International Journal of Innovative Research in Computer and Communication Engineering
ISSN ONLINE(2320-9801) PRINT (2320-9798)
ISSN ONLINE(2320-9801) PRINT (2320-9798)
| Hridesh Gupta1, Pankaj Sharma2 |
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Innovative Research in Computer and Communication Engineering
Microblogging is a very common mode of communication among internet users. Microblogs are real time content published by people and this content is generally laden with personal opinions about a variety of aspects in everyday life. This makes microblogs a rich source of data for opinion mining. We use a corpus from the popular microblogging website, Twitter [1]. We consider microblogs from the period before the Prime minister’s elections in India in 2014 to analyze the collective sentiment of the microbloggers, against and in favor of each Prime Minister candidate. We classify the microblogs to positive and negative opinion classes and we use machine learning classification techniques achieve this and translator translate the all language reviews and microblogs convert to Hindi language.
KEYWORDS |
| Opinion Mining, Sentiment Analysis, Reviews, Naïve Bayes’ Theorem, Hindi translator. |
I. INTRODUCTION |
| Microblogging is a very common and powerful mode of communication among internet users. Microblogs often reflect personal opinions and are very useful for opinion mining. We considered a corpus from twitter. Microblogs in twitter are called tweets. We choose tweets from the period of Prime Minister elections in India in 2014. We mainly try to classify the Tweets into political opinions against and in favor of the Prime Minister candidates, Narendra Modi and Rahul Gandhi. We used various feature selection techniques and classification algorithms. The best results were obtained by using n-gram features with support vector machines (SVM) classifier. The Status corpus used is manually annotated for sentiments and we use this as a gold standard for evaluation of precision, recall and f-score of our classification this and translator translate the all language reviews and microblogs convert to Hindi language using the Hindi translator. |
II. RELATED WORK |
| Sentiment analysis of Status is a growing area of research. Since twitter has a limit characters per post. Opinion table has been work done in sentiment analysis of twitter corpus by machine learning classification methods [Pak & Paroubek, 2010]. Opinion table has been work done specifically for political opinion mining from Twitter [Maynard & Funk, 2011]. Different from using different features and classifiers, there are variety of methods used like use of emoticons [Go et al., 2009], use of opinion reversal words etc for identifying sentiments. we have used some similar ideas in our data processing. |
III. PROPOSED ALGORITHM |
| Our approach consisted a variety of ideas borrowed from the zone of natural language processing, information retrieval and machine learning. The algorithm mainly designs of the following steps, |
| 1. Data processing |
| 2. Features |
| 3. Training the classifier |
Data processing |
| The corpus has considerable amount of metadata such as date, time, identity number etc and to extract natural language content. We need to subject the data to a series of processing steps before the data can be used to extract features and train a classifier. Here is a sample of the raw data before data process. |
| 315, 41199, AM 0:26:17, News Analysis: In Second Debate Modi Strikes Back (NY Times): Share With Friends. |
| 1. Stop words removal - We used the Natural language Toolkit’s (NLTK) [2] stopword corpus for the English language to remove the stop words from the paragraph. This helps eliminating the most common stop words from being included in the computation of n-grams and feature extraction. |
| 2. Stemming - Twitter data is generally used with informal language and it includes internet jargons, slang and contemporary spellings. We were very frugal in stemming so as to not risk truncating words and losing out on probable features. We employed basic stemming (e.g. use of Bosnion). |
| 3. Spelling correction - As Twitter users generally use unofficial language. There are often wrong spellings in tweets. We used Jazzy Open Source Magic Checker [3] to detect incorrect spellings in the tweets, paragraph and replace them with the closest word from the English dictionary. |
| 4. Entities - The entities we used were Narendra Modi or Rahul Gandhi. But, these entites are addressed to by various names for e.g. Narendra Modi is generally self addressed as Mr. Prime Minister, Narendra Modi etc. So, we normalised this by replacing the possible names people use to address the entities by either Modi or Rahul. |
| 5. Emoticons mapping to sentiments - There are a multitude of emoticons that are used repeatedly in Twitter. We used an approach inspired by the method used by [Go et al., 2009] and mapped some emoticons to positive and negative sentiments and discarded emoticons that are ambiguous or irrelevant to sentiments. |
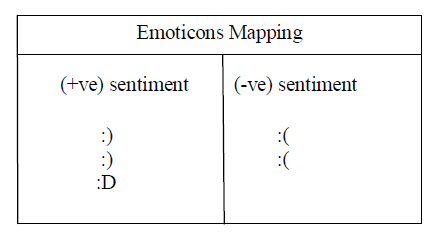 |
| 6. Part of Speech tags - We experimented with both NLTK and OpenNLP [4] Part Of Speech tagger with a heuristic that adjectives and/or adverbs are generally used to articulate opinions in natural language. The data was tokenized by spaces and the tokens were subject to the taggers. We also experimented by adverbs and words such as not, excluding all data sans the entity, adjectives, could not etc. which generally indicate a reversal of sentiment. He is equal to the route opinion reversing words were used by [Maynard & Funk, 2011] |
| 7. Filtering - Tweets contained a lot of metadata and crop a bit of din which were removed. The following data was filtered, |
| ïÃâ¬Ã Ã¯Ãâ÷ Identity numbers, date, time etc ,of the tweets. ïÃâ¬Ã |
| ïÃâ÷ Irrelevant tags ïÃâ¬Ã |
| ïÃâ÷ Hyperlinks ïÃâ¬Ã |
| ïÃâ÷ #tags e.g. #msnbc2012 ïÃâ¬Ã |
| ïÃâ÷ Twitter handles e.g. @Pawan ïÃâ¬Ã |
| ïÃâ÷ punctuation, special characters and digits ïÃâ¬Ã |
| 8. Encoding - There are a few tweets that are not in Hindi and other languages. These tweets contain UTF-8 encoded words for e.g. naive. These characters were excluded from the tweets and only ASCII encoded characters were hold in. |
| All content was also transformed to lowercase. These characters interfered with the classifiers. |
| After subjecting a tweet to this data processing process, we are left with only the natural language content of the tweet and the human annotated sentiment that is used by the classification algorithm in supervised learning. After data processing, the sample tweet we considered earlier about would be transformed to, |
| “news analysis second debate Modi strikes back ny times share friend s top news,-1” |
| 1for positive, -1 for negative are the annotations used for sentiment classification. |
| 9. Translator – Translator is translating the all microblogs and tweets convert into Hindi language and microblogs & tweets are any language but translator translate into Hindi language. Using the Google translator. |
IV. FEATURES |
| N-gram features - The processed data is used to extract features that will be used to coach our classifier. We have experimented with Ngram. The data was tokenized by spaces using NLTK and these tokens were subject to NLTK to generate n-grams. |
| Part Of Speech features - Since the language used in Twitter is generally informal, part of speech tagging is not accurate for tweets. We used both NLTK Part Of Speech tagger and Open NLP Part Of Speech tagger along with a heuristic that adjectives and adverbs, JJ, JJR, JJS, RB, RBR and RBS in the Penn Tree bank tag set, are generally used to articulate opinions in natural language. So we further process the data by excluding all data saving. The entity, adjectives, adverbs and words such as not, could not etc which generally indicate a reversal of sentiment. This is similar to the route opinion reversing words were used by Maynard and Funk [Maynard & Funk, 2011]. After using part of speech taggers, we experimented with unigrams, bigrams and combination of unigrams and bigrams. We experimented with term recap-inverse document recap (tf-idf) where we considered only the most frequent terms ordered by tf-idf. We used the absolute approach of considering all the n-grams as features as well. |
| Sentiment Lexicon features - We used the terms in positive and negative opinion word lists [Hu & Liu, 2004] as features for classification. |
V. TRAINING THE CLASSIFIER |
| We experimented various combinations of features, classification algorithms and test options. As mentioned in the Feature extraction section, we extracted various feature sets and used these to construct the feature vectors. These were used to train the classifiers. We experimented with 4 different classifiers, |
| ïÃâ÷ Multinomial Naïve Bayes |
| ïÃâ÷ Logistic regression |
| ïÃâ÷ Random forest |
| ïÃâ÷ Support vector machines (SVM) |
| We used these classifiers from weka (weka is a machine learning algorithm), a popular suite of machine learning software [5] and Lib SVM, a library for Support Vector Machines [6]. We also experimented with one Vs all classification strategy with SVM. We experimented with the evaluation methods, 70-30 percent split and 10-fold cross validation. |
VI. PSEUDO CODE |
| STEP 1: Initialize P(positive) ïÃâìnum ïÃâ¬ÃÂïÃâ¬Ã popozitii (positive)/ num_total_propozitii |
| STEP 2: Initialize P(negative) ïÃâìnum ïÃâ¬ÃÂïÃâ¬Ã popozitii (negative) / num_total_propozitii |
| STEP 3: Convert sentences into words for each class of {positive, negative}: for each word in {phrase} |
| P(word | class) < num_apartii (word | class) 1 | num_cuv (class) + num_total_cuvinte |
| P (class) P (class) * P (word | class) |
| Returns max {P(pos), P(neg)} |
| Convert sentence into english(all languages) to Hindi using google translator |
VI. EXPERIMENTAL RESULTS |
| We used various combinations of features and classifiers and here are the different experimental results using both Weka and LibSVM. Table-1 shows the results of using 8000 most frequent unigrams without removal of stop words used with Naïve Bayes Multinomial classifier using a 70-30% evaluation method. We got no significant changes in results when we experimented with used Logistic regression and Random forest classifiers. Table-2 shows the results of using 10000 unigram features ordered by tf-idf using Naïve Bayes classifier. We used 10-deflect cross validation for the following results. |
| Table 1: Confusion matrix - 8000 most frequent unigrams without stopword removal as features using a Multinomial Naïve Bayes classifier |
 |
| Table 2: Confusion matrix - 10000 unigram features ordered by tf-idf using Naïve Bayes classifier |
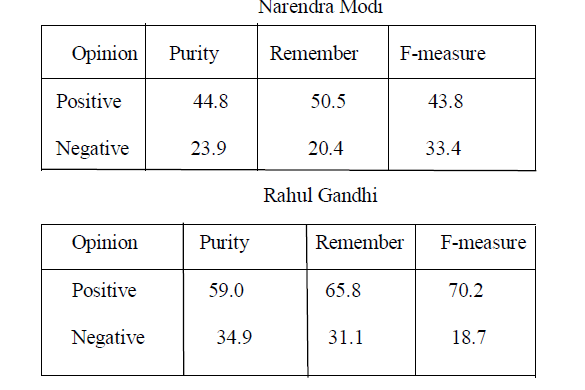 |
| We experimented with positive and negative terms in opinion word lists [Hu & Liu, 2004] as features for classification. Table 3: Confusion matrix - Opinion word lists as features using Logistic regression classifier |
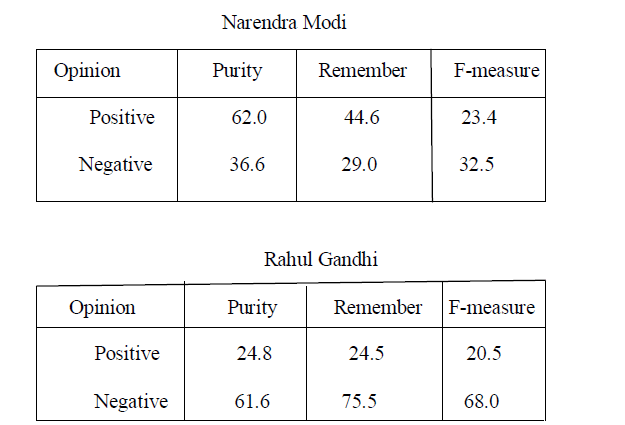 |
| The results obtained by employing part of speech tagging for feature selection are shown in Table-4. |
| Table 4: Confusion matrix - Parts of speech tags (adjectives/adverbs tags) used for feature selection and using Naïve Bayes classifier |
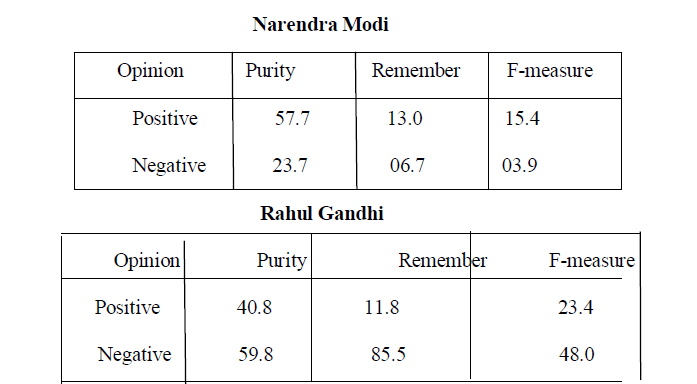 |
| We then trained the model on the entire training corpus and evaluated the test data by using the combination of unigrams and bigrams as features and SVM classifier employing a one Vs all classification strategy .Table-5 shows these results. We used LibSVM for this experiment. |
| Table 5: Confusion matrix - Test data - unigram & bigram features using SVM classifier and one-vs.-all classification strategy |
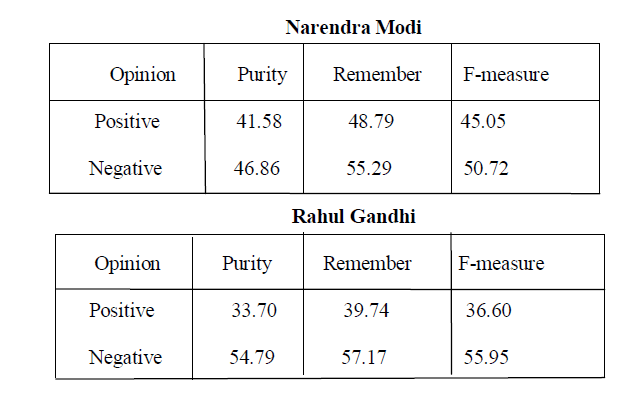 |
VIII.CONCLUSION |
| In this paper we have presented an all language corpus for opinion mining along with its Hindi translation. All language corpora are freely available for the research community. The Translator corpus is composed of all language reviews obtained from web pages related to movies and films. Then, we have generated the all language corpus, which is the Hindi translation of the using an automatic machine translation tool. Both corpora include a total of 500 reviews, 250 positives and 250 negatives. In addition, we have accomplished several experiments over the corpora using two different machine learning algorithms (SVM and Naïve Bayes) and applying a stemming process. |
References |
|