International Journal of Advanced Research in Electrical, Electronics and Instrumentation Engineering
ISSN ONLINE(2278-8875) PRINT (2320-3765)
ISSN ONLINE(2278-8875) PRINT (2320-3765)
V.Dileep Kumar1, M.V.Jagannatha Reddy2
|
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Advanced Research in Electrical, Electronics and Instrumentation Engineering
Progressive corpus is handled by storing the intermediate results of the processed data in the database tables (parse tree database) with the help of parse tree. So, that we can get the previous data as well as newly processed data with this we can reduce the reprocessing and minimizes the time. The drawback of such system is when ever user searches of the query it searches based on the tree based search which looks for the exact data and retrieves only the matching content with this we can’t get the semantic data. To overcome this we propose WordNet based tree to handle the incremental corpus which stores the intermediate results in the tables and searches the query based on the phrase based search which retrieves the accurate results and displays the corresponding document names.
Keywords |
| Text Mining, Query Language, Information Storage and Retrieval, sematic search |
INTRODUCTION |
| In this paper, we propose an effective and adjustable The optimization of queries is critical in database management systems and the complexity involved in finding optimal solutions has led to the development of heuristic approaches. Answering data mining query involves a random search over large databases. Due to the enormity of the data set involved, model simplification is necessary for quick answering of data mining queries. In this paper, we propose a hybrid model using rough sets and genetic algorithms for fast and efficient query answering. Rough sets are used to classify and summarize the datasets, whereas genetic algorithms are used for answering association related queries and feedback for adaptive classification. Here, we consider three types of queries, i.e., select, aggregate and classification based data mining queries. The field of information extraction (IE) seeks to develop methods for fetching structured information from natural language text. Examples of structured information are the extraction of entities and relationships between entities. IE is typically seen as a one-time process for the extraction of a particular kind of relationships of interest from a document collection. [1]IE is usually deployed as a pipeline of special-purpose programs, which include sentence splitters, tokenizes, named entity recognizers, shallow or deep syntactic parsers, and extraction based on a collection of the development of frameworks such as UIMA and GATE , providing a way to perform extraction by defining workflows of components. This type of extraction frameworks is usually file based and the processed data can be utilized between components. In this traditional setting, relational databases are typically not involved in the extraction process, but are only used for storing the extracted relationships. While file-based frameworks are suitable for one-time extraction, it is important to notice that there are cases when IE has to be performed repeatedly even on the same document collection. Consider a scenario where a named entity recognition component is deployed with an updated ontology or an improved model based on statistical learning. Typical extraction frameworks would require the reprocessing of the entire corpus with the improve identity recognition component as well as the other unchanged text processing components. Such reprocessing can be computationally intensive and should be minimized. In this paper, we propose a new paradigm for information extraction. In this extraction framework, intermediate output of each text processing component is stored so that only the improved component has to be deployed to the entire corpus. Extraction is then performed on both the previously processed data from the unchanged components as well as the updated data generated by the improved component. Performing such kind of incremental extraction can result in a tremendous reduction of processing time. To realize this new information extraction framework, we propose to choose database management systems over file-based storage systems to address the dynamic extraction needs. Our proposed information extraction is com- posed of two phases: |
| Initial Phase We perform a one-time parse, entity recognition, and tagging (identifying individual entries as belonging to a class of interest) on the whole corpus based on the current knowledge. The generated syntactic parse trees and semantic entity tagging of the processed text is stored in a relational database, called parse tree database (PTDB). |
| Extraction Phase Extraction is then achieved by issuing database queries to PTDB. To express extraction patterns, we designed and implemented a query language called parse tree query language (PTQL) that is suitable for generic extraction. Note that in the event of a change to the extraction goals (e.g., the user becomes interested in new types of relations between entities) or a change to an extraction module (e.g., an improved component for named entity recognition becomes available), the responsible module is deployed for the entire text corpus and the processed data are populated into the PTDB. Queries are issued to identify the sentences with newly recognized mentions. Then extraction can be performed only on such affected sentences rather than the entire corpus. Thus, we achieve incremental extraction, which avoids the need to reprocess the entire collection of text unlike the file-based pipeline approaches. Using database queries instead of writing individual special-purpose programs, information extraction becomes generic for diverse applications and becomes easier for the user. However, writing such queries may still require many users effort. To further reduce users’ learning burden, we propose algorithms that can automatically generate PTQL queries from training data or a user’s keyword queries. We highlight the contributions of this paper. Novel Database Centric Framework for Information Extraction. Unlike the traditional approaches, where IE is achieved by special-purpose programs and databases are only used for storing the extraction results, we propose to store intermediate text processing output in a database, parse tree database. This approach minimizes the need of reprocessing the entire collection of text in the presence of new extraction goals and deployment of improved processing components. Query Language for Information Extraction. Information extraction is expressed as queries on the parse tree database. As query languages such as XPath and XQuery are not suitable for extracting linguistic patterns [6], we designed and implemented a query language called parse tree query language, which allows a user to define extraction patterns on grammatical structures such as constituent trees and linkages. Since extraction is specified as queries, a user no longer needs to write and run special- purpose programs for each specific extraction goal. . Automated Query Generation. Learning the query language and manually writing extraction queries could still be a time-consuming and labor-intensive process. Moreover, such an ad hoc approach is likely to cause unsatisfactory extraction quality. To further reduce a user’s effort to perform information extraction, we design two algorithms to automatically generate extraction queries, in the presence and in the absence of training data, respectively. |
| Information Extraction IE has been an active research area that seeks techniques to uncover information from a large collection of text. Examples of common IE tasks include the identification of entities (such as protein names), extraction of relationships between entities (such as interactions between a pair of proteins) and extraction of entity attributes (such as co reference resolution that identifies variants of mentions corresponding to the same entity) from text. The examples and experiments used in our paper involve the use of grammatical structures for relationship extraction. Co occurrences of entities are a typical method in relationship extraction, but often lead to imprecise results. Consider that our goal is to extract relations between drug and proteins from the following sentence: Quetiapine is metabolized by CYP3A4 and sertindole by CYP2D6. (PMID: 10422890) By utilizing our grammatical knowledge, a human reader can observe that hCYP3A4, metabolize, quetiapinei and hCYP2D6, metabolize, sertindolei are the only correct triplet relations for the above sentence. However, if we consider co occurrences of entities as a criteria to extract relationships, incorrect relationships such as hCYP3A4, metabolize, sertindolei and hCYP2D6, metabolize, quetiapinei would also be extracted from the above sentence. |
DEVELOPMENT ENVIRONMENT |
| Module I: In the first module the documents contain sentences. The sentences are in the unstructured manner. The module converts sentences to structured sentences with index. This process is applied on the existing corpus. |
| Module II: In this module each sentence of a document is made up with different words. |
| Example: S1={w1,w2,w3…….wn} |
| The module splits all the indexed sentences by words. |
| Module III: In this module, the words will be presented in the document in different forms such as present, past, future etc…The words has to be n-grammed to find out the possible equivalence of root words. The root words can be grouped together (or) clustered for special group of interests. |
| Example: {“cricket”, “football”} can be grouped together to a special interests called “sports” category. Identifying group of words of similar category can have relationship. Building the relational words together is called word-net. |
| Module IV: The word-net is a semantic relational network. The word-net is store in the database as PTDB. The module provides an interface to the user to search the PTDB of the corpus. The user’s query will be in the form of natural language (or) can be with stop words. |
| Module V: In this module, user’s query has to be preprocessed against stop words elimination. The query words has to be n-grammed for possible root words. |
| Module VI: In this module, all the n-grammed words may not be the root words. Find out the possible root words for each query word. Find the semantically words for each word of query root word. Find the appropriate Tag with their relevancies (or) Frequencies. |
THE PROPOSED WORK |
| The proposed method uses the WordNet tree to handle the incremental corpus and to reduce the processing time. This helps user to get the exact document based on the query given by the user. It converts the user query into tagged values based on the post-tagger and retrieves the documents based on the query-post-tagger which assigns the tagged values to each word based on post-tagger program. When user enters the query it matches with the tagged values and gets the corresponding documents or file names. WordNet tree searches based on the phrase based search which can retrieves the semantic data and minimizes the place by placing the corresponding tagged values under the same tagged value. When user searches for the word home it gets all it synonyms under this word and tags under the word home. We place all the documents that need to process to extract the information in one place and create index for all the documents by eliminating the stopping words i.e., words which contains the word count less than three and obtain unique words from this indexed table. We have to create tagged values to this unique words using post-tagger batch file which assigns tagged values to each word and store these extracted information in the tables called parse tree database(PTDB) with the help of parse tree. |
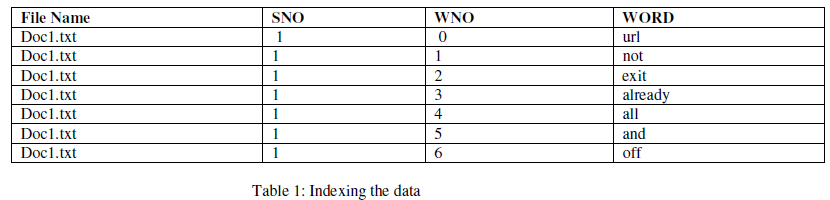 |
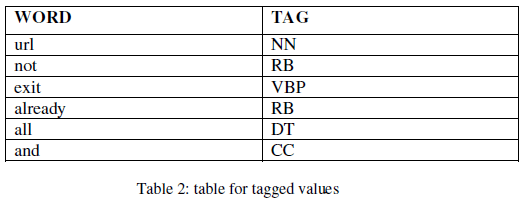 |
RELATED WORK |
| The main focus so far has been on improving the accuracy and runtime of information extractors. But recent work has also started to consider how to manage such extractors in large-scale IE-centric applications. Our work fits into this emerging direction, which is described. While we have focused on IE over unstructured text, our work is related to wrapper construction, the problem of inferring a set of rules (encoded as a wrapper) to extract information from template-based Web pages. Since wrappers can be viewed as extractors (as defined in Section 3), our techniques can potentially also apply to wrapper contexts. In this context, the knowledge of page templates may help us develop even more efficient IE algorithms. Our work is also related to the problem of wrapper maintenance over evolving Web data. The focus there, however, is on how to repair a wrapper (i.e., an extractor) so that it continues to extract semantically correct data, as the underlying page template changes. In contrast, we focus on efficiently reusing past extraction efforts to reduce the overall extraction time. The problem of finding overlapping text regions is related to detecting duplicated Web pages. Many algorithms have been developed in this area. But when applied to our context they do not guarantee to find all largest possible overlapping regions, in contrast to the suffix-tree based algorithm developed in this work. Once we have extracted entity mentions, we can perform additional analysis, such as mention disambiguation. Thus, such analyses are higher level and orthogonal to our current work. Numerous rule-based extractors and learning-based extractors have been developed. Delex can handle both types of extractors Much work has tried to improve the accuracy and runtime of these extractors. But recent work has also considered how to combine and manage such extractors in large-scale IE applications. Our work fits into this emerging direction. In terms of IE over evolving text data, Cyclex is the closest work to ours. But Cyclex is limited in that it considers only IE programs that contain a single IE blackbox, as we have discussed. Also considers evolving text data, but in different problem contexts. They focus on how to incrementally update an inverted index, as the indexed Web pages change. Recent work has also exploited overlapping text data, but again in different problem contexts. These works observe that document collections often contain overlapping text. They then consider how to exploit such overlap to “compress” the inverted indexes over these documents, and Cimple Project. First, our inputs are text documents instead of tables. Most work on view maintenance assumes that changes to the inputs (base tables) are readily available (e.g., from database logs), while we also face the challenge of how to characterize and efficiently detect portions of the input texts that remain unchanged. Most importantly, view maintenance only needs to consider a handful of standard operators with well-defined semantics. In contrast, we must deal with arbitrary IE black boxes. These efforts however have considered only static corpus contexts, not dynamic ones as we do in this paper. |
| Applications |
| Structure extraction is useful in a diverse set of applications. We list a representative subset of these, categorized along whether the applications are enterprise, personal, scientific, or Web-oriented. |
| i. Enterprise Applications |
| News Tracking: A classical application of information extraction, which has spurred a lot of the early research in the NLP community, is automatically tracking specific event types from news sources. |
| Personal Information Management |
| Personal information management (PIM) systems seek to organize personal data like documents, emails, projects and people in a structured inter-linked format. The success of such systems will depend on being able to automatically extract structure from existing predominantly file-based unstructured sources. Thus, for example we should be able to automatically extract from a PowerPoint file, the author of a talk and link the person to the presenter of a talk announced in an email. Emails, in particular, have served as testbeds for many extraction tasks such as locating mentions of people names and phone numbers, and inferring request types in service centers. |
RESULTS |
| Thus we showed that we can retrieve the document file names based on the user query and the query searches based on the phrase based search and retrieves semantic data. We can get progressive corpus without extraction from scratch by storing the intermediate results in the table and retrieve the document by using PTQL query. |
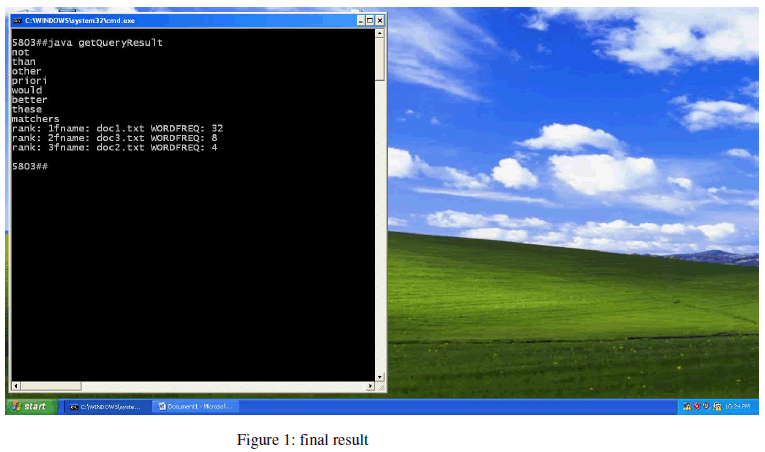 |
CONCLUSION |
| In this section, we discuss the main contributions of our work as well as their limitations. |
| Extraction framework: Existing extraction frameworks do not provide the capabilities of managing intermediate processed data such as parse trees and Semantic information. This leads to the need of reprocessing of the entire text collection, which can be computationally expensive. On the other hand, by storing the intermediate processed data as in our novel framework, introducing new knowledge can be issued with simple SQL insert statements on top of the processed data. With the use of parse trees, our framework is most suitable for performing extraction on text corpus written in natural sentences such as the biomedical literature. In the case when the parser fails to generate parse tree for a sentence, our system generates a “replacement parse tree” that has the node STN as the root with the words in the sentence as the children of the root node. This allows PTQL queries to be applied to sentences that are incomplete or casually written, which can appear frequently in web documents. Features such as horizontal axis and proximity conditions can be most useful for performing extraction on replacement parse trees. . Parse tree query language. One of the main contributions of our work is PTQL that enables information extraction over parse trees . While our current focus is per-sentence extraction, it is important to notice that the query language itself is capable of defining patterns across multiple sentences. By storing documents in the form of parse trees, in which the node DOC is represented as the root of the document and the sentences represented by the nodes STN as the descendants. PTQL has the ability to perform a variety of information extraction tasks by taking advantage of parse trees unlike other query languages. Currently, PTQL lacks the support of common features such as regular expression as frequently used by entity extraction task. For future work, we will extend the support of other parsers by providing wrappers of other dependency parsers and scheme, such as Pro3Gres and the Stanford Dependency scheme, so that they can be stored in PTDB and queried using PTQL. We will expand the capabilities of PTQL, such as the support of regular expression and the utilization of redundancy to compute confidence of the extracted information. |
References |
|