International Journal of Advanced Research in Electrical, Electronics and Instrumentation Engineering
ISSN ONLINE(2278-8875) PRINT (2320-3765)
ISSN ONLINE(2278-8875) PRINT (2320-3765)
Priyanka Umap1, Kirti Chaudhari2
|
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Advanced Research in Electrical, Electronics and Instrumentation Engineering
There are abundant real time applications for singing voice separation from mixed audio. By means of Robust Principal Component Analysis (RPCA) which is a compositional model for segregation, which decomposes the mixed source audio signal into low rank and sparse components, where it is presumed that musical accompaniment as low rank subspace since musical signal model is repetitive in character while singing voices can be treated as moderately sparse in nature within the song. We propose an efficient optimization algorithm called as Augmented lagrange Multiplier designed to solve robust low dimensional projections. Performance evaluation of the system is verified with the help of performance measurement parameter such as source to distortion ratio(SDR),source to artifact ratio(SAR), source to interference ratio(SIR) and Global Normalized source to Distortion Ratio (GNSDR).
Keywords |
| Robust Principle Component Analysis (RPCA),Singing Voice Separation, Augmented Lagrange Multiplier (ALM),low rank matrix,sparse matrix. |
INTRODUCTION |
| Numerous classes of information are composed as constructive mixtures of portions. Constructive combination, is additive combination that do not result in deduction or diminishment of any of the portion of information, this is referred to as “compositional” data. To characterize such information, various mathematical models are developed. Such models have provided new standards to solve audio processing problems, such as blind and supervised source separation and robust recognition. Compositional models are used in audio processing systems to advance the state of the art on many difficulties that deal with audio data involving of multiple sources, for example on the analysis of polyphonic music and recognition of noisy speech. Thus we use robust principal component analysis (RPCA) as a compositional model in this paper. |
| Robust Principal Component Analysis (RPCA) method is extensively used in the field of image processing for image segmentation, surveillance video processing, batch image alignment etc. This procedure has received recent prominence in the field of audio separation for the application of singer identification, musical information retrieval, lyric recognition and alignment. |
| A song usually comprises of mixture of human vocal and musical instrumental audio pieces from string and percussion instruments etc. Our area of interest is segregating vocal line from music which is complex and vital musical signal element from song, thus we can treat musical as intrusion or noise with respect to singing voice. Human auditory system has incredible potential in splitting singing voices from background music accompaniment. This task is natural and effortless for humans, but it turns out to be difficult for machines [15]. |
| Compositional model based RPCA has emerged as a potential method for singing voice separation based on the notion that low rank subspace can be assumed to comprise of repetitive musical accompaniment, whereas the singing voice is relatively sparse in time frequency domain. Basic audio voice separation systems can be divided into two categories that are supervised system and unsupervised system. In supervised systems, training data is required to train the system. On the contrary, in unsupervised systems, no prior training or particular feature extraction is required. |
| The challenges for singing voice separation from background music accompaniment are as follows. In general, the auditory scene created by a musical composition can be viewed as a multi-source background, where varied audio sources from several classes of instruments are momentarily active, some of them only sparsely. The music sources could be of different instrumental type (so exhibiting altered timbral perceptions), which is played at various pitches and loudness, and even the spatial location of a given sound source may differ with respect to time. Regularly individual sources repeat during a musical piece, one or the other way in a different musical environment. Therefore, the section can be considered as a time-varying schedule of source activity encompassing both novel and recurring patterns, representing changes in the spectral, temporal, and spatial complexity of the mixture. Moreover the singing voice has fluctuating pitch frequency for male and female singer which may at some instant overlap with background frequency arrangement of musical instruments. To solve these tasks a compositional model designed using a novel technique Robust Principal Component Analysis (RPCA) is proposed using Augmented Lagrange Multiplier (ALM) as a optimization algorithm for better convergence. Robust Principal Component Analysis[2], which is a matrix factorization algorithm for solving low rank matrix and sparse matrix. Here in our proposed system we assume that the music accompaniment lie in low rank subspace while the singing voice is relatively sparse due to its more variability within the song. |
PROPOSED SYSTEM ALGORITHM |
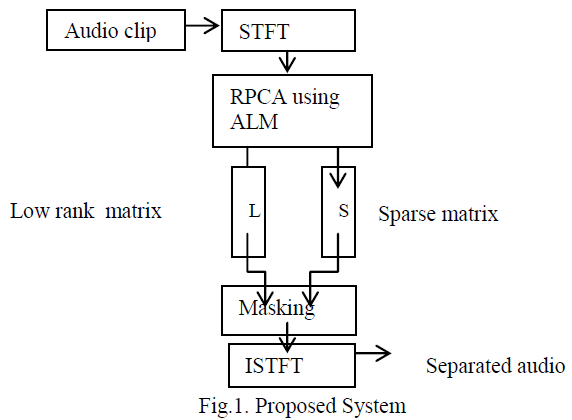
| A song clip is superimposition of singing voice and background musical instruments which can be considered in terms data matrix(audio signal) which is combination of low rank component(musical accompaniment) and sparse components(singing voice).We assume that such data have low intrinsic dimensionality as they lie on several low dimensional subspace, are sparse also in few basis[8].We perform separation of singing voice as follows seen in figure |
| 1.The steps are as follows: |
| 1) We compute Short-Time Fourier Transform (STFT) of the targeted audio signal where signal is represented in time frequency domain. In the separation method, STFT of the input audio signal is computed using overlapping hamming window with N=1024 samples at sampling rate of 16Khz. |
| 2) After calculation of STFT, RPCA is applied by means of Augmented Langrange Multiplier (ALM) as optimization technique which deciphers the computational problem of RPCA [2]. After applying RPCA we get two output matrices „LâÃâ¬ÃŸ low rank matrix and „SâÃâ¬ÃŸ sparse matrix. Binary frequency mask is later applied for quality of separation end result. |
| 3)Inverse Short Time fourier transform (ISTFT) is latter applied, in order to obtain the waveform of the estimated results followed by evaluation of the results. |
 |
| In real world data if n m-dimensional data vectors is put in the form of a matrix A∈ ,where A should have a rank& min(m,n),which means that there are some linearly independent columns[5].The objective is to obtain low rank approximation of A in the existence of noises and outliners.The classical principal component analysis approach which assume the given high dimensional data lie near a much lower dimensional subspace[11].The method seeks a rank –r estimate M of the matrix A by solving, |
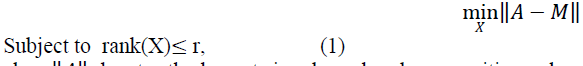 |
| where ïÿýïÿý denotes the largest singular value decomposition value of A or the spectral norm.The above problem can be solved via singular value decomposition(SVD), by using r largest singular values. But PCA is subtle to outliners and performance declines under bulky corruption. To solve this issue,robust PCA (RPCA) [2,6] is used to render PCA robust to outliners and gross corruption. |
| A data matrix M∈ ïÿýïÿýïÿýïÿý×ïÿýïÿý can be uniquely and exactly be decomposed into a low rank component A and a sparse component E,also retrieval of low rank matrix by convex programming. The convex optimization problem can be put forth as follows in terms of objective function and a constraint function[8]. |
| where denote the nuclear norm i.e the sum of singular values and . 1 denote the L1-norm that is the sum of the absolute values of matrix entriesis an valuable surrogate for L0 psuedo norm, the number of non-zero entries in the matrix.is the trade off parameter between the rank of A and sparsity of E[6]. |
| where for > 0 is a regularization parameter and for k=1 we get best quality separation result and the results are tested for different values of k. Proficient optimization scheme the Augmented langrange multiplier method is used for solving the above RPCA problem which has higher convergence property. ALM algorithm is iterative converging scheme which works by repeatedly minimizing the rank of A and E matrices simultaneously [4]. ALM is optimization technique for noise reduction. |
| For better separation outcomes masking can be applied to the separation results of ALM that are low rank A and sparse E matrices by using binary time frequency masking [6]. We need to accurately segregate the components as singing voice mostly lines the music accompaniment during beat instances in order to match with rhythmic structure of the song and hence we apply masking for enhanced separation outcomes. |
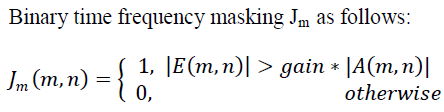 |
| After application of time frequency masking it is applied to the original audio signal M in order to obtain the separation matrix as singing voice and music respectively. |
RESULTS AND DISCUSSION |
| We have worked on this algorithm using MIR-1K database, comprising of male singer and female singer with a sample rate of 16Khz and the duration of the audio clip is 10-14seconds.We create three clips, first consisting of mixed song,second consisting of singing voice and third consisting of musical accompaniment from the stereo database by converting it to mono channel using Audacity software, for the evaluation of the results. The separated audio files are compared with these files. |
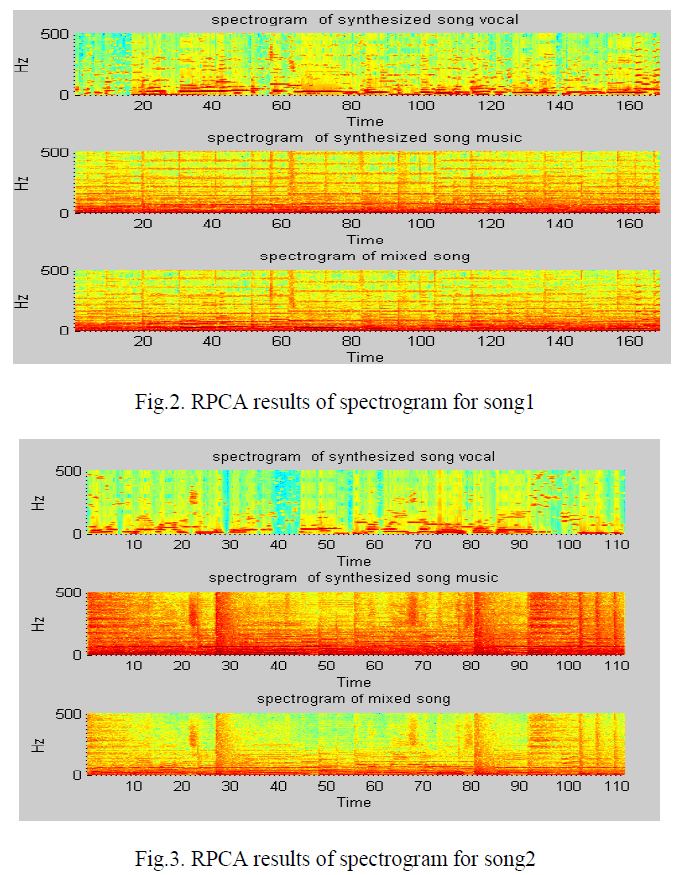
| For the separation and evaluation purpose,spectrograms of each mixture is computed for input audio signal and separated audio signals i.e. the singing voice and music accompaniment. We have taken audio clips consisting of two or more musical instruments in the background and studied its impact on separation. Figures 2 and 3 show the spectrograms for respective audio signal separately for different values of k(of ) and on merging the spectrogram of singing voice and music accompaniment we get spectrogram of mixed song. For construction of spectrogram results the low rank and sparse matrix and multiplied by the initial phase of the audio signal. We can examine the varying pitch pattern of separated vocal from song in the spectrograms obtained. In figure 1 spectrogram consists of larger voiced part than that of figure 2 spectrogram for singing voice. From spectrogram results of separated synthesized song musical accompaniments harmonic structure of instruments can be verified. |
 |
| The value of which is a adjustment parameter with respect to rank of A (low rank component) and with the scarcity of E(sparse matrix).From investigational outcomes it has been observed that |
| If the matrix E is sparser which means that there is less interference in the matrix E(sparse matrix) but due to this deletion of original components may result in artifacts which is unwanted for the proposed system. |
| If E matrix is less sparse, then audio signal will contain, then the signal contains less artifacts which implies that there is more intrusion from the sources which exist in matrix E. |
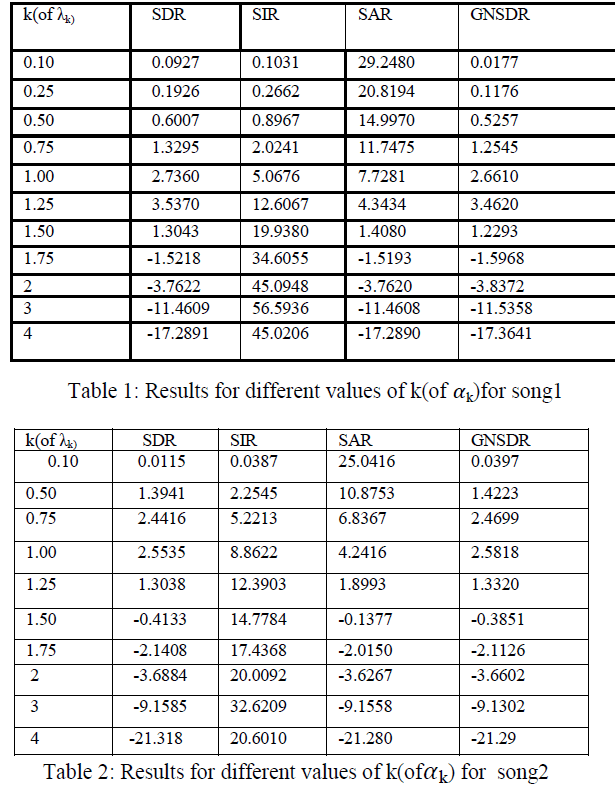
| Thus from this we can say that matrix E(sparse matrix) is sparser with higher value and vice versa. We can spot this difference for value of k(of ) = {0.1,0.25,0.50,0.75,1,2,3,4} from the above array we can notice that for values above 1 in the array separation does not take place. |
| For assessment of the performance of separation results in terms of Source to Interference Ratio(SIR),Source to Artifacts Ratio (SAR) and Source to Distortion Ratio(SDR) with assistance of BSS-EVAL metrics. We also evaluate the performance in terms of Global Normalized Source to Distortion Ratio which takes into account the resynthesized singing voice(vÃÅÃâ ),original clean voice(v) and the mixture(x). |
| The Normalized SDR (NSDR) is defined as |
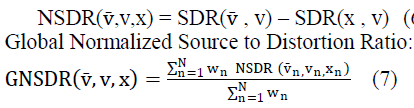 |
 |
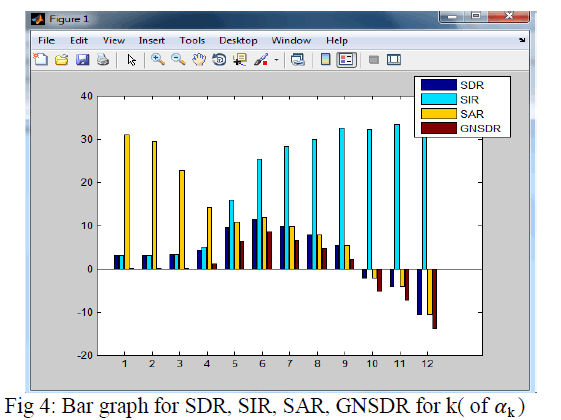 |
| Better separation results are obtained for value of k(of k) less than 1.5 as seen in table 1 and 2 numerical values as well as the bar graph seen in figure 4 respectively. It has been observed that greater the value of SDR,SAR,SIR and GNSDR improved separation results are achieved, the above values can be compared for various values of k(of ) in the above table and bar graph respectively. |
CONCLUSION |
| Robust Principal Component Analysis (RPCA) is used as a audio separation technique in this paper. We have enhanced singing voice separation using Augmented Lagrange Multiplier(ALM) for numerous values of k. Separation results all depend on trade of parameter k. Quality separation outcomes are proven for value of kless than 2 and the outcomes are justified through spectrogram outcomes also can be verified perceptually through separated audio files acquiredfor singing voice and music accompaniment. |
References |
|