International Journal of Innovative Research in Computer and Communication Engineering
ISSN ONLINE(2320-9801) PRINT (2320-9798)
ISSN ONLINE(2320-9801) PRINT (2320-9798)
Priyanka V.Thakare, Prof. Anil Bende
|
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Innovative Research in Computer and Communication Engineering
In Computer vision, image segmentation is the process of partitioning a digital image into multiple segments, Human segmentation in photo images is a challenging and important problem. As computer vision researchers have increased attention in segmenting human from a given input image or a video. There are different techniques classified with respect to different approach of segmenting human i.e Exemplar based, part based and some other methods which are using different approaches like shape priors(CRF,MRF), ACF of segmenting human from photo images. In Exemplar approach, exemplar pool is created first and then test images are matched with the exemplars or models. Whereas in part based approach human body can be recovered by assembling set of candidate parts. Both of this approach is having some drawbacks so some other methods are developed for human segmentation. In this paper a straightforward framework to automatically recover human bodies from colour photos is proposed by employing coarse to fine strategy, first detect a coarse torso (CT) using multicue CT detection algorithm and then extract the accurate region of upper body. Then an iterative multiple oblique histogram algorithms is presented o accurately recover the lower body on human kinematics.
KEYWORDS |
| Graph cuts, human segmentation, multicue coarse torso detection algorithm (MCTD), multiple oblique histogram (MOH). |
I. INTRODUCTION |
| Segmentation partitions an image into distinct regions containing each pixel with similar attributes. To be meaningful and useful for image analysis and interpretation, the regions should strongly relate to depicted objects or features of interest. Image segmentation is typically used to locate objects and boundaries (lines, curves, etc.) in images. The purpose of segmentation is to simplify and/or change the representation of an image into something that is more meaningful and easier to analyze. |
| The result of image segmentation is a set of segments that collectively cover the entire image, or a set of contours extracted from the image. Each of the pixels in a region is similar with respect to some characteristic or computed property, such as color, intensity, or texture. Adjacent regions are significantly different with respect to the same characteristic(s).Image segmentation is the process of assigning a label to every pixel in an image such that pixels with the same label share certain characteristics. Image segmentation is the process of dividing an image into multiple parts. This is typically used to identify objects or other relevant information in digital images. |
| In this paper, a proposed robust framework is used to recover human body from photo images by integrating top– down body information and low-level visual cues into Graph Cuts frame-work. For human segmentation, there are multiple regions of body parts, such as head, torso, and legs in the image, as a result of large appearance variation. In this we divide whole-body is extracted into two subtasks, i.e., upper-body and lower-body segmentations. |
| A common approach that is utilized in this scheme to construct the foreground and background graphs containing the likelihood term of each node being foreground/background and the piecewise smoothness term indicating the pixels in the same region having the same labels. |
II. RELATED WORK |
| Most of the algorithms for recovering human body in a static image fall into two categories, i.e., exemplar-based and part-based approaches. |
A. EXEMPLAR-BASED APPROACH |
| An exemplar pool should be constructed first and then the test images are matched with the exemplars or models. As human poses are arbitrary that’s why these models not always accurately segment the human body. It is difficult to extend the method for human segmentation. It fails to cover all the situations of poses and appearance variation. |
| Exemplar based approach is proposed by different researchers. |
| Kohli et al. utilized pose-specific conditional random and stick figures for segmentation, as well as pose estimation of humans within a Bayesian framework, which has been successfully used in 3-D human pose tracking. Unlike Kumar et al., this approach does not require the laborious process of learning exemplars. Instead we use a simple articulated stickman model, which together with a CRF is used as our shape prior. The experimental results show that this model suffices to ensure human-like segmentations as shown in fig.1. The experimental results show that the segmentation results improve considerably as we increase the amount of information in our CRF framework. |
 |
| Fig.1:(a) Original image. (b) The ratios of the likelihoods of pixels being labeled foreground/background (c) The segmentation results (d) The stickman in the optimal pose .(e) The shape prior corresponding to the optimal pose of the stickman. (f) The ratio of the likelihoods of being labeled foreground/background using all the energy terms (g) The segmentation result obtained from our algorithm which is the MAP solution of the energy of the pose-specific CRF. |
| Lin et al. [2] proposes a hierarchical part-template matching approach for human detection and segmentation. The approach takes advantages of both local part-based and global template-based human detectors by decomposing global shape models and constructing a part-template tree to model human shapes efficiently as shown in fig.2. Edges are matched to the part-template tree efficiently to determine a reliable set of human detection hypotheses. Shape segmentations and poses are estimated automatically through synthesis of part detections. The set of detection hypotheses is optimized under a Bayesian MAP framework based on global likelihood re-evaluation and fine occlusion analysis. |
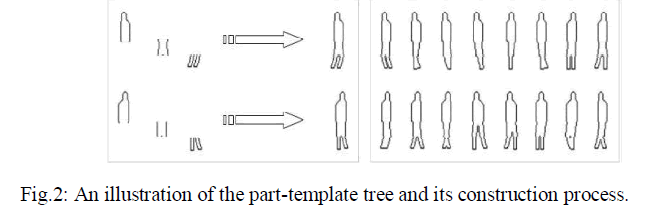 |
| Kumar et al. represents articulated object categories using a novel layered pictorial structures model. Non articulated object categories are model using a set of exemplars as shown in fig3. |
 |
| These models have the advantage that they can handle large intra-class shape, appearance and spatial variation. Thus we employed an efficient OBJCUT to obtain segmentation using our probabilistic framework. OBJCUT provides reliable segmentation by incorporating both: |
| (i) modelled deformations, using a set of exemplars model for non-articulated objects and the LPS model for articulated objects; and |
 |
| The results for non-articulated objects are shown for two categories: bananas and oranges. The OBJCUT algorithm is also tested on two articulated object categories: cows and horses as shown in fig.4. |
| ACF- Adaptive contour feature is proposed or human detection and segmentation but the results for human segmentation are rough, as the labeled samples are limited. |
| An interactive segmentation method that incorporates local Markov Random Fields and global shape priors to estimate segmentations and pose simultaneously is also proposed. Some utilized pose-specific conditional random and stick figures for segmentation, as well as pose estimation of humans within a Bayesian framework, which has been success- fully used in 3-D human pose tracking. |
| In this way Kumar and Torr drew a pictorial structure and Markov random fields (MRFs) together for detecting and segmenting instances of a particular object (e.g., cows and horses) but with a limited pose variation. This method has drawback is that, these models fails to accurately segment the human body, because of arbitrary human poses and an exemplar pool cannot cover all the situations of poses and appearance variation. |
B. PART BASED APPROACH |
| A different approach of segmenting human from photo images is part based approach. Part based approach is proposed by different researchers. |
| Mori et al. found salient half-limbs and torso by training part detectors with four main cues and Normalized Cuts. Hand-segmented limbs are used for training. However, Normalized Cuts usually do not accurately segment halflimbs and torso. The method proposed in this paper use the Normalized Cuts algorithm to group similar pixels into regions |
| The method proposed in this paper use the Normalized Cuts algorithm to group similar pixels into regions. Fig. 5(e) shows segmentation with 40 regions. Many salient parts of the body pop out as single regions, such as the legs and the lower arms. In addition, we use over-segmentation, as shown in Fig. 5(f), consisting of a large number of small regions or “super pixels”, which has been shown to retain virtually all structures in real images. These segmentations dramatically reduce the complexity of later stages of analysis, e.g., from 400K pixels to 200 super pixels. |
| This way we detect salient upper and lower limbs from these segments. Simultaneously we detect potential head and torso positions based on exemplars to detect the torso and for detecting head some set of cues, contour, shape and focus, are used to evaluate the score of a head. The shape model of the head is simply a disk, whose scale is determined by the candidate torso. Then combine these parts into partial body configurations and prune away impossible configurations by enforcing global constraints such as relative scale and symmetry in clothing. |
| In the final stage a complete partial configurations by combinational search in the space of superpixels to recover full body configurations. |
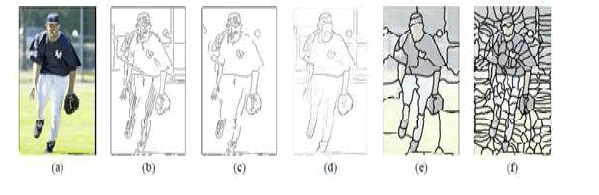 |
| Fig.5.(a)original image(b)(c)canny edge at different scales(d) pb(probability of boundary) image (e)Normalized cut with k=40 salient limbs pop out as single segments (f)”superpixel” map with 200 super-pixels |
| Thus for each test image, 61 images are used as the exemplars for matching. Results for this exemplar-based torso detector illustrates that this set of exemplars are unable to cope with the variation in appearance among the different players. |
| Ioffe et al. demonstrates probabilistic method for finding people. Since a reasonable model of a person requires at least nine segments, it is not possible to inspect every group, due to the huge combinatorial complexity. We propose two approaches to this problem. In one, the search can be pruned by using projected versions of a classifier that accepts groups corresponding to people. We describe an efficient projection algorithm for one popular classifier, and demonstrate that our approach can be used to determine whether images of real scenes contain people. |
| The second approach employs a probabilistic framework, so that we can draw samples of assemblies, with probabilities proportional to their likelihood, which allows us to draw human-like assemblies more often than the nonperson ones. The main performance problem is in segmentation of images, but the overall results of both approaches on real images of people are encouraging. |
III. PROPOSED ALGORITHM |
| The proposed algorithm is describe in below figure 6.It describe each step of algorithm |
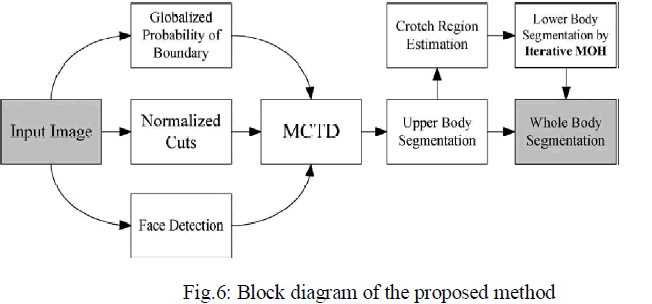 |
| a. Desription of the Proposed Algorithm: |
| Aim of Proposed method is to extract accurate human region by using a coarse-to-fine strategy which is employed to obtain the human shape constraints.Algorithm consist of four steps. |
| Step 1: Take an input image and perform face detection. |
| Select an image from dataset and perform an algorithm for detection of faces in an image. |
 |
| The basic problem to be solved is to implement an algorithm for detection of faces in an image. This can be solved easily by humans. However there is a stark contrast to how difficult it actually is to make a computer successfully solve this task. In order to ease the task an algorithm is used which limit themselves to full view frontal upright faces. That is, in order to be detected the entire face must point towards the camera and it should not be tilted to any side. The main characteristics of face detection algorithm which makes it a good detection algorithm are: |
| • Robust – very high detection rate (true-positive rate) & very low false-positive rate always. |
| • Real time – For practical applications at least 2 frames per second must be processed. |
| • Face detection and not recognition - The goal is to distinguish faces from non-faces (face detection is the first step in the identification process) |
| Step 2: Normalized Cuts: |
| To solve a perceptual grouping problem in vision, normalized cut approach is used to extract the global impression of an image. |
 |
| Step 3: Upper Segmentation: |
| The multicue coarse torso detection algorithm (MCTD) is utilized to segment the upper body that adjoins to head, in which the Normalized Cuts and global probability of boundary (gPb) are effectively combined. |
| Firstly use a face detection method to locate the human face from a given image. In addition to it, then, a coarse torso (CT) is detected by grouping Normalized Cuts segments. A pixel wise torso is then segmented using Graph Cuts. Torso is detected on dominant colors generated by using the k-means clustering algorithm. |
CT Detection |
| In this scheme, the Normalized Cuts segments are usually grouped into a torso candidate region based on the bounding box along with different orientations, where the bounding boxes are generated according to face priori. In the combining procedure, three cues are employed to select the best candidate as CT: area probability, location probability, and contour probability. |
| MCTD: Based on above three cues, the CT can be estimated with the MCTD algorithm. |
| By given a bounding box region Ri, first find all segments Si that are overlapped with Ri leaving the head region. For each segment unit in Ri, we compute the area and location probability ,which can be treated as local information |
| Pi,j = (APi,j)λ(LPi,j)1−λ |
| where parameter λ is the weighting term. The closer to the centre of the bounding-box region, the more likely the segment to be a component of torso |
| Then, the best group for the segments corresponding to |
| the ith bounding-box region and its counter probability are |
| selected by |
| CTi,k = CTi,k,ˆjïÿýïÿý{ˆjïÿýïÿý = arg maxˆj (CPi,k,ˆj )} |
| CPi,k = CPi,k,ˆjïÿýïÿý{ˆjïÿýïÿý = arg maxˆ (CPi,k,ˆj )} |
| Given a bounding box region, all segments that are overlapped with the bounding box region is found out without considering the head region. For each such segment, the area and location probability is computed. The closer to the center of the bounding box region, the segment is likely to be a component of torso. Once a segment is added to the torso region, the contour probability is computed and recomputed to constrain the unlimited increase in coarse torso. |
| Step 4: Lower Segmentation: |
| Lower body is segmented based on iterative multiple oblique histogram (MOH). |
| Lower body segmentation is more challenging than upper body segmentation; because the poses of legs are unpredictable. We separate the lower body from the scene, so the segmented upper body can be set to the background. An iterative MOH algorithm is used to obtain fine results. MOH is used to describe the projection information of the coarse lower body, which can be used to find the false negatives. Each bin of MOH represents multiple cues of coarse segment results: accumulation, span, number of line segments, and boundary points of figure/ground on each projection line. The accumulation refers to the number of all segmented pixels that divide the projection line into multiple segments in a given bin; and the span is defined as the length of a line segment. MOH can obtain the missed parts and judge the integrity of the lower body, so that it is used to update Graph Cuts seeds. |
IV. RESULT ANALYSIS |
| Data Set: We have collected real-world photo images, covering various individuals and appearance, different poses and illumination. Some samples are in below figure a) Background Contained Evaluation b) Overlap Evaluation |
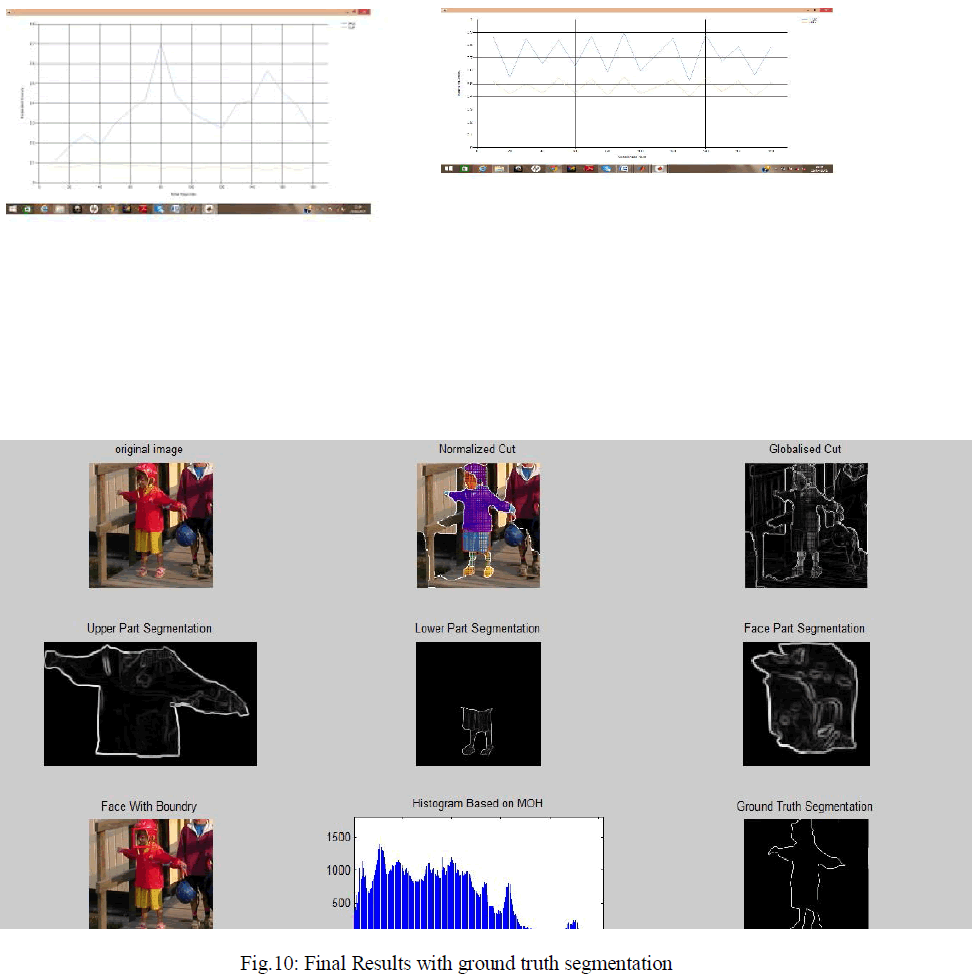 |
V. CONCLUSION AND FUTURE WORK |
| This paper has introduced a new an effective fine approach for segmentation to automatically recover human body in static photo image. The main purpose of this as follows: |
| i) Proposed a segmentation-based framework for recovering human body from a static image. |
| ii) To detect torso, we have MCTD. |
| iii) To recover lower-body segmentation, we have introduced a robust iterative MOH algorithm. |
| Future Work: |
| • The algorithm to deal with variable face orientations, even in the case that the face is not possible to be detected by general face detectors. |
References |
|