Keywords
|
| Semantic similarity, Symmetric non-negative matrix factorization, Multi-document summarization. |
INTRODUCTION
|
| Multi-document summarization is the process of generating a generic or topic-focused summary by reducing documents in size while retaining the main characteristics of the original documents. Since one of the problems of data overload is caused by the fact that many documents share the same or similar topics, multi-document summarization has attracted much attention in recent years. With the explosive increase of documents on the Internet, there are various summarization applications are used. For example, the informative snippets generation in web search can assist users in further exploring, and in a question-based system summary is required to provide information asked in the question. Another example is summaries for news groups in news services, which provide users to better understand the news articles in the group. |
| For handling multiple input document following are the problems1.Recognizing and coping with redundancy 2.Identifying important differences among document and 3.covering the informative content as much as possible. In this paper, to address these problems, we propose multi-document summarization based on cluster using sentence-level semantic analysis (SLSS), mixture model and symmetric non-negative matrix factorization (SNMF). |
| Since SLSS can better capture the relationships between sentences in a semantic manner, we use it to construct the sentence similarity matrix. Based on the similarity matrix, we perform the proposed mixture language model and SNMF algorithm to cluster the sentences. Finally we select the most informative sentences in each cluster considering both internal and external information. |
RELATED WORK
|
| Multiple document summarizations have been widely studied recently. The summary can be either generic or query specific. In a generic summary generation, the important sentences from the document are extracted and the sentences so extracted are arranged in the appropriate order. In a query specific summary generation, the sentences are scored based on the query given by the user. The highest scored sentences are extracted and presented to the user as a summary. Following are the two broad level classifications of text summarization techniques. |
| Extractive summarization and abstractive summarization. Extractive summarization usually ranks the sentences in the documents according to their scores calculated by a set of predefined features, such as term frequency inverse sentence frequency (TF-ISF) [20], sentence or term position [20], and number of keywords. Abstractive summarization involves information fusion, sentence compression and reformulation. In this paper, we study sentence-based extractive summarization. Gong et al. [22] propose a method using latent semantic analysis (LSA) to select highly ranked sentences for summarization. Proposes a maximal marginal relevance (MMR) method to summarize documents based on the cosine similarity between a query and a sentence and also the sentence and previously selected sentences. MMR method tends to remove redundancy, which is controlled by a parameterized model which actually can be automatically learned. Other methods include NMF-based topic specific summarization, CRF-based summarization, and hidden Markov model (HMM) based method. In addition, some graph-ranking based methods are also proposed [22]. Most of these methods ignore the dependency syntax in the sentence level and just focus on the keyword co-occurrence. Thus the hidden relationships between sentences need to be further discovered. The method proposed in group sentences based on the semantic role analysis, however the work does not make full use of clustering algorithms. In our work, we propose a new framework based on sentence-level semantic analysis (SLSS), mixture language model and symmetric non-negative matrix factorization (SNMF). SLSS can better capture the relationships between sentences in a semantic manner, mixture language model is used to measure the similarity between documents and SNMF can factorize the similarity matrix to obtain meaningful groups of sentences. |
PROPOSED METHOD
|
| 3.1 Overview: Figure 1 demonstrates the framework of our proposed approach. Given a set of documents which need to be summarized, first of all, we clean these documents by removing formatting characters. In the similarity matrix construction phase, we decompose the set of documents into sentences, and then parse each sentence into frame(s) using a semantic role parser. Pair wise sentence semantic similarity is calculated based on both the semantic role analysis [11] and word relation discovery using WordNet [20]. Section 3.2 will describe this phase in detail. Once we have the pairwise sentence similarity matrix, we perform the symmetric matrix factorization to group these sentences into clusters in the second phase. Full explanations of the proposed SNMF algorithm will be presented in section 3.3. Finally, in each cluster, we identify the most semantically important sentence using a measure combining the internal information (e.g., the computed similarity between sentences) and the external information (e.g., the given topic information). Section 3.4 will discuss the sentence selection phase in detail. These selected sentences finally form the summary. |
| 3.2 Semantic Similarity Matrix Construction: After removing stemming and stopping words, we trunk the documents in the same topic into sentences. Simple Word-matching types of similarity such as cosine can not faithfully capture the content similarity. Also the sparseness of words between similar concepts make the similarity metric uneven. Thus, we perform semantic role analysis on sentences and propose a method to calculate the semantic similarity between any pair of sentences. |
| 3.2.1 Sentence-level semantic analysis (SLSS): A semantic role is defined as “a description of the relationship that plays with respect to the verb in the sentence”. Each verb in the sentences is labelled with Argument and the verb which is labelled is called “frame”. Input to the SLSS algorithm is sentences Si and Sj. Assign labels to each verb in the sentences using Semantic role labler.After assigning label calculate the common semantic roles WordNet. Then to find role similarity between Tm(ri) and Tn(ri) as |
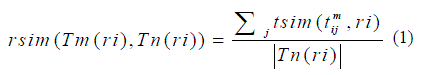 |
| Then, calculate the frame similarity between fm and fn is |
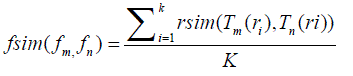 (2) (2) |
| Therefore, the semantic similarity between Si and Sj can be calculated As follows: |
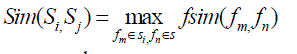 (3) (3) |
| Where similarity score is between zero and one. |
| Mixture Language Model and Symmetric nonnegative matrix factorization: Once we obtain the similarity matrix of the relevant cases, clustering algorithms need to be performed to group these cases into clusters |
| Mixture Language Model: Mixture language model [19] is used to measure the similarity between documents while filtering out the general and common information from the request. Mixture model measure is based on a novel view of how relevant documents are generated. We can also view it as a language model with a smoothing algorithm designed specifically for our task. |
| Figure 2 shows the Mixture language model in which input is sentence similarity matrix w. This document is mixture of three language models: A General English language model thetaE, a user-specific Request Model thetaT, and a document context Model thetaD. Each word wi in the document is generated by each of the three language models with probability lmdaE, lmdaT and lmdaD respectively. Then calculate probability and relevance score so mixture language model is used to measure the similarity between documents. By using mixture model, the effect of the words that occur frequently in the request or in general English on the similarity calculation is naturally reduced. |
| SNMF: We propose a new multi-document summarization framework based on sentence-level semantic analysis (SLSS) and symmetric non-negative matrix factorization(SNMF). SLSS is able to capture the semantic relationships between sentences and SNMF can divide the sentences into groups for extraction. It has been shown that SNMF is equivalent to kernel K-means clustering and is a special case of trifactor NMF. Another important property is that the simple SNMF is equivalent to the sophisticated normalized cut spectral clustering. Spectral clustering is a principled and effective approach for solving normalized cuts [38]. These results demonstrate the clustering ability of SNMF. |
| Within-Cluster Sentence Selection: After grouping the sentences into clusters by the SNMF algorithm, in each cluster, we rank the sentences based on the sentence score calculation . The score of a sentence measures how important a sentence is to be included in the summary. |
| where F1(Si) measures the average similarity score between sentence Si and all the other sentences in the cluster Ck, and N is the number of sentences in Ck. F2(Si) represents the similarity between sentence Si and the given topic T. λ is the weight parameter, which is set to 0.7 empirically. |
Module :
|
| 1. Pre-processing of customer request and past cases and Sentence-level semantic similarity calculation. |
| 2. Top-ranking case clustering using mixture model and SNMF algorithm. |
| 3. Multidocument summarization for each case cluster. |
EXPERIMENTAL RESULT
|
| To improve the usability of the system, we proposed sentence-level semantic analysis approach and SNMF clustering algorithm can be naturally applied to the summarization task to address the aforementioned issues. |
| 4.1 Case comparison: In this set of experiments, we randomly select five questions from different categories and manually label the related cases for each question. Then, we examine the top 10 retrieved cases by keyword-based Lucerne and our proposed system, respectively. Figure 6 and 7 show the average precision of the two methods. In figure 6, the high precision of multidocument summarization demonstrates that the semantic similarity calculation can better capture the meanings of the requests and case documents. In figure 7, we only look at the top 10 retrieved cases while some of the cases may have more than 20 relevant cases, the recall is also reasonable and acceptable. |
| 4.2 Result Analysis: In this section, we compare our proposed request-focused case-ranking results and Apache Lucene, which is one of the most popular keyword-based text-ranking engines. |
| Example1. Can I update my iPod music collection from more than one computer: The full representation of the abstract arguments of an illustrative example is shown in Table I. Table III shows the top-ranking case samples retrieved by Lucene and Multidocument summarization . For ranking results, we find that Lucene takes the word “iPod”, “Computer” as the keyword and return many cases related to them as the search result in list format as shown in figure 8.Obviously they are not what the customer want. |
| In our proposed system, Multi-document summarization provides the semantic meaning of request. We first calculate sentence-sentence similarities using semantic psychoanalysis and construct the similarity matrix. Then mixture language model and symmetric matrix factorization is used to group sentences into clusters for extraction. Finally, the informative sentences are selected from each group to form the summary. |
| The above graph shows the top score of our proposed system which is based on the sentence level semantic analysis. Existing system i.e Lucene system which is based on the keyword matching based ranking scheme for case retrieval and results will be in a list format. Our proposed system we search and rank the existing cases according to their relevance to users’ requests in a semantic way i.e. high top score gives the better result. |
CONCLUSION
|
| To improve the usability of the system, we perform multidocument summarization to generate a brief summary for each case cluster. In this paper we search and rank the existing cases according to their relevance to users’ requests in a semantic way and we provide a better result representation by grouping and summarizing the retrieved past cases to make the system fully functional and usable. The high performance of multidoument summarization based on cluster using sentence-level semantic analysis (SLSS), mixture model and symmetric non-negative matrix factorization (SNMF). |
Tables at a glance
|
|
|
Figures at a glance
|
 |
 |
 |
 |
 |
| Figure 1 |
Figure 2 |
Figure 3 |
Figure 4 |
Figure 5 |
 |
 |
 |
 |
 |
| Figure 6 |
Figure 7 |
Figure 8 |
Figure 9 |
Figure 10 |
|
References
|
- B. K. Giamanco, Customer service: The importance of quality customer service. [Online]. Available: http://www.ustomerservicetrainingcenter.com
- S. Agrawal, S. Chaudhuri, G. Das, and A. Gionis, “Automate ranking of database query results,” in Proc. CIDR, 2003, pp. 888–899.
- D.Wang, S. Zhu, T. Li, and C. Ding, “Multi-document summarization via sentence-level semantic analysis and symmetric matrix factorization,” inProc. SIGIR, 2008, pp. 307–314.
- K. Beyer, J. Goldstein, R. Ramakrishnan, and U. Shaft, “When is nearest neighbor meaningful?” in Proc. ICDT, 1999, pp. 217–235.
- D. Radev, E. Hovy, and K. McKeown, “Introduction to the special issue on summarization,” Comput. Linguist., vol. 28, no. 4, pp. 399–408, Dec. 2002.
- D. W. Aha, D. Mcsherry, and Q. Yang, “Advances in conversational case-based reasoning,” Knowl. Eng. Rev., vol. 20, no. 3, pp. 247–254, Sep. 2005.
- R. Agrawal, R. Rantzau, and E. Terzi, “Context-sensitive ranking”, in Proc. SIGMOD, 2006, pp. 383–394.
- A. Leuski and J. Allan, “Improving interactive retrieval by combining ranked list and clustering,” in Proc. RIAO, 2000, pp. 665–681.
- X. Liu, Y. Gong, W. Xu, and S. Zhu, “Document clustering with cluster refinement and model selection capabilities,” in Proc. SIGIR, 2002, pp. 191–198.
- R. Collobert and J.Weston, “Fast semantic extraction using a novel neural network architecture,” in Proc. ACL, 2007, pp. 560–567.
- M. Palmer, P. Kingsbury, and D. Gildea, “The proposition bank: An annotated corpus of semantic roles,” Comput. Linguist., vol. 31, no. 1, pp.71–106, Mar. 2005.
- C. Fellbaum, “WordNet: An Electronic Lexical Database”, in Cambridge, MA: MIT Press, 1998.
- X. Liu, Y. Gong, W. Xu, and S. Zhu, “Document clustering with cluster refinement and model selection capabilities,” in Proc. SIGIR, 2002, pp. 191–198.
- D. Radev, E. Hovy, and K. McKeown, “Introduction to the special issue on summarization,” Comput. Linguist., vol. 28, no. 4, pp. 399–408, Dec. 2002.
- Shi and J. Malik, “Normalized cuts and image segmentation,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 22, no. 8, Aug. 2000.
- D.W.Aha, D. Mcsherry, and Q. Yang, “Advances in conversational case-based reasoning,” Knowl. Eng. Sep. 2005.
- D. Bridge, M. H. Goker, L. Mcginty, and B. Smyth, “Case-based recommender systems,” Knowl. Eng. Rev., vol. 20, no. 3, pp. 315–320,Sep. 2005
- Dingding Wang, Tao Li, Shenghuo Zhu, and Yihon Gong,”iHelp: An Intelligent Online Helpdesk System” in IEEE TRANSACTIONS 2011
- Y. Zhang, J. Callan, and T. Minka, “Novelty and redundancy detection in adaptive filtering,” in Proc. SIGIR, 2002, pp. 81–88.
- Y. Gong and X. Liu.“Generic text summarization using relevance measure and latent semantic analysis”, in SIGIR 2001.
- R. Mihalcea and P. Tarau” A language independent algorithm for single and multiple document summarizations”, in IJCNLP 2005.
|