International Journal of Innovative Research in Computer and Communication Engineering
ISSN ONLINE(2320-9801) PRINT (2320-9798)
ISSN ONLINE(2320-9801) PRINT (2320-9798)
Vibhavi R.N.1, Vrushali Uttarwar2
|
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Innovative Research in Computer and Communication Engineering
Text Segmentation from a degraded document images is a very difficult task as the document image might contain lot of variations between the foreground and the background part.Binarization is been into intense research during the last few years. Most of the developed algorithms depend on statistical methods and do not consider the nature of document images. However, recent developments call for more specialized binarization techniques. Adaptive image contrast is used as a binarization technique in this paper . The adaptive image contrast is a combination of the local image contrast and the local image gradient. It is also tolerant towards variations caused due to degradations.The proposed technique constructs an adaptive contrast for an input degraded document image. The contrast map is then binarized and combined with Canny’s edge map to identify the text stroke edge pixels. A local threshold is estimated based on the intensities of detected text stroke edge pixels within a local window and this threshold is used for segmentation purpose.. The proposed method is simple, robust, and involves minimum parameters.
Keywords |
| Adaptive image contrast, document analysis, document image processing, degraded document image binarization, pixel classification. |
INTRODUCTION |
| Document image binarization plays a key role in document processing since its performance affects the degree of success in subsequent character segmentation and recognition. in general, image binarization is categorised in two main classes: (i) global and (ii) local. binarization is a preprocessing stage for document analysis and it is used to segment the foreground text from the document background. this technique ensures faster and accurate document image processing tasks. Most document analysis algorithms are built based on underlying binarized image data. The use of bilevel information decreases the computational load and helps in using simplified analysis methods compared to 256 levels of grey-scale or colour image information. Document image understanding methods require logical and semantic content preservation for thresholding.though document image binarization has been studied for many years, the thresholding of images is still a challenging task due to the high variation between the text stroke and the document background. for an input image, some processing stages should be used before the text extraction. one of the step includes binarization. |
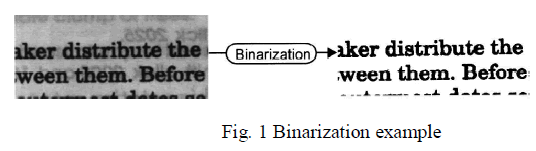
| In this stage the grey-scale image converts into a binary image. a binary image can be processed better than a greyscale image as illustrated in fig. 1, the handwritten text within the degraded documents might contain a certain amount of variations like stroke width, stroke brightness, stroke connection, and document background. in addition, historical documents are often degraded by the bleed through, where the ink of the other side seeps through to the front. Also they are often degraded by different types of imaging artifacts. These different types of document degradations induce the document thresholding error and make degraded document image binarization very difficult. This paper presents a document binarization technique that extends previous local maximum-minimum method [1]. |
 |
| The proposed method also involves minimum parameter tuning. It makes use of the adaptive image contrast that combines the local image contrast and the local image gradient adaptively.Hence the method handles different types of document degradations. It also addresses the over-normalization problem of the local maximum minimum algorithm [1]. The parameters used in the algorithm can be easily and adaptively estimated and hence the method can be simple and robust.The rest of this paper is organized as follows. Section II first reviews the current state-of-the-art binarization techniques. Section III deals with the design and section IV contains a description of the proposed document binarization technique and finally, conclusions are presented in Section V. |
II. RELATED WORK |
| Most of the adaptive local binarisation methods ignore the edge property and lead to erroneous results due to the creation of fake shadows. For this, there exist approaches that also incorporate edge information as in wherein they find seeds near the image edges and present an edge connection method to close the image edges. Many thresholdingtechniques have been used for document image binarization. As many degraded documents do not have a clear bimodal pattern [10], global thresholding [2] is usually not a suitable approach for the degraded document binarization. Adaptive thresholding [3], which estimates a local threshold for each document image pixel, is often a better approach to deal with different variations within degraded document images. The early window-based adaptive thresholding techniques [5] estimate the local threshold by using the mean and the standard variation of image pixels within a local neighborhood window. The main drawback of this technique is that the thresholding performance and character stroke width depends mostly on the window size. Other approaches have also been reported, including background subtraction texture analysis, recursive method [4], decomposition method, contour completion, Markov Random Field etc. These methods combine different types of image information and domain knowledge and are often complex. The local image contrast and the local image gradient are very useful features for segmenting the text from the document background. The document text usually has certain image contrast to the neighboring document background. They are very effective and have been used in many document image binarization techniques [1], [2] In Bernsen’s paper [5], the local contrast is defined as follows. |
 |
| Where,ε is a positive but infinitely small number. Compared with Bernsen’s contrast in Equation (1), the local image contrast in Equation (2) introduces a normalization factor (the denominator) to compensate the image variation within the document background. |
| Take the text within shaded document areas such as that in the sample document image in Fig. 1 as an example. The small image contrast around the text stroke edges in Equation 1 (resulting from the shading) will be compensated by a small normalization factor (due to the dark document background) as defined in Equation 2. |
III. DESIGN |
| The degraded document image is given as input & the improved document image is the desired output. The document image at each stage of contrast enhancement, threshold image and stroke enhanced image are shown as output. The following Figure illustatres the overall architecture of the technique. |
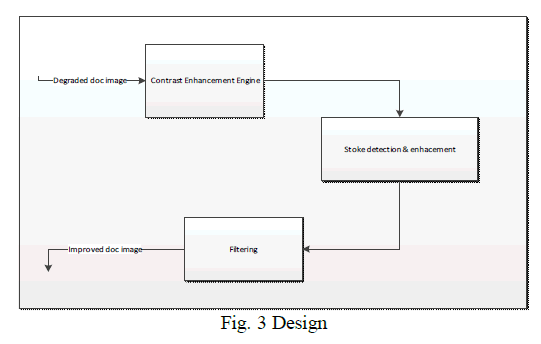 |
| Contrast Enhancement Engine: will enhance the contrast of the image in such a way the text stokes becomes bright. |
| Stroke detection & enhancement: This module will segment the image using edge detection method & improve the stoke width. |
| Filtering: This module will remove the background noises & improve the quality of the image. |
IV. PROPOSED SYSTEM |
| A pre-processing stage of the grey scale source image is essential for the elimination of noisy areas, smoothing of background texture as well as contrast enhancement between background and text areas. This section describes the proposed document image binarization techniques. For a given a degraded document image, first an adaptive contrast map is constructed and the text stroke edges are then detected through the combination of the binarized adaptive contrast map and the canny edge map. The document image contains multiple surface (texture) types that can be divided into uniform, and transiently changing. The texture contained in pictures and background can usually be uniform or differentiating categories, while the text, line drawings, are of transient properties by nature. The text is then segmented based on the local threshold that is estimated from the detected text stroke edge pixels. A post-processing is further applied at the end to improve the document binarization quality. |
A. Contrast Image Construction |
| The image gradient is used for edge detection and it can be used to detect the text stroke edges as well[7]. It often detects many non-stroke edges from the background of degraded document that contains variations caused due to noise, uneven lighting, bleed-through, etc. Hence, in order to extract only the stroke edges, the image gradient needs to be normalized. In the earlier method [1], The local contrast evaluated by the local image maximum and minimum suppresses the background variation as described in Equation (2). In particular, the numerator (i.e. the difference between the local maximum and the local minimum) captures the local image difference similar to the traditional image gradient. The denominator is a normalization factor and suppresses the image variation within the document background. For image pixels within bright regions, a large normalization factor is produces to neutralize the numerator and accordingly result in a relatively low image contrast. For the image pixels within dark regions, it will produce a small normalization factor accordingly. However, the limitation of image contrast in Equation (2) isthat it may not handle document images with the bright text properly. To overcome this over-normalization problem, the local image contrast is combined with the local image gradient and an adaptive local image contrast is derived as follows: |
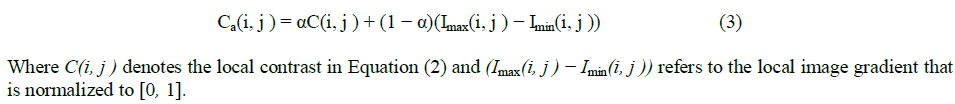 |
B. Text Stroke Edge Pixel Detection |
| The purpose of the contrast image construction is to detect the stroke edge pixels. The constructed contrast image has a clear bi-modal pattern [1], where the adaptive image contrast computed at text stroke edges is larger than that computed within the document background. The local image contrast and the local image gradient are evaluated by the difference between the maximum and minimum intensity in a local window, the pixels at both sides of the text stroke will be selected as the high contrast pixels. The Canny’s edge detector can be used to improve the binary map since it has a good localization property. The canny edge detector uses two adaptive thresholds and is more tolerant to different imaging artifacts such as shading [6]. The Canny’s edge detector extracts a large amount of non-stroke edges as illustrated in Fig. 4 without tuning the parameter manually. The combination helps to extract the text stroke edge pixels accurately. |
 |
C. Local Threshold Estimation |
| The text can then be extracted from the document background pixels if the high contrast stroke edge pixels are detected properly. There are two characteristics from different kinds of document images [1]: First, the text pixels are close to the detected text stroke edge pixels. Second, there is a distinct intensity difference between the high contrast stroke edge pixels and the surrounding background pixels. The document image text can thus be extracted based on the detected text stroke edge pixels as follows: |
| R(x, y) = _ 1 I (x, y) ≤ Emean+ Estd (4) |
| Where,Emean and Estd are the mean and standard deviation of the intensity of the detected text stroke edge pixels within a neighborhood window W, respectively. The neighborhood window should be at least larger than the stroke width. The size of the neighborhood window W can be set based on the stroke width of the document image under study, EW, which can be estimated from the detected stroke edges as stated in Algorithm 1.Since we do not need a precise stroke width, we just calculate the most frequently distance between two adjacent edge pixels (which denotes two sides edge of a stroke) in horizontal direction and use it as the estimated stroke width. First the edge image is scanned horizontally row by row and the edge pixel candidates are selected as described in step 3. If the edge pixels, which are labeled 0 (background) and the pixels next to them are labeled to 1 (edge) in the edge map (Edg), are correctly detected, they should have higher intensities than the following few pixels (which should be the text stroke pixels). So those improperly detected edge pixels are removed in step 4. In the remaining edge pixels in the same row, the two adjacent edge pixels are likely the two sides of a stroke, so these two adjacent edge pixels are matched to pairs and the distance between them are calculated in step 5. After that a histogram is constructed that records the frequency of the distance between two adjacent candidate pixels. The stroke edge width EW can then be approximately estimated by using the most frequently occurring distances of the adjacent edge pixels. |
 |
| 7: Construct a histogram of those calculated distances. |
| 8: Use the most frequently occurring distance as the estimated stokeedge width EW. |
 |
V. CONCLUSION |
| This paper presents an adaptive algorithm for document image binarization that makes ues of adaptive approach to manage different situations in an image. The binarization technique used here is found to be tolerant towards different document degradation like uneven illuminations, variations and smear. The usage of less parameter has proved that the technique is simple and robust. The technique also works for different kinds of degraded document images. The local image contrast used here is evaluated based on the local maximum and minimum. The method is experimented on various datasets as discussed earlier and has outperformed the other methods. |
References |
|