International Journal of Advanced Research in Electrical, Electronics and Instrumentation Engineering
ISSN ONLINE(2278-8875) PRINT (2320-3765)
ISSN ONLINE(2278-8875) PRINT (2320-3765)
V.Harika1, A.SubbaRami Reddy2, S.China Venkateswarlu3
|
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Advanced Research in Electrical, Electronics and Instrumentation Engineering
This paper investigates the improvement of Telugu speech quality in terms of six objective quality measures using Discrete Wavelet Transform and proposes two Hybrid thresholding methods which are formed by combining soft and Improved thresholding methods with Modified Improved thresholding method. The performance of the new Hybrid methods is compared with the other thresholding methods. It is observed that the new proposed scheme yields better results when applied to Telugu noisy speech signals with low SNR (0dB) conditions. In this method, noisy speech signal is divided in to overlapping frames and each frame is windowed using hamming window. The windowed speech blocks are applied to the wavelet based speech enhancement algorithm and the enhanced speech is reconstructed in its time domain. For denoising the Telugu speech signal, various techniques like hard, soft, improved, modified improved and hybrid thresholding methods are used. Analysis is done using daubechies and symlets wavelets with different white Gaussian noise environments. Six Objective quality measures are considered in this study to test the performance of the algorithm for enhanced Telugu speech quality and compared. Hybrid thresholding methods perform better than hard, soft, improved and modified improved thresholding methods for wavelet based speech denoising.
Keywords |
| Speech enhancement, objective quality measures, thresholding, discrete wavelet transform, hamming window. |
INTRODUCTION |
| Speech is the most primary human communication. For that reason, it exists a big trend to increase and improve telecommunications [1]. Now-a-days, all the people use the communication devices such as telephones, mobiles, internet etc., as a primary goal and the customers demand a high coverage and quality. But a speech signal is often degraded by additive background noise. Listening task is very difficult at the end user, in such noisy environment. Therefore, it is necessary to develop speech enhancement algorithms. Speech enhancement is the most important field of speech processing. Speech enhancement refers to methods aiming at recovering speech signal from a noisy observation. During the last decades, Many algorithms and various approaches have been proposed to the problem such as spectral subtraction [2], wavelet based methods [3], hidden Markov modelling [4] and signal subspace methods [5]to improve the perceptual quality of the speech signals from the corrupted input signal. |
| The wavelet based denoising algorithm is one of the ways for speech enhancement. Telugu speech sentences are applied to this algorithm for enhancement. Telugu is a South-Central Dravidian language. It is one of the twenty-two scheduled languages of the Republic of India and primarily spoken in the states of Andhra Pradesh and Telangana in India, where it is an official language. It is also spoken in some neighbouring states. Telugu is the language with the third largest number of native speakers in India (74 million). The Telugu Wikipedia was the First South Asian language to cross the 20,000 articles mark, and presently has the largest number of articles among all South Asian languages[6], [7]. |
| Wavelets have been found to be a powerful tool for removing noise. The fundamental idea behind wavelets is to analyse the noise level separately at each wavelet scale [8]. Wavelet thresholding deals with wavelet coefficients using a preset threshold value. The wavelet coefficients are obtained by taking DWT of noisy speech signal. It is assumed that high amplitude coefficients are due to original signal and low amplitude coefficients are due to noise. Thresholding is that each wavelet coefficient is compared with the preset threshold value, if the coefficient is smaller than the threshold, then it is set to zero, otherwise it is kept or reduced in amplitude. Soft, Hard, Improved Modified Improved and the proposed Hybrid thresholding methods are used in the present work for de-noising the signals. |
| In this paper, to study the performance of the algorithm, objective quality measures and subjective quality measures have to be carried on. Subjective measures are based on comparison of original and processed speech data by a listener or a panel of listeners. They rank the quality of the speech according to a predetermined scale subjectively. But it is costly and time consuming. Hence, six objective measures such as SNR, segmental SNR, Frequency weighted segmental SNR, Log likelihood ratio, Weighted spectral slope distance, Cepstrum distance are chosen for performance evaluation test. |
| The paper is organised as follows: Part II explains the background for the Speech enhancement, In Part-III the Speech enhancement using wavelet transform and the proposed scheme of thresholding are explained, In Part-IV Speech Materials is presented; Part-V Applying DWT to Telugu Speech Samples, Part-VI describes the Objective quality measures, Part-VII presents the Simulation and Results and Part-VIII describes the Conclusion. |
BACKGROUND |
| There are basically two domains of speech enhancement. First one is time domain approach and second one is transform domain approach. In time domain approach, filtering is performed directly on the time sequence. This includes techniques such as LPC based digital filtering, Hidden Markov Model (HMM), and Kalman filtering. In the transform domain techniques, signals are first transformed into a new domain and then noise attenuation is performed on the transformed coefficients. Such techniques are Fourier Transform (FT), Discrete Fourier Transform (DFT), Discrete Cosine Transform (DCT), Wavelet Transform (WT) etc. The time domain filtering of noise corrupted signal is simple method and finds advantage only when removing high frequency noise from low frequency signal. However they do not provide satisfactory results under real world conditions. Advantage of wavelet transform is that, wavelet analysis allows the use of long time intervals for low frequency information and shorter regions for high frequency information. |
| `The wavelet based speech signal enhancement technique was proposed by Donoho and Johnstone [8]. This method is based on thresholding the wavelet coefficients of noisy speech signal.The fundamental idea behind wavelets are to analyse according to scale. The wavelet analysis procedure is to adopt a wavelet prototype function called an analysing wavelet or mother wavelet. Any signal can then be represented by translated and scaled versions of the mother wavelet. Wavelet analysis is capable of revealing aspects of data that other signal analysis techniques such as Fourier analysis miss aspects like trends, breakdown points, discontinuities in higher derivatives, and self-similarity. Furthermore, because it affords a different view of data than those presented by traditional techniques, it can compress or denoise a signal without appreciable degradation [9]. The method can be shown in fig.1 and the procedure is explained in Section-III. |
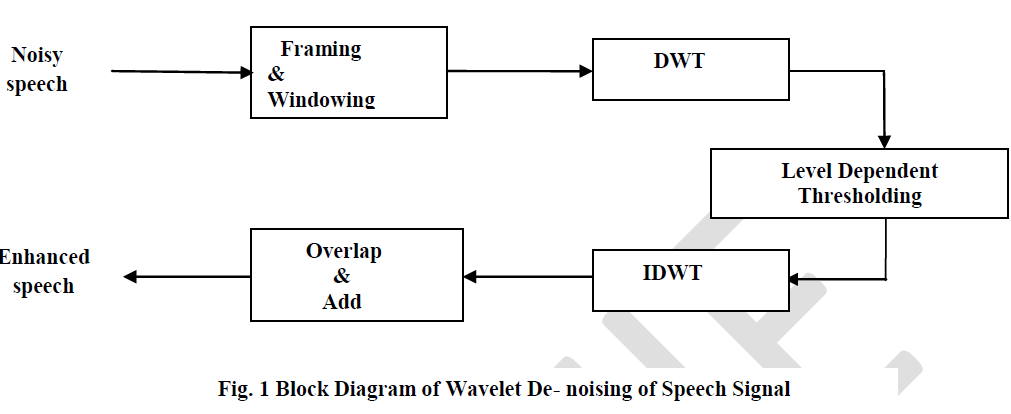 |
SPEECH ENHANCEMENT USING THE PROPOSED WAVELET THRESHOLDING |
| Speech Enhancement using the proposed Hybrid thresholding scheme can be summarized below. |
A. Noise Generation and Addition: |
| The Additive white Gaussian noise, which has zero mean and constant variance, is generated and added to the clean Telugu speech signal. The process of adding noise to the clean speech signal is expressed as: |
 |
B. Steps Involved: |
| The steps involved in wavelet based speech enhancement algorithm are as follows: |
1) Segmentation: |
| In speech processing, speech is non-stationary signal, where properties change rapidly over time. So it is impossible to calculate DWT. Because of this reason, the noisy speech signal is divided in to blocks of overlapping frames. The length of each frame is 256 samples. The overlap taken between two consecutive frames is from 50% to 75% .In this project, the overlap between frames is taken as 50%.That means, each frame is shifted from previous frame by 128 samples. |
2) Windowing: |
| A window is defined as a function that has zero-valued outside of some chosen interval. To avoid the discontinuities between the frames, every frame is multiplied by a window function. Hamming window is used in this method. Hamming window is most commonly used for windowing of the speech signal It is a fixed length window, only window length controls the window&s main lobe width or controls the performance of window function. Richard .W. hamming has proposed a hamming window. It is raised cosine window. Hamming window is defined as, |
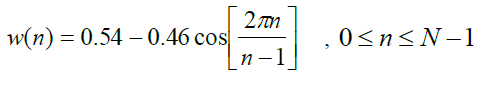 |
3) Discrete Wavelet Transform: |
| Discrete Wavelet Transform has become a powerful tool in a wide range of applications. Wavelet performs multi resolution analysis of a signal with localization in both time and frequency.Discrete wavelet transform produces nonredundant information due to orthonormal properties. To decompose and reconstruct the original speech signal, discrete Wavelet Transform (DWT) uses multi – resolution filter banks and wavelet filters. It provides sufficient information and reduces computation time for analysis and synthesis. There are different wavelet families like Haar, Daubechies, Coiflets, Symlet, Biorthogonal etc to analyse and synthesize a signal. The choice of wavelet determines the final waveform shape.For the present study Db4 and Db6 in Daubechies family and Sym5 and Sym7 in Symlet family have been selected for Speech Enhancement. |
| Given a mother wavelet (t) (which can be considered simply as a basis function of 2 L ), the continuous wavelet |
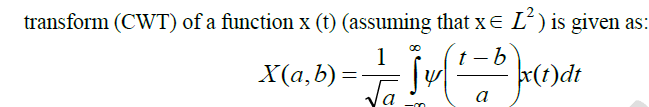 |
| Where, „a& is the scale parameter corresponds to frequency information and „b& is the translation parameter corresponds to the time information in the transform. Discrete wavelet transform (DWT) is essentially a sampled version of CWT. Instead of working with (a, b)& R, the values of X (a, b) are calculated over a discrete grid: |
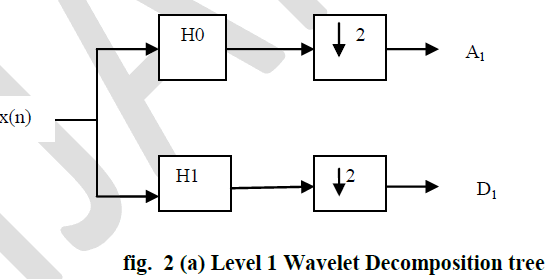 |
| H0= low-pass decomposition filter; H 1= high-pass decomposition filter, |
 Down-sampling operation. A1 is the approximated coefficient of the clean signal at level 1. D1 is the detailed coefficient at level 1. Down-sampling operation. A1 is the approximated coefficient of the clean signal at level 1. D1 is the detailed coefficient at level 1. |
5) Thresholding: |
| Wavelet thresholding is the signal estimation technique that exploits the capabilities of signal denoising. Performance of thresholding is purely depends on the type of thresholding method and thresholding rule used for the given application.Apply thresholding to the detailed coefficients rather than to the approximation coefficients, because the detailed coefficients contain important components of the signal. As a result, the estimated wavelet coefficients are obtained. In this paper, the additive white Gaussian noise that is added to the clean speech signal is removed by using the concept of Multi resolution. Threshold value is needed to remove the noise from the noisy signal. If the threshold value is too high, the content of original signal may get cut off and if threshold is too low, noise may not be removed properly. |
| Donoho and Jonstone [8, 10] proposed a time-constant threshold value for removing additive white Gaussian noise in the signal. The present work is based on level dependent threshold in which the detailed wavelet coefficients are modified according to the threshold value calculated based on the variance of the detailed coefficients of the Wavelet in each level. The threshold is mathematically expressed as: |
| Where, N denotes the number of samples of noisy speech signal and σi is the standard deviation of noise in level j and is given by |
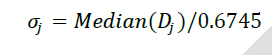 |
| Here Dj is the set of detailed coefficients at jth level and dj is an element in it. The Hard, Soft, Improved, Modified Improved [11] and the proposed Hybrid Thresholding method which is a formulated by combining modified improved thresholding with soft and Improved thresholding methods are used in this study. |
| A. Hard Thresholding: In Hard Thresholding, all WaveletâÃâ¬ÃŸs detail coefficients whose absolute values are less than the threshold are set to be zero and other waveletâÃâ¬ÃŸs detail coefficients are kept. It is defined as, |
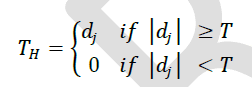 |
| B. Soft Thresholding: Soft thresholding is an expanded version of hard thresholidng. It sets all waveletâÃâ¬ÃŸs detail coefficients to zero whose absolute values are less than the threshold same as hard thresholding and shrinks the non-zero coefficients towards zero. It is defined as, |
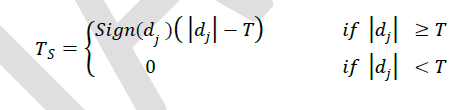 |
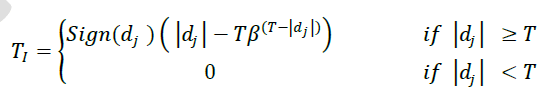 |
| D. Modified Improved Thresholding: Modified Improved thresholding [11] is proposed by A.Ghanbari andM.Karami. The thresholding function is like a hard thresholding function for the wavelet coefficients greater than threshold value and it is like an exponential functionfor the wavelet coefficients less than threshold value as given in EQ.(10). |
 |
| In this function, one important factor is γ and for this work γ =3 is used in order to have better performance [11]. |
| E. Hybrid Thresholding: In this method the authors are proposed two new thresholding schemes by combining with modified improved thresholding scheme with soft thresholding and modified improved thresholding with improved thresholding and are defined in EQ.11 and EQ.12 given below. |
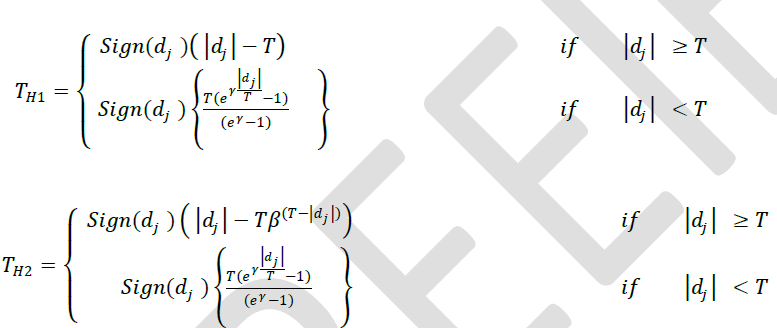 |
(6). Signal Reconstruction |
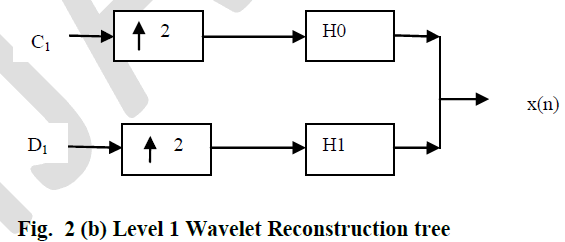
| The original signal can be reconstructed or synthesized using the inverse discrete wavelet transform (IDWT). The synthesis starts with the approximation and detail coefficients Aj and Dj, and then reconstructs by up sampling and filtering with the reconstruction filters. The reconstruction filters are designed in such a way to cancel out the effects of aliasing introduced in the wavelet decomposition phase. The reconstruction filters together with the low and high pass decomposition filters, forms a system known as quadrature mirror filters (QMF). For a multilevel analysis, the reconstruction process can itself be iterated producing successive approximations at finer resolutions and finally synthesizing the original signal as shown in fig. 2(b). |
 |
 |
| I. Initially, decompose the input signal frame using DWT: Choose a wavelet and determine the decomposition level of a wavelet transform L, then implement Layers wavelet decomposition of signal x (n). |
| II. Select the thresholding method for quantization of wavelet coefficients. Apply the thresholding on each level of wavelet decomposition and this thresholding value adjusts the wavelet coefficients based on the threshold value. |
| III. Finally, the denoised signals reconstructed without affecting any features of signal interest. The reconstruction was done by performing the Inverse Discrete Wavelet Transform (IDWT) of various wavelet coefficients for each decomposition level. |
| 7). Overlap Add method: In this method, the denoised short time signals are added together to get an enhanced speech signal. |
SPEECH MATERIALS |
| The aim of this section is to acquire the speech samples. The experimental part consists of recording each of the well known Telugu Speech proverbs at a normal speaking rate three times in a quiet room by three male and three female native Telugu speakers (age around 23 years) at a sampling rate of 48 kHz and 16 bit value. These digitized speech sounds are then down sampled to 8 kHz and then normalized for the purpose of analysis. The Gaussian white noise is added to the speech signal in four particular SNRs: (15 dB, 10 dB, 5 dB, 0 dB). DWT is used to obtain the Enhanced Speech Signal from noisy Speech Signal. The so produced pairs of reference and Enhanced Signals are used for evaluating the objective measures of speech quality. |
APPLYING DWT TO TELUGU SPEECH SAMPLES |
| A suitable criterion used by [8] for selecting optimal wavelets, is the energy retained in the first N/2 (where N=Total no. of data points in a frame) coefficients. Based on this criterion alone, the Daubechies4 (db4), Daubechies6 (db6), Symlet5 (Sym5) and Symlet7 (Sym7)wavelets were chosen for analysis. Choosing the right decomposition level in the DWT is important for many reasons. For processing speech signals no advantage is gained in going beyond scale 5. At higher levels, the approximation data is not as significant and hence does a poor job in approximating the input signal [12]. However, in this work the speech signal frame is decomposed to scale 2 as most of the Speech denoising procedures based on Wavelet Transform use only up to level 2 or level 3 for Speech signal denoising. The multi-level decomposition implements the analysis-synthesis process which breaks up a signal x(n), to obtain the wavelet coefficients (A1, D1 etc.), and reassembling the signal from the coefficients[13], [14]. The wavelet coefficients are modified according to the threshold criteria using EQ.5-EQ.12 before performing the reconstruction step.Fig.2 shows the process of decomposing and reconstructing the signal waveforms using high pass and low pass filters. The procedure for Telugu Speech denoising using Wavelet Transform was summarized in fig.1 |
OBJECTIVE QUALITY MEASURES |
| The performance of the enhanced signal is analysed through Six objective speech quality measures described here. |
| 1. Signal -to –Noise Ratio: The Signal-to-Noise Ratio (SNR) is the ratio of signal energy to noise energy and it is given [15-19] as, |
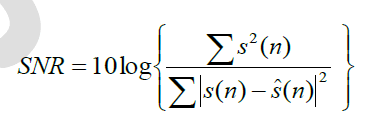 |
| Where s(n) is the clean signal and ïÿýïÿý (n) is the enhanced speech signal and N is the frame length. |
| 2. The Seg-SNR: The Seg-SNR is the frame-based SNR .it is an improved quality measure. here, SNR is measured over short frames and the results are averaged and it is given [15-19] as, |
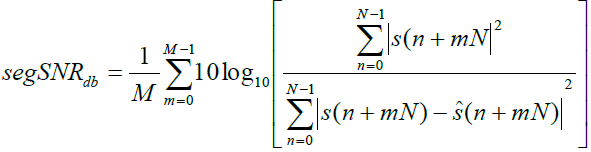 |
| Where s(n) is the clean signal and ïÿýïÿý (n) is the enhanced speech signal , N is the frame length. M represents the number of frames. |
| 3. Weighted Spectral Slope Distance: WSS distance measure computes the weighted difference between the spectral slopes in each frequency band. The spectral slope is obtained as the difference between adjacent spectral magnitudes in decibels. The WSS measure is defined and evaluated [17] as |
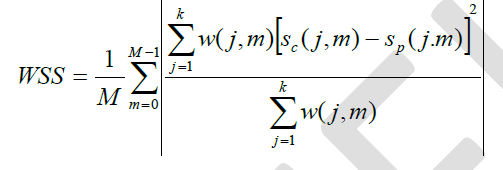 |
| Where W(j, m) are the weights computed. Sc(j, m) and Sp(j, m) are the spectral slopes for jth frequency Band at mth frame of clean and processed speech signals respectively. |
| 4. Log Likelihood Ratio: The LLR measure is based on dissimilarity between the all pole models of the original and enhanced speech and it is given [18] as, |
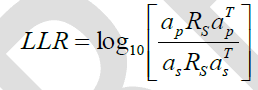 |
| Where ap and as are the LP coefficient vectors for the clean and enhanced speech segments, respectively. Rs denote the autocorrelation matrix of the clean speech segment. |
| 5. Cepstum Distance: It gives an estimate of the log spectral distance between two spectra. It is defined as [15- 19] |
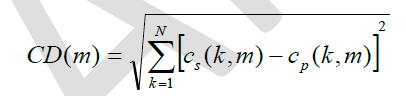 |
| Where Cs(n) and Cp(n) represent the cepstrum of clean and the enhanced speech respectively. Cs(k,m)=Re[IDFT{log||}] (15) |
| The cepstrum coefficients can also be obtained recursively from the LPC coefficients using the following expression [9-10] |
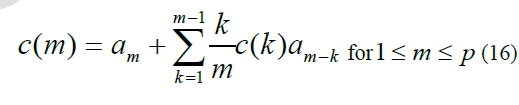 |
| 6. Frequency Weighted Segmental SNR: It is similar to seg-SNR with an additional averaging over frequency bands also.it is defined [15,19] as, |
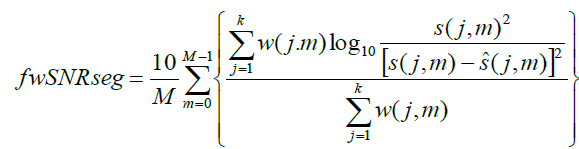 |
| where W (j, m) is the noise-dependent weight applied on the jth frequency band, K is the number of bands, M is the total number of frames in the signal, s(j, m) is the weighted clean signal spectrum in the jth frequency band at the mth frame, andïÿýïÿý (j, m) in the weighted enhanced signal spectrum in the same band. |
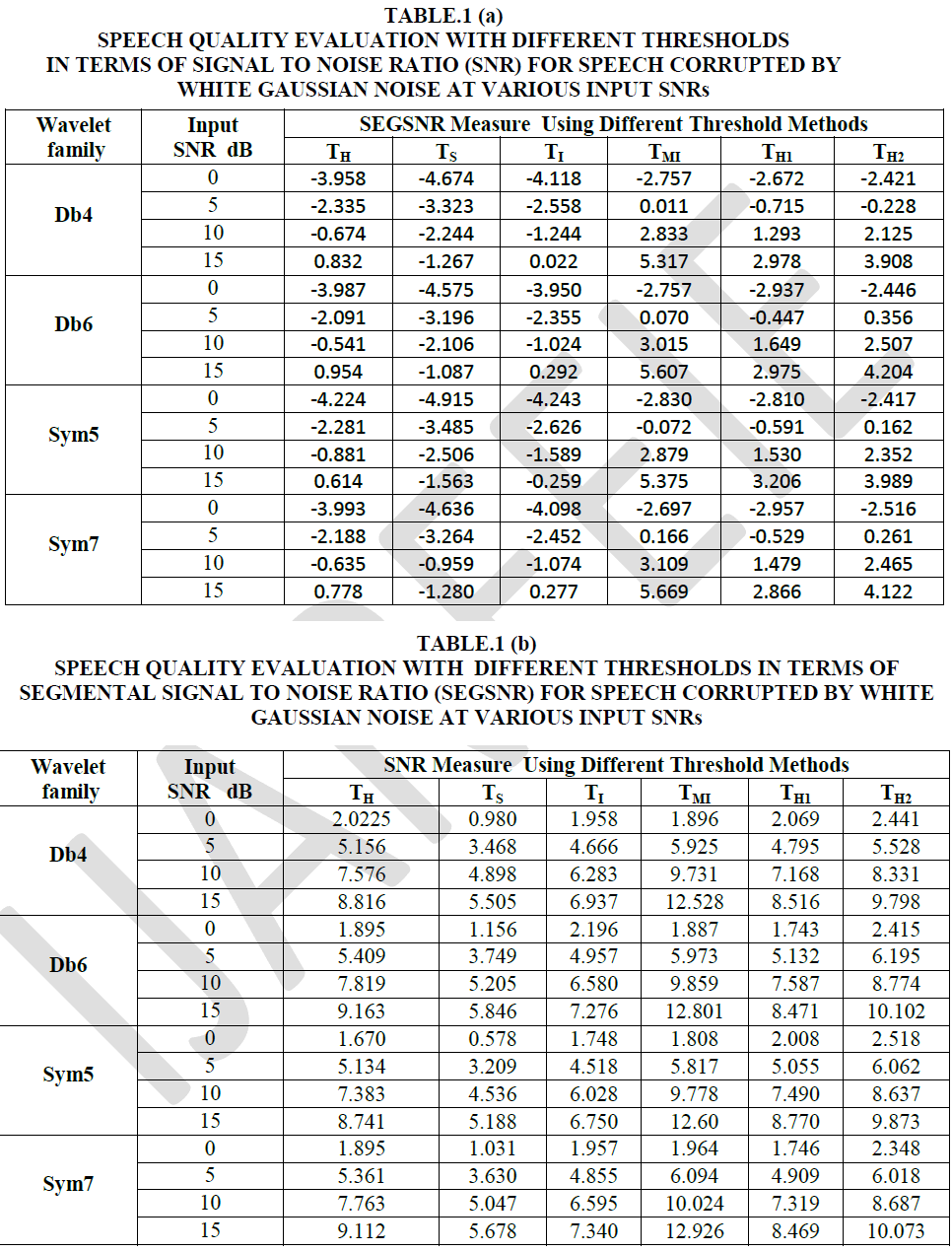
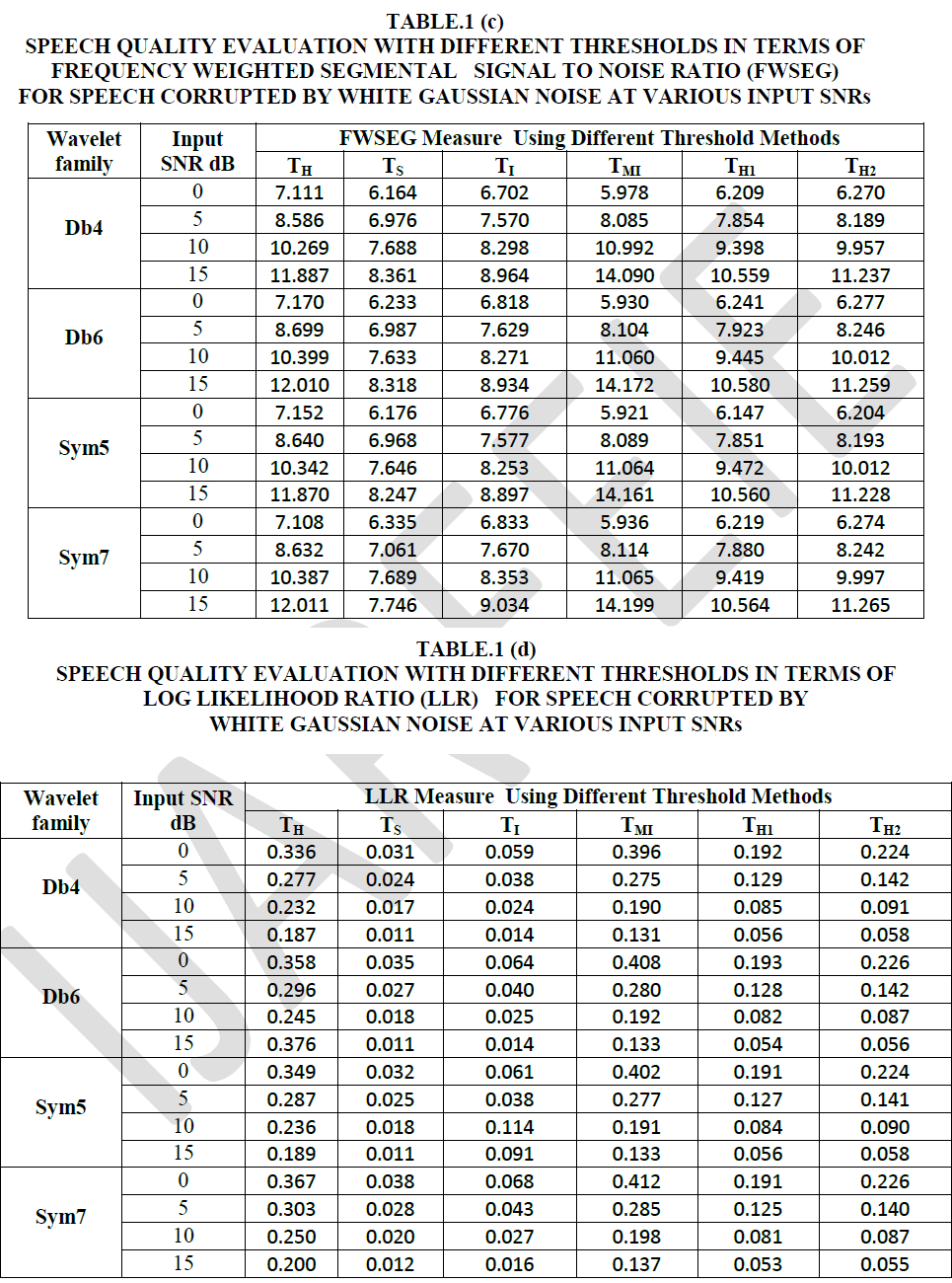
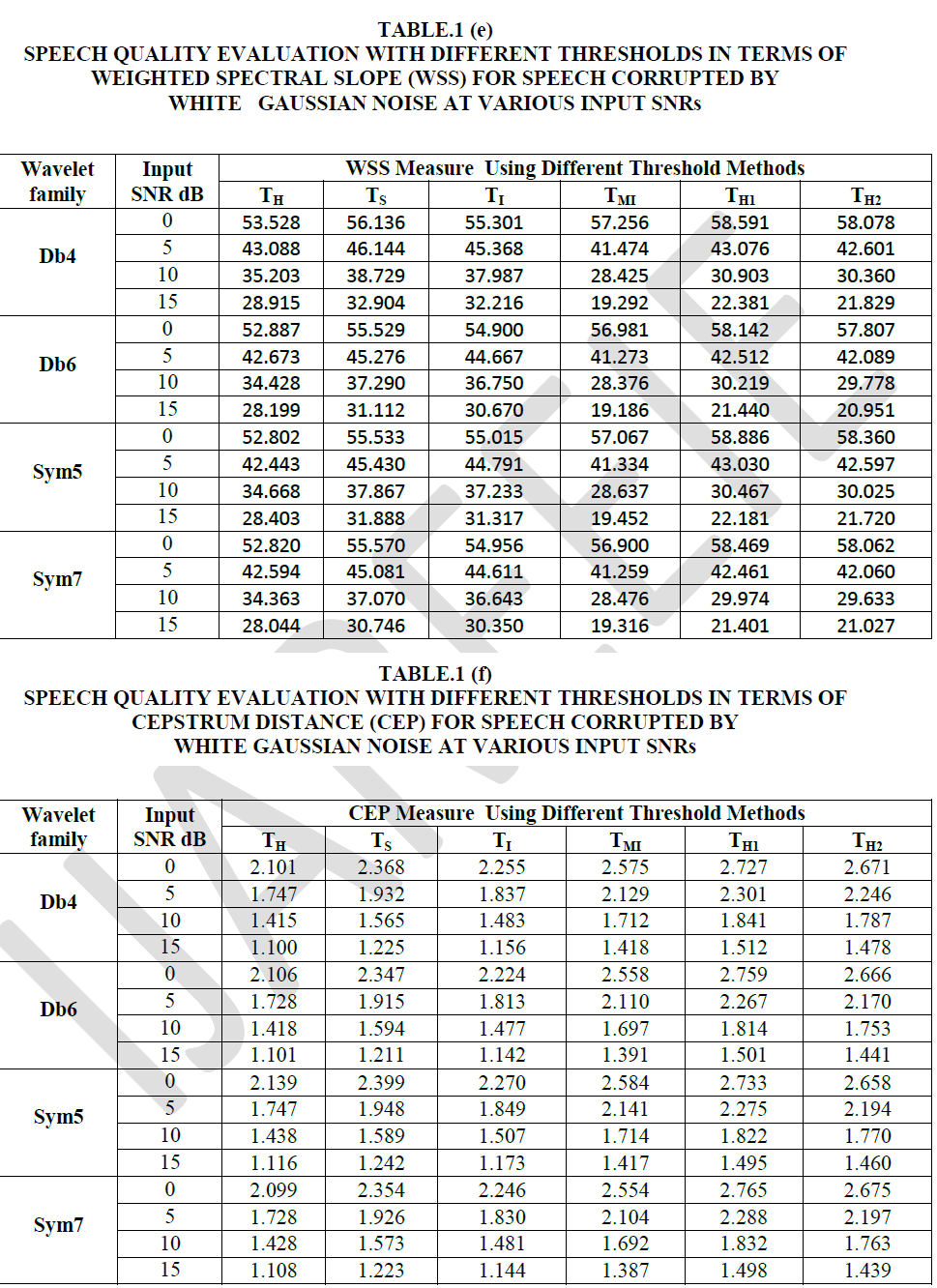
SIMULATION &RESULTS |
| `The Telugu Speech Signals from the authorsâÃâ¬ÃŸ database are being used for processing using Discrete Wavelet Transform denoising algorithms and the obtained denoised signals called Enhanced Speech Signals are used for analysis. Performance of the Enhanced Signal is analyzed by using six objective measures for enhanced speech quality. The processing algorithm and the ones used to give objective estimate of the obtained quality are performed in Matlab. The measures are WSS, LLR, fwseg-SNR, Cep, Seg-SNR, and SNR defined in EQ.13-EQ.18. All the measures are computed by segmenting the Telugu Speech sentences of 32-ms duration using Hamming window with 50% overlap between adjacent frames. A tenth order LPC analysis was used in the computation of LPC- based objective measure LLR. The performance of the Algorithm is studied under Additive Gaussian noise conditions at 0dB, 5dB, 10dB and 15dB SNR levels and presented in Table.1 (a)-1(f). Five Telugu clean speech sentences written in English alphabets spoken by both male and female speakers have been taken from speech corpus developed by the authors are given below and are used for the present work. |
 |
| Gaussian white noise with known SNR is added to these clean speech signals to get noisy signal. The noisy speech signal is decomposed in to wavelet coefficients at a decomposition level of 2. In this de-noising algorithm, Daubechies wavelets (db4, db6) and symlet wavelets (sym5, sym7) are used for denoising. Soft, Hard, Improved, Modified Improved and the proposed Hybrid thresholding methods are applied to the wavelet coefficients to achieve the Enhanced Speech Signal. The performance of enhanced speech in terms of objective measures is presented in Tables1.(a)-1.(f). |
| From the table.1 (a)-1(c) it is concluded that the Db4 and Sym5 give better results in terms of SNR measure under low noisy conditions (0dB) when compared to Db6 and Sym7 wavelets. Considering the fact that, higher SNR, Seg-SNR and fwseg-SNR values give better quality where as LLR, WSS, and CEP measures, lower values indicate a better quality [15],it is evident that Hybrid thresholding methods perform well when compared with the rest of the thresholding methods described in this work in terms of SNR, Seg-SNR and fwseg-SNR. From table 1(d)-1(f), the values of LLR, WSS and CEP measures indicate that the Soft and Improved thresholding methods yield better results in all the four wavelet families considered in this work. Hence the Soft and Improved thresholding schemes are best suited to enhance the Telugu speech quality. From LLR measure it is observed that, a significant improvement is achieved with the Soft thresholding and improved thresholding schemes. The Hybrid thresholding method is also yield results comparable with other methods described in this work except in the case of LLR measure. Observing the results presented in the Tables.1 (a)-1(f), the Telugu Speech Enhancement scheme can be performed well with the proposed Hybrid thresholding method when low SNR conditions prevailed. Our future work focuses on to make a better thresholding function for wavelet denoising scheme to enhance Telugu speech signals. The comparative study for Enhancement of the Telugu speech using other well known standard techniques with the wavelet transform is under way. |
CONCLUSION |
| In this paper, a comparative study of Hard, Soft, Improved, Modified Improved and the proposed Hybrid Thresholding methods using Daubechies and Symlet wavelet families have been made to Enhance Telugu speech signals. This study gives the choice of Threshold function to use Wavelet denoising for Telugu Speech. The effects on the five Telugu Proverbs have been examined. The values of the extracted parameters are also presented. From the results, Db4 and Sym5perform better than other wavelets selected for this study. The Proposed algorithm will be tested with the Real noises like Babble, Car, and Airport etc. as part of their future work. |
ACKNOWLEDGEMENTS |
| The work is carried out through the research facility at the Department of Electronics & Communication Engineering Srikalahasteeswara Institute of Technology (SKIT), Srikalahasti, Chittoor District, Andhra Pradesh, as part of M.Tech Thesis Work. The Authors also would like to thank the authorities of SKIT for encouraging this research work. Our thanks are also to the experts who have contributed towards development of this paper. |
 |
 |
 |
References |
|