the Bio Team [2] has deployed the Univa UD UniCluster Express in an hybrid setup, which combines local physical nodes with virtual nodes deployed in the Amazon EC2. In a recent work [3], we extend this hybrid solution by includingvirtualization in the local site, so providing a flexible and agile management of the whole infrastructure, that may include resources from remote providers. However, all these cluster proposals are deployed using a single cloud, while multicloud cluster deployments are yet to be studied. The simultaneous use of different cloud providers to deploy computing cluster spanning different clouds can provide several benefits.. High availability and fault tolerance: the cluster worker nodes can be spread on different cloud sites, so ecase of cloud downtime or failure, the cluster operation will not be disrupted. Furthermore, in this situation, we can dynamically deploy new cluster n nodes in a different cloud to avoid the degradation of the cluster performance . Infrastructure cost reduction: since different cloud providers can follow different pricing strategies, and even variable pricing models (based on the level of demand of a particular resource type, daytime versus night time, weekdays versus weekends, spot prices, and so forth), the different cluster nodes can change dynamically their locations, from one cloud provider to another one, in order to reduce the overall infrastructure cost. The main goal of this work is to analyze the viability, from the point of view of scalability, performance, and cost of deploying large virtual cluster infrastructures distributed over different cloud providers for solving loosely coupled MTC applications. This work is conducted in a real experimental test bed that comprises resources from ourin-house infrastructure, and external resources from three different cloud sites: Amazon EC2 (Europe and US zones1) and Elastic Hosts [5]. On top of this distributed cloud infrastructure, we have implemented a Sun Grid Engine(SGE) cluster, consisting of a front end and a variable number of worker nodes, which can be deployed on different sites (either locally or in different remote clouds) We analyze the performance of different cluster configurations, using the cluster throughput (i.e., completed jobs per second) as performance metric, proving that multicloud cluster implementations do not incur in performance slowdowns, compared to single-site implementations, and showing that the cluster performance (i.e., throughput) scales linearly when the local cluster infrastructure is complemented with external cloud nodes. In addition, we quantify the cost of these cluster configurations, measured as the cost of the infrastructure per time unit, and we also analyze the performance/cost ratio, showing that some cloud-based configurations exhibit similar performance/cost ratio than local clusters. |
| Due to hardware limitations of our local infrastructure, and the high cost of renting many cloud resources for long periods, the tested cluster configurations are limited to a reduced number of computing resources (up to 16 worker nodes), running a reduced number of tasks (up to 128 tasks).However, as typical MTC applications can involve much more tasks, we have implemented a simulated infrastructure model, that includes a larger number of computing resources (up to 256 worker nodes), and runs a larger number of tasks (up to 5,000). The simulation of different cluster configurations shows that the performance and cost results can be extrapolated to large-scale problems and cluster infrastructures. More specifically, the contributions of this work are the following: |
 |
| 1. Deployment of a multicloud virtual infrastructure spanning four different sites: our local data center, Amazon EC2 Europe, Amazon EC2 US, and Elastic Hosts; and implementation of a real computing cluster test bed on top of this multicloud infrastructure. |
 |
| 2. Performance analysis of the cluster test bed for solving loosely coupled MTC applications (in particular, an embarrassingly parallel problem), proving the scalability of the multicloud solution for this kind of workloads. |
| 3. Cost and cost-performance ratio analysis of the experimental setup, to compare the different cluster configurations, and proving the viability of the multicloud solution also from a cost |
DEPLOYMENT OF A MULTI CLOUD VIRTUALCLUSTER
|
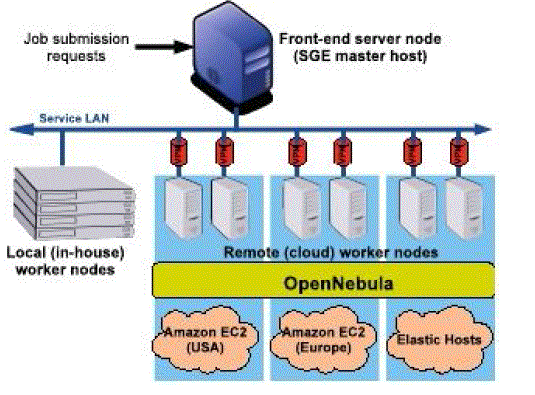
| Fig. 1 shows the distributed cluster tes tbed used in this work deployed of top of a multicloud infrastructure. This kind of multicloud deployment involves several challenges, related to the lack of a cloud interface standard; the distribution and management of the service master images; |
| and the interconnection links between the service components. A brief discussion of these issues, and the main design decisions adopted in this work to face up these challenges are included in Appendix A of the supplemental material, which can be found on the Computer Society Digital Libraryat p://doi.ieeecomputersociety.org/ 10.1109/TPDS.2010.186.Our experimental test bed starts from a virtual cluster deployed in our local data center, with a queuing system managed by SGE software, and consisting of a cluster frontend (SGE master) and a fixed number of virtual worker nodes (four nodes in this setup). This cluster can be scaled out by deploying new virtual worker nodes on remote clouds. The cloud providers considered in this work are Amazon EC2 (Europe and US zones) and Elastic Hosts. Table 1 shows the main characteristics of in-house nodes and cloud nodes used in our experimental test bed. Besides the hardware characteristics of different test bed nodes, Table 1 also displays the cost per time unit of these resources. In the case of cloud resources, this cost represents the hourly cost charged by the cloud provider for the use of its resources.2 Appendix B.1 of the supplemental material, which can be found on the Computer Society Digital TPDS.2010.186, gives more details about the cost model used for cloud resources. On the other hand, the cost of the local resources is an estimation based on the model proposed by Walker [6] that takes into account the cost of the computer hardware, the cooling and power expenses, and support personnel. For more information about the application of this cost model to our local data center, see Appendix B.2, which can be found on the Computer Society Digital Library at http://doi.ieeecomputersociety.org/ 10.1109/TPDS.2010.186.2.1 Performance Analysis In this section, w analyze and compare the performance offered by different configuration of the computing cluster, focused in the execution of loosely coupled applications. In particular, we have chosen nine different cluster configurations (with different number of worker nodes from the three cloud providers), and different number of jobs (depending on the cluster size), as shown in Table 2. In the definition of the different cluster configurations, we use the following acronyms: L: local infrastructure; AE: Amazon EC2 Europe cloud; AU: Amazon EC2 US cloud; and EH: Elastic Hosts cloud. The number preceding the site acronym represents the number of worker nodes. For example, 4L is a cluster with four worker nodes deployed in the local infrastructure; and 4L þ 4AE is a eight-node cluster, four deployed in the local infrastructure and four in Amazon EC2 Europe. To represent the execution profile of loosely coupled applications, e will use the Embarrassingly Distributed (ED)benchmark from the Numerical Aerodynamic Simulation(NAS) Grid Benchmarks [7] (NGB) suite. The ED benchmark consists of multiple independent runs of a flow solver, each one with a different initialization constant for the flow field.NGB defines several problem sizes (in terms of mesh size, iterations, and number of jobs) as classes S, W, A, B, C,D, and E. We have chosen a problem size of class B, since it is appropriate (in terms of computing time) for middle-class resources used as cluster worker nodes. However, instead of submitting 18 jobs, as ED class B defines, we have submitted a higher number of jobs (depending on the cluster configuration, see Table 2) in order to saturate the cluster and obtain realistic throughput measures. As we have proven in a previous work [8], when executing loosely coupled high-throughput computing applications, the cluster performance (in jobs completed per second) can be easily model using the following equation: rðn |
| Þ ¼ |
| r1 |
| 1 þ n1=2=n |
| ; ð1Þ |
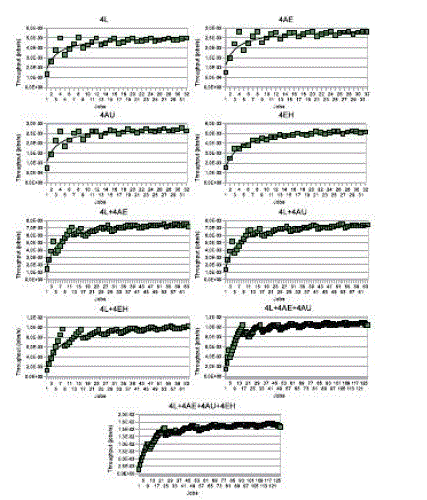
| where n is the number of jobs completed, r1 is the asymptotic performance (maximum rate of performance of the cluster in jobs executed per second), and n1=2 is the half-performance length. For more details about this performance model, see Appendix C of the supplemental material, which can be found on the Computer Society Digital Library at http://doi.ieeecomputersociety.org/10.1109/TPDS.2010.186. fig.2 shows the experimental cluster performance and from these plots,the performance model defined in (1) provides a goodcharacterization of the clusters in the execution of theworkload under study. |
TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, VOL.
|
| Characteristics of Different Cluster Nodes Cluster Configurations Fig. 2. Throughput for different cluster configurations |
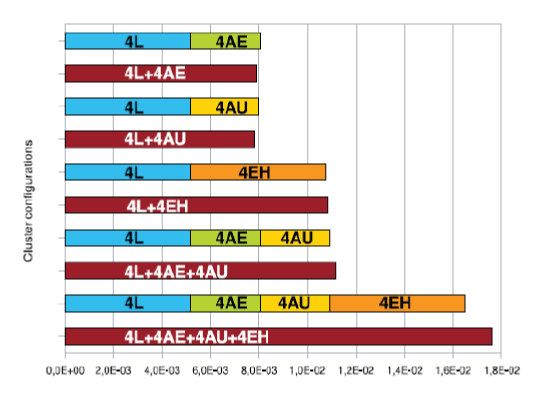 |
| Table 3 shows the r1 and n1=2 parameters of the performance model for each cluster configuration. The parameter r1 can be used as a measure of cluster throughput, in order to compare the different cluster configurations, since it is an accurate approximation for the maximum performance (in jobs per second) of the cluster in saturation. Please, note that we have achieved five runs of each experiment, so data in Table 3 represent the mean values of r1 and n1=2 (standard deviations can be found in on the Computer SocietyIf we compare 4Land 4EH configurations, we observethat they exhibit very similar performance. This is because of two main reasons: first, worker nodes from both sites have similar CPU capacity (see Table 1); and second, communication latencies for this kind of loosely coupled applications do not cause significant performance degradation, since data transfer delays are negligible compared to execution times, mainly thanks to the NFS file data caching implemented on the NFS clients (worker nodes), which notably reduces the latency of NFS read operations. On the other hand, the lower performance of 4AE and 4AU configurations is mainly due to the lower CPU capacity of the Amazon EC2 worker nodes (see Table 1). An important observation is that cluster performance for hybrid configurations scales linearly. For example, if we observe the performance of 4L þ 4AE configuration, and we compare it with the performance of 4L and 4AE configurations separately, we find that the sum of performances of these two individual configurations is almost similar to the performance of 4L þ 4AE configuration. This observation is applicable to all of the hybrid configurations, as shown in Fig. 3. This fact proves that, for the particular workload considered in this work, the use of a multicloud infrastructure spanning different cloud providers is totally viable from the point of view of performance and scalability, and does not introduce important overheads, which could cause significant performance degradation. |
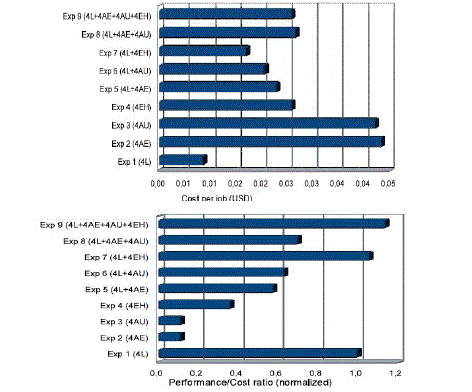
| 2.2 Cost Analysis Besides the performance analysis, the cost of cloud resources also has an important impact on the viability of the multicloud solution. From this point of view, it is an important to analyze, not only the total cost of the infrastructure, but also the ratio between performance and cost, in order to find the most optimal configurations. The average cost of each instance per time unit is gathered in Table 1. Based on these costs, and using the cost model detailed in Appendix B of the supplemental material, which can be found on the Computer Society Digital Library at http://doi.ieeecomputersociety.org/10.1109 |
 |
| Fig. 3. Asymptotic performance (r1) comparison. |
| TPDS.2010.186, we can estimate the cost of every experiment. However, this cost is not suitable to compare the different cluster configurations, since we are running different number of jobs for every configuration. So, in order to normalize the cost of different configurations, we have computed the cost per job, shown in Fig. 4, by dividing the cost of each experiment by the number of jobs in the experiment. As the cost of local resources is lower than the cloud resources, it is obvious that 4L configuration results in the experiment with the lowest cost per job. Similarly, those experiments including only cloud nodes (e.g., 4AE,4AU, and 4EH) exhibit higher price per job than those hybrid configurations including local and cloud nodes (e.g.,4L þ 4AE, 4L þ 4AU, and 4L þ 4EH). We also observe that, for the particular workload used in this experiment, configurations including EH nodes result in a lower cost per job than those configurations including Amazon node(e.g., 4EH compared to 4AE and 4AU, or 4L þ 4EH compared to 4L þ 4AE and 4L þ 4AU). Regarding these comparative cost results, it is obvious that, for large organizations that make intensive use of computational resources, the investment on a right-sized MORENO-VOZMEDIANO ET AL.: MULTICLOUD DEPLOYMENT OF COMPUTING CLUSTERS FOR LOOSELY COUPLED MTC APPLICATIONS Performance Model Parameters Fig. 4. Cost per job for different configurations. Only consider a single cloud, and they do not take advantage of the potential benefits of multicloud deployments. Regarding the use of |
 |
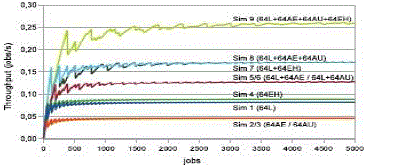
| multiple clouds, Keahey et al. introduce in [19] the concept of “Sky Computing,” which enables the dynamic provisioning of distributed domains over several clouds, and discusses the current shortcomings of this approach, such as image compatibility among providers, need of standards at API level, need of trusted networking environments, etc. This work also compares the performance of two virtual cluster deployed in two settings: single-site deployment and a three-site deployment, and concludes that the performance of a single-site cluster can be sustained using a cluster across three sites. However, this work lacks a cost analysis and the performance analysis is limited to small size infrastructures (up to 15 computer instances, equivalent to 30 processors).the real test bed can also be extrapolated to larger clusters, namely, hybrid configurations including local and cloud nodes (e.g., 64L þ 64AE, 64L þ 64AU, and 64L þ 64EH)exhibit lower cost per job than those configurations with only cloud nodes (e.g., 64AE, 64AU, and 64EH); and configurations including EH nodes result in a lower cost per job than configurations including Amazon nodes (e.g.,64EH compared to 64AE and 64AU, or 64L þ 64EH compared to 64L þ 64AE and 64L þ 64AU). Finally, analyzing the performance-cost ratio of the simulated infrastructures inFig. 8, we see again a similar behaviour to that observed for the real test bed, with some hybrid configurations (64L þ 64EH,and 64L þ 64AE þ 64AU þ 64EH) exhibiting better performance-cost ratio than the local setup (64L). |
RELATED WORKS
|
| Efficient management of large-scale cluster infrastructures has been explored for years, and different techniques for ondemand provisioning, dynamic partitioning, or cluster virtualization have been proposed. Traditional methods for the on-demand provision of computational services consist in overlaying a custom software stack on top of an existing middleware layer. For example, the MyCluster Project ]creates a Condor or a SGE cluster on top of Tera Grid services. The Falkon system [10] provides a light high throughput execution environment on top of the Globus GRAM service. Finally, the Grid Way meta scheduler [11] has been used to deploy BOINC networks on top of the EGEE middleware. The dynamic partitioning of the capacity of a computational cluster has also been addressed by several projects. For example, the Cluster On Demand software [12] enables rapid, automated, on-the-fly partitioning of a physical cluster into multiple independent virtual clusters. Similarly, the VIO cluster [13] project enables to dynamically adjust the capacity of a computing cluster by sharing resources between peer domains. Several studies have explored the use of virtual machines to provide custom cluster environments. In this case, the clusters are usually completely build up of virtualized resources, as in the Globus Nimbus project [14], or the Virtual Organization Clusters (VOC) proposed in [15]. Some recent works [2], [3] have explored the use of cloud resources to deploy hybrid computing clusters, so the cluster combines physical, virtualized, and cloud resources. There are many other different experiences on deploying different kind of multitier services on cloud infrastructures, such as webservers [16], database appliances [17], or web service platforms[18], among others However, all these deployments only consider a single cloud, and they do not take advantage of the potential benefits of multi cloud deployments. Regarding the use of multiple clouds, Keahey et al.introduce in [19] the concept of “Sky Computing,” which enables the dynamic provisioning of distributed domains over several clouds, and discusses the current short comings of this approach, such as image compatibility among providers, need of standards at API level, need of trusted networking environments, etc. This work also compares the performance of two virtual cluster deployed in two settings: a single-site deployment and a three-site deployment, and concludes that the performance of a single-site cluster can be sustained using a cluster across three sites. However, this work lacks a cost analysis and the performance analyse is limited to small size infrastructures (up to 15 computer instances, equivalent to 30 processors). |
CONCLUSIONS AND FUTURE WORK
|
| In this paper, we have analyzed the challenges and viability of deploying a computing cluster on top of a multicloud infrastructure spanning four different sites for solving loosely coupled MTC applications. We have implemented a real test bed cluster (based on a SGE queuing system) that comprises computing resources from our in-house infrastructure, and external resources from three different clouds: Amazon EC2 (Europe and US zones) and Elastic Hosts .Performance results prove that, for the MTC workload under consideration (loosely coupled parameter sweep applications), cluster throughput scales linearly when the cluster includes a growing number of nodes from cloud providers. This fact proves that the multicloud implementation of a computing cluster is viable from the point of view of scalability, and does not introduce important overheads, which could cause significant performance degradation. On the other hand, the cost analysis shows that, for the workload considered, some hybrid configurations (includinglocal and cloud nodes) exhibit better performance-cost ratio than the local setup, so proving that the multicloud solution is also appealing from a cost perspective. In addition, we have also implemented a model for simulating larger cluster infrastructures. The simulation of different cluster configurations shows that performance and cost results can be extrapolated to large-scale problems and clusters. It is important to point out that, although the results obtained are very promising, they can differ greatly for other MTC applications with a different data pattern, synchronization requirement, or computational profile. The different cluster configurations considered in this work have been selected manually, without considering any scheduling policy or optimization criteria, with the main goal of analyzing the viability of the multicloud solution from the points of view of performance and cost. Although a detailed analysis and comparison of different scheduling strategies is out of the scope of this paper, and it is planned for further research, for the sake of completeness, Appendix F of the supplemental material, which can be found on the Computer Society Digital Library at http://doi.ieeecomputersociety. org/10.1109/TPDS.2010.186, presents some preliminary results on dynamic resource provisioning, in order to highlight the main benefits of multicloud deployments, such as MORENOVOZMEDIANO ET AL.: MULTICLOUD DEPLOYMENT OF COMPUTING CLUSTERS FOR LOOSELY COUPLED MTC APPLICATIONS 929Fig. 8. Perf.-cost ratio for simulated configurations. |
ACKNOWLEDGMENTS
|
| This research was supported by on sejer?´a de Education of Comunicated Madrid, Fondo Europeo de Desarrollo Regional,and Fondo Social Europeo through EDIANET Research Program S2009/TIC-1468; by inisterio de Ciencia e Innovacio´n of Spain through research grant TIN2009-07146 |
Tables at a glance
|
|
|
| |
References
|
- I. Raicu, I. Foster, and Y. Zhao, “Many-Task Computing for Grids and Supercomputers,” Proc. Workshop Many-Task Computing on ridsandper computers, pp. 1-11, 2008.
- Bio Team “Howto: Unicluster and Amazon EC2,” technical report, Bio Team Lab Summary, 2008.
- I. Llorente, R. Moreno-Vozmediano, and R. Montero, “Cloud Computing for On-Demand Grid Resource Provisioning,” Advancesin Parallel Computing, vol. 18, pp. 177-191, IOS Press, 2009.
- Amazon ElasticcloudComputehttp://aws.amazon.com/ec2,2010.
- ElasticHoststtp://www.elastichosts.com/, 2010.
- E. Walker, “The Real Cost of a CPU Hour,” Computer, vol. 42,no. 4, pp. 35-41, Apr. 2009.
- M.A. Frumkin and R.F. Van der Wijngaart, “NAS Grid Benchmarks:A Tool for Grid Space Exploration,” J. Cluster Computing,vol. 5, no. 3, pp. 247-255, 2002.
- R.S. Montero, R. Moreno-Vozmediano,andI.M.Llorente,“AnElasticity Model for High Throughput Computing Clusters,” to be published in J. Parallel and Distributed Computing, doi: 10.1016/ j.jpdc.2010.05.005, 2010.
- E. Walker, J. Gardner, V. Litvin, and E. Turner, “CreatingPersonal Adaptive Clusters for Managing Scientific Jobs in aDistributed Computing Environment,” Proc. IEEE Second Int’l Workshop Challenges of Large Applications in Distributed Environments (CLADE ’06)
- I. Raicu, Y. Zhao, C. Dumitrescu, I. Foster, and M. Wilde, “Falkon: A Fast and Light-Weight TasKExecutiONarmework”Proc.IEEE/ACM Conf. SuperComputing, 2007.
- E. Huedo, R.S. Montero, and I.M. Llorente, “The GridWay Framework for Adaptive Scheduling and Execution on Grids,”Scalable Computing—Practice and Experience, vol. 6, pp. 1-8, 2006.
- J. Chase, D. Irwin, L. Grit, J. Moore, and S. Sprenkle, “DynamicVirtual Clusters in a Grid Site Manager,” Proc. 12th IEEE Symp.High Performance Distributed Computing, 2003.
- P. Ruth, P. McGachey, and D. Xu, “VioCluster: Virtualization forDynamic Computational Domains,” Proc. IEEE Int’l Conf. Cluster Computing, 2005.
- I. Foster, T. Freeman, K. Keahey, D. Scheftner, B. Sotomayor, andX. Zhang, “Virtual Clusters for Grid Communities,” Proc. Sixth IEEE Int’l Symp. Cluster Computing and the Grid, 2006.
- M. Murphy, B. Kagey, M. Fenn, and S. Goasguen, ynamic Provisioning of Virtual Organization Clusters,” Proc. Ninth IEEE Int’l Symp. Cluster Computing and the Grid, 2009.
- J. Fronckowiak, “Auto-Scaling Web Sites Using Amazon EC2 and Scalr,” Amazon EC2 Articles and Tutorials, 2008.
- A. Aboulnaga, K. Salem, A. Soror, U. Minhas, P. Kokosielis, and S.Kamath, “Deploying Database Appliances in the Cloud,” Bull. Of the IEEE Computer Soc. Technical Committee on Data Eng., vol. 32, no. 1, pp. 13-20, 2009.
- A. Azeez, Autoscaling Axis2 Web Services on Amazon EC2: ApacheCon Europe, 2009.
- K. Keahey, M. Tsugawa, A. atsunaga, and J. Fortes, “Sky Computing,” IEEE Internet Computing vol. 13, no. 5, pp. 43-51,Sept./Oct. 2009.Rafael Moreno-Vozmediano received the MSdegree in physics and the PhD degree from theUniversidad Complutense de Madrid (UCM),Spain, in 1991 and 1995, respectively. Since1997, he has been an associate professor ofcomputer science and electrical engineering atthe Department of Computer Architecture of theUCM, Spain. He has about 18 years ofresearch xperience in the fields ofhighperformance parallel and distributed computing,grid computing, and virtualization.Ruben S. Montero is an associate professor atthe Department of Computer Architecture in Complutense University of Madrid. Over the lastyears, he has published more than 70 scientificpapers in the field of highperformanceparallelanddistributedcomputing, and contributed tomore than 20 research and development programs.His research interests lie mainly inresource provisioning models for distributedsystems.
|