Keywords
|
| clustering, ad hoc networks, weighted clustering algorithm (WCA), dynamic mobile adaptive clustering (DMAC), highest degree ID algorithm (HDID) and lowest degree ID algorithm (LDID), cluster-based routing protocol (CBRP). |
INTRODUCTION
|
| A mobile ad hoc network (MANET) consists of a number of mobile nodes that jointly function as a router. A MANET can be created dynamically without any infrastructure. In this network type, the use of the clustering technique significantly reduces the routing traffic that occurs during the routing process. |
| Clustering is used to divide an ad hoc network into small sets of nodes, with each cluster consisting of a cluster head, ordinary nodes, and gateway nodes. Clustering can be used for the effective utilization of resources for large ad hoc networks. |
| This study explores the main clustering mechanisms for selecting cluster heads in ad hoc networks. The mechanisms include the lowest degree ID algorithm (LDID), highest degree ID algorithm (HDID), dynamic mobile adaptive clustering (DMAC), and weighted clustering algorithm (WCA). Different types of routing protocols are used to evaluate the performance of this network type with and without clustering. An NS2 simulator is utilized to study and compare the results. |
| Fig.1 shows all the nodes connected in the ad hoc network without clustering, and Fig.2 shows the same network with clustering. |
RELATED WORKS
|
| In [3], Authors proposed a new weight-based distributed clustering approach that can modify itself dynamically with the topology changes in an ad hoc network. The simulation results proved that the performance of this new approach is better than those of previous approaches. In [4], Authorssuggested a new algorithm, applied an annealing algorithm combined with clustering algorithms as a searching method, and developed another WCA. The simulation results showed that the new WCA performs better than the main WCA.In [5], Authorsproved a new mobility-based clustering algorithm for calculating the different distances between nodes to assess the mobility of any two nodes. The simulation results of this study showed that the new algorithm can be used to provide a robust hierarchical routing structure that can be used in large MANETs.In [6],Authorspresented a DWCA to eliminate communication traffic by predicting node mobility. This study revealed the improvement in the QoS parameters of ad hoc networks. This improvement increased the performance of the whole network.In [7], Authors proposed a new algorithm called the signal and energy efficient clustering (SEEC) algorithm to improve MANET performance. This algorithm is dependent on the energy level and signal strength of each node in the ad hoc network. The simulation results of this study showed that the SEEC algorithm lengthens network lifetime and consumes little energy.In [8], Authorsshowed a theoretical approach to solve the clustering problem in wireless sensor networks. This study suggested that any node must be combined with its neighbouring nodes to make a clustering game for the selection of a cluster head. The results of the study showed that the approach can be used to reduce the problems in the selection of the best node to be a cluster head. |
CLUSTERING
|
| Clustering is one of the most popular techniques used to reduce traffic in routes and minimize energy consumption in large wireless networks by collecting the nodes into groups called clusters. In the clustering algorithm, the agent node of each cluster is called the (cluster head), which is responsible for finding a suitable route for any node in his cluster; the other node that serves as an intermediary for any communication in the cluster is called the gateway. The remaining nodes in the network are called ordinary nodes [9],As shown in Fig. 3. |
| The choice of cluster head depends on different algorithms. To satisfy the requirements of MANETs, any cluster must be verified using the following properties: |
| 1. Any ordinary node must be a neighbor to at least one cluster head. |
| 2. Any ordinary node must be a neighbor to the cluster head with the bigger weight. |
| 3. No two cluster heads can be neighbors [10]. |
CLUSTER STRUCTURE
|
| Two methods can be used to arrange the cluster structure. |
| A- Connectivity-based method: network cluster is arranged based on the number of connectivity for each node in the network. The node with the highest number of neighbor nodes is elected as the cluster head. In this case, if the cluster head loses a neighbor node, its connectivity decreases, and other nodes can be elected as cluster head. |
| B- Identifier-based method: this method depends on the ID of each node. If a node has the lowest/highest ID in its group, it is automatically elected as the cluster head [11]. |
CLUSTER LINKING TYPES
|
| Cluster links are classified into two types based on the nature of connectivity, As shown in Fig. 4. |
| A- Bidirectional link: a cluster link is bidirectional if a two-directional link exists between two nodes of neighbor clusters or if two opposite unidirectional links are found between two different nodes of two different clusters. |
| B- Unidirectional link: a cluster link is unidirectional if only one unidirectional link exists between two nodes. |
APPROACHES FOR CLUSTER HEADSELECTION
|
| Several clustering approaches are used to select cluster heads in ad hoc networks. The cluster head is responsible for keeping the routing information and managing the network nodes. Existing approaches elect the cluster head based either on the IDs of the network nodes or on the location information of the nodes. As shown in Fig.5, the existing approaches for cluster head selection are the LDID, HDID, DMAC, and WCA. Each approach comprises properties and steps for cluster head selection. |
| A-Lowest ID Approach (LDID):LDID clustering is one of the most commonly used clustering schemes in ad hoc networks. The main idea of this algorithm is that the node with the lowest ID in its group is selected to be the cluster head of this group. The selected cluster head manages all communications and maintains all routes of the nodes.As shown in Flowchart 1, the main steps of the LDID process are as follows [12]: |
| Step 1: Every node takes a specific ID that is different from all the other IDs for other nodes; this ID is transmitted all over the list of its neighbouring nodes. |
| Step 2: Any node periodically checks the IDs of its neighbor nodes; if their numbers are greater than the node’s ID, then such node is elected as cluster head. Otherwise, the node elects the neighbor node with the smallest ID as the cluster head. |
| Step 3:Any node with two neighbouring cluster heads is selected as a gateway node, which is used to connect two separate clusters. |
| Step 4:Any node that does not have the previous properties is considered as an ordinary node. |
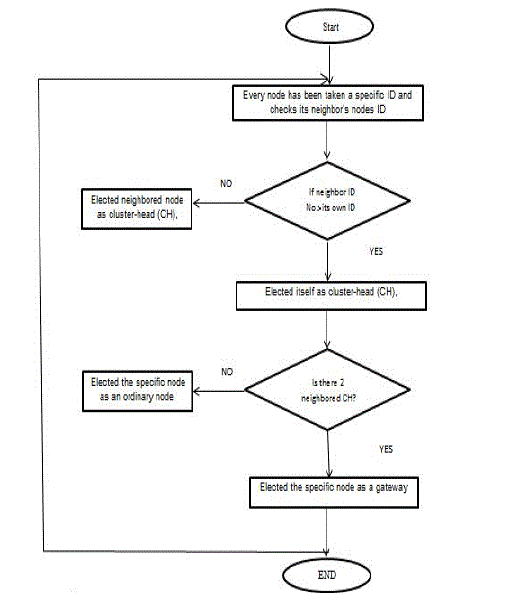 |
| Flowchart 1. The main steps of the LDID process |
| The main attributes of the LDID approach are as follows: |
| 1- Any node can be connected with at least two nodes; hence, this algorithm is very easy to construct. |
| 2- In this type of clustering, no overlapped clustering and only disjoint clustering is permitted. |
| 3- Any node can send only one broadcasting message at a time; connectivity is thus extremely limited [13]. |
| B-Highest Degree Approach (HDID):As suggested by Gerla, the HDID approach is known as connectivity clustering. The HDID is one of the oldest clustering algorithms used for MANETs. It involves three types of nodes: cluster head, gateway, and ordinary node. The main function of a cluster head is to manage the connectivity traffic of the nodes in the cluster. |
| As shown in Flowchart 2, the main steps of the HDID process are as follows: |
| Step 1:Every node takes a specific ID, which is then sent to all other nodes in its specific transmission range. |
| Step 2: Any node that receives this message is inserted as a neighbour node for the sender node. |
| Step 3: The sender node with the largest number of neighbour nodes is elected as the cluster head. If several nodes have the same number of neighbour nodes, then the node with the lowest ID is selected as the cluster head. |
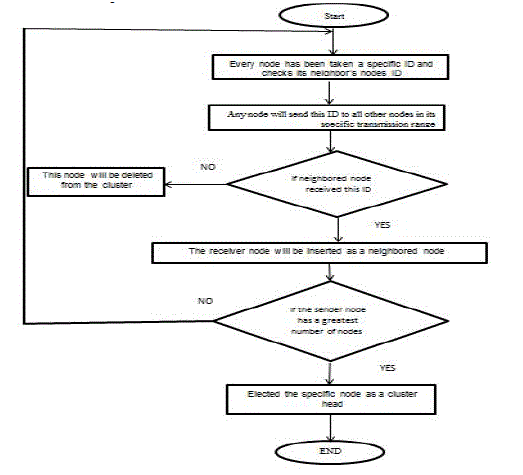 |
| Flowchart 2. The main steps of the HDID process |
| The main attributes of the HDID approach are as follows: |
| 1- This approach does not have any limitations on the number of nodes in a cluster. |
| 2- The main problem is that the cluster head cannot manage a large number of nodes simultaneously because of the limited number of resources [14]. |
| C. Dynamic Mobile Adaptive clustering (DMAC):DMAC is a modified version of the dynamic clustering algorithm (DCA), which is used professionally when the movement of nodes is slow [15]. However, DMAC is better than DCA because it can achieve a high performance even for ad hoc networks with high-speed movement. As shown in Flowchart 3, the main steps of the DMAC process are as follows: |
| Step 1:Every node must be placed in a specific cluster. |
| Step 2:Every node takes a specific weight. |
| Step 3: The node with the highest weight sends a message to all neighbor nodes to be the cluster head. |
| Step 4:The other nodes with smaller weights wait for a cluster head message to decide which appropriate cluster to join. If the nodes do not receive any message from the cluster head, then they are not allowed to join any clusters. |
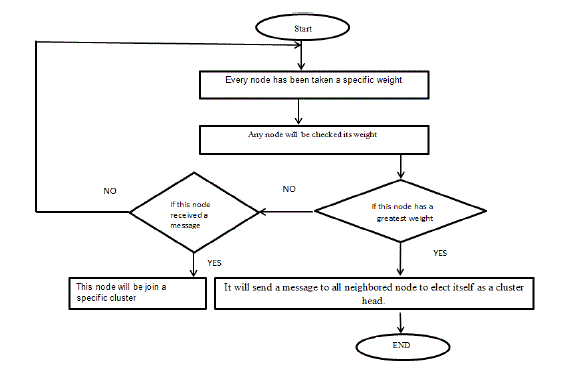 |
| Flowchart 3. The main steps of DMAC process |
| The main attributes of the DMAC approach are as follows: |
| 1- This approach can be considered as a passive approach, which means that nodes consume minimum energy during sleep and idle modes. |
| 2- The overhead of cluster maintenance is reduced as a result of the passive characteristics of this approach [16]. |
| D. Weighted Clustering Approach (WCA): This approach considers many factors, such as power of transmission, degree of each node, and battery power for each node. All of these factors must be used in cluster head selection. The WCA always uses a specific threshold to identify the number of nodes in a cluster and consequently ensure the successful operation of the medium access control (MAC) protocol [17]. |
| As shown in Flowchart 4, the main steps of the WCA are as follows: Step 1: Calculate the degree of each node (n) in a specific transmission range by using eq.(1). |
 |
| Step 2: Calculate the difference in the degree between nodes by using eq.(2). |
 |
| Step 3: Calculate the summation of all the degrees for each node with its neighbour nodes by using eq.(3). |
 |
| Step 4: Calculate the average mobility for any nodeby using eq.(4). |
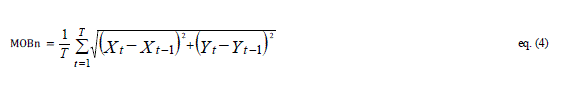 |
| where (Xt, Yt) and (Xt-1, Yt-1) are the locations of node (n) at time t and t-1, respectively. |
| Step 5: Calculate the time of each node to obtain the power consumed by each node. |
| Step 6: Calculate the weights of each node from the previous results. |
| Step 7: Select the node (n) with the minimum weight as the cluster head [3]. |
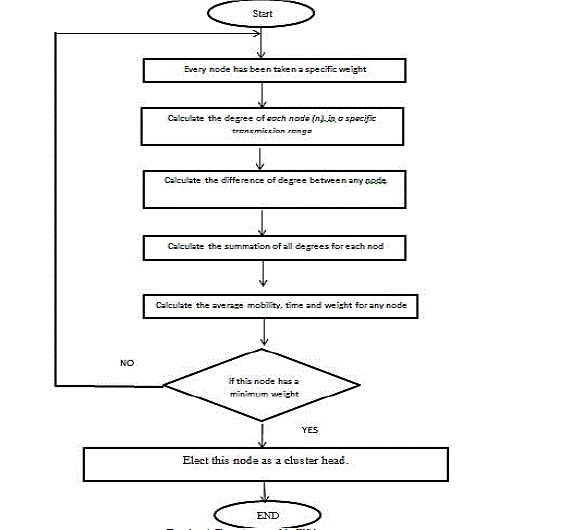 |
| Flowchart 4. The main steps of the WCA process |
| The main attributes of WCA are as follows: |
| 1- The approach provides professional work for the MAC protocol and thus leads to great efficiency. |
| 2- A large amount of battery power is used by the cluster head because of the forwarding packet process; any node can communicate with several other nodes, in which case large amounts of power are consumed [18]. |
ROUTING PROTOCOLS
|
| Routing is the act of carrying a piece of information from a source to a destination in an internetwork. An encounter of a minimum of one intermediate node inside the Internet occurs in this process. Given that routing has already been employed in networks since the 1970s, this concept is no longer a novelty in the field of computer science. However, the concept of routing has slowly been gaining popularity since the mid-1980s. Despite being less complicated and functional in homogeneous environments, high-end and large-scale internetworking shows the most updated development. |
| Fundamentally, the routing concept deals with two activities: making sure that routing paths are optimal and moving the information groups, specifically referred to as packets, along and across an internetwork. The latter is called packet switching, which is easy to understand; by contrast, path determination can become complicated. Routing protocols adopt several metrics for calculating the best path before the packets are sent to their intended destination. These metrics are standard measurements using a number of hops, which are normally used by the routing algorithm to decide on the optimal path that should be used by the packet to reach its destination. The path determination process suggests that routing algorithms kick-start and retain the routing tables, which contain the entire packet route information that varies across routing algorithms. Routing tables contain a wide range of information generated by routing algorithms. The most common entries in the routing table come in the form of IP address prefixes and the next hops. Routing table destination or next hop associations suggest to the router that a destination can be reached in an optimal manner by sending the packet to a router while representing the “next hop” on its way to the final destination. The IP address prefix searches for a set of destinations for which the routing entry is valid. Switching is relatively simpler than path determination, in which a host is determined to send some packets to another server. The host is needed by the router address and sends the packet addressed specifically to the writers of the MAC address; the packet comes with the protocol address from the host to the given destination. The protocol address is then analysed by the router and verified in terms of whether such address knows how the data will reach the destination. If the answer is positive, then the packet is forwarded to its destination; if the answer is negative, then packet would be dropped. Routing is subcategorized into static routing and dynamic routing. Static routing indicates the routing strategy stated through a static and manual manner in the router. This kind of routing keeps intact a routing table that is typically written by a network administrator, and it does not rely on network status or on whether the destination is found active or otherwise. Dynamic routing is the routing strategy that is learnt by either the interior or the exterior routing protocol. This strategy largely depends on the state of the network, which means that the routing table is affected by the destination in an active manner. One great flaw of static routing is that when a new router is introduced or extracted from the network, the administrator is tasked to revise the changes in the routing tables. However, such is not the case with dynamic routing, in which each router is confirmed to be present through the flooding of the information packet into the network; every router within the network is subsequently propelled to learn about the “new visitor” and its entries [19]. |
ROUTING PROTOCOL CLASSIFICATION
|
| Many types of multi-path routing protocols are used for ad hoc networks [20]. These routing protocols are either tabledriven routing protocols (proactive routing protocols) or on-demand routing protocols (reactive routing protocols). Many routing protocols are hybrid and contain combined attributes of both proactive and reactive routing protocols. Proactive routing protocols update their routing tables periodically when a request is made to forward a message through the routes available in the routing table. In reactive routing, when a request for a route is received, the searching process is performed to find a route. In the route search process, the reactive routing protocols find multiple paths for the same source and destination pair. One out of these multiple routes is then selected to forward messages to the destination node. Figure 6 shows the classification of routing protocols. |
| A-Cluster-based Routing Protocol (CBRP): The cluster-based routing protocol (CBRP) was first presented in 1999 by Jiang. In this type of routing protocol, wireless network nodes are divided into a number of disjoint and overlapping clusters. Each cluster selects one of its nodes to be a cluster head. This type of node is responsible for the routing process. The cluster heads are capable of communicating with one another using gateway nodes. Another type of cluster node is a gateway, which is defined as a node with two or more cluster heads as its neighbors. The clustered technique leads to little traffic because any route request is passed between cluster heads only and passing through the entire network is not necessary [21]. |
| B- Ad hoc On-demand Distance Vector (AODV):AODV is one type of demand routing protocol. In AODV, routes are established only when needed to reduce traffic overhead. AODV can efficiently repair link failures. The AODV algorithm allows multi-hop routing between system nodes, which are necessary to establish an ad hoc network. AODV also allows mobile nodes to quickly find routes that are available in active communication for any destination node. In AODV, each node has an equal distance to every other node in the network. Thus, every node maintains a routing table with all known nodes. When a node in an active communication circle loses its communication with the other nodes, it can either repair the route locally by sending a route request to find a new route to the destination node or send a route error, which indicates that the destination node is unreachable. However, the main problem of AODV is the “count to infinity” phenomenon. |
| C- Dynamic Source Routing (DSR): is an on-demand routing protocol. In this protocol, the sequence of nodes that are needed for packets to be transmitted are calculated and processed in the packet header. When packets are sent, the route cache within the specific node is compared with the actual route. If the result is positive, then the packets are forwarded. Otherwise, the route discovery process is initiated again. In other words, the source node specifies the entire route to be followed by a packet and not only the next hop. When the source node does not have a route, it sends a route request to any node that has a path to the specific destination or a route reply to the source node when it can reach such destination. This reply contains the full path embedded in the route request packet. The main advantage of DSR is that private mechanisms are not necessary to reduce loops. Route caching, which is used in DSR, can be used to eliminate the overhead of route discovery. However, DSR also has several disadvantages, such as collisions between numerous route requests made by neighbor nodes [19]. |
| D- Destination-Sequenced Distance Vector (DSDV): is a table-driven routing protocol that adds a sequence number to distance-vector routing and keeps all short duration changes. In this protocol, each node transfers its own routing table updates, important link status changes, and its sequence numbers to other nodes periodically. When two routes to a destination node are received from two different nodes, the one with the highest destination sequence number is selected. However, if the two numbers are equal, the one with the smaller hop count is selected. DSDV always reduces the overhead of control through incremental update and settling time. In DSDV, the routes are maintained by periodic exchanges with the routing table. The settling time and incremental dumps are also used to reduce the overhead of DSDV control. DSDV maintains only the best path instead of maintaining multiple paths to every destination. Therefore, the amount of space in the routing table is reduced, and the table can be used to avoid extra traffic with incremental updates instead of full dump updates. The count-to-infinity problem is also reduced in DSDV [22]. |
NETWORK SIMULATION
|
| This study aims to understand the effect of using clustering in an ad hoc network, measure the performance of cluster routing protocols, and analyze network behavior when clustering is employed. A comparative performance analysis is performedbetween cluster-based CBRP and three other routing protocols, namely, AODV, DSR, and DSDV, based on QoS parameters such as packet delivery ratio (PDR), average throughput, end-to-end delay, and number of dropped packets. The simulations are performed using the network simulator NS2 with continuous bit rates (CBR) as traffic sources. The source destination nodes are moved randomly over the network. The mobility model utilizes a square area of 400 m × 400 m with 25, 50, and 70 nodes. The simulation time is 120 seconds. The model parameters are shown in Table 1. |
PERFORMANCE METRICS
|
| A- Packet delivery ratio: Packet delivery ratio is defined as the ratio between the total number of data packets delivered and the number of data packets sent (Σ Total number of packets received / Σ Total number of packets sent). This ratio is used to illustrate the level of data delivery to the destination node. A high packet delivery ratio indicates the successful delivery of all packets to the destination node and therefore indicates the good performance of the protocol [23]. |
| B- Average throughput: Average throughput is defined as the ratio of received data to simulation time. The data may be transferred over a logical or physical push through a network node. This ratio is always measured in data packets per second or data packets per time slot. |
| C- End-to-end delay: This metric is defined as the time taken by the data packets to reach the destination nodes. Such time can be calculated by dividing the sum of all time differences between the sending and receiving of packets. A low end-to-end delay average in a network is a good performance indicator of the routing protocol. |
| D- Number of dropped packets: When a packet reaches a network layer, the packet is forwarded to the destination if a valid route is available. Otherwise, the packet is buffered until it reaches the destination. If the buffer is full, the packet is dropped [24]. |
ANALYSIS AND RESULTS
|
| A-Packet Delivery Ratio: As shown in Table.2the improvements in PDR are obtained when AODV is used, The value of PDR varied according to number of nodes, as a general conclusion; there are (4% to 8%) improvements in PDR due to the use of AODV, but the when the number of nodes is small(25 nodes) the difference between the CBRP(routing protocol with clustering) and the AODV (routing protocol without clustering) is small value (only 4%)but when the number of nodes increased to (50 and 70 nodes), the differences between CBRP and AODV is became higher and more than (8%). |
| As shown in Fig.7, the CBRP ranks third in packet delivery ratio. The performance of the CBRP is moderate compared with that of the other routing protocols. AODV shows the highest performance among the other protocols, including CBRP, DSDV, and DSR. Even when the number of nodes is increased, the packet delivery ratio in AODV also increases. Therefore, AODV has the best performance in terms of packet delivery ratio, followed by DSDV, CBRP, and DSR. |
| B-Throughput:As shown in Table.3 the improvements in throughput are obtained when CBRP is used, The value of Throughput also varied according to number of nodes, as a general conclusion; there are (30 to 330 Kbps) improvements in throughput due to the use of CBRP, this result obtained when a comparison occurred between CBRP and the other routing protocols, but the when the number of nodes is small(25 nodes) the difference between the CBRP(routing protocol with clustering) and the other routing protocol (without clustering) is small value between (30 to 330 Kbps) but when the number of nodes increased to (50 and 70 nodes), the differences between CBRP and other routing protocols is became smaller and between (9 to 257 Kbps). |
| As shown in Fig.8. The throughput of the CBRP is the highest and shows an increase when the number of nodes decreases, maximum throughput can be obtained in CBRP with(25 nodes) and this value is decreased when the number of nodes increased to (50 and 70 nodes). CBRP is followed by DSDV and DSR. The lowest throughput is that of AODV. |
| C-End-to-End Delay: As shown inTable.4 the improvements in End to End Delay are obtained when DSR is used, The value of End to End Delayalso changed according to number of nodes, the results show that the maximum End to End Delay in AODV , and the differences ofEnd to End Delaybetween AODV and the other routing protocols is (170 msec)but this value decreased when the number of nodes is became greater (50 and 70 nodes), the most important conclusion is that the End to End Delay in CBRP is slightly changed when the number of nodes increased, the differences between the End to End Delay value for all CBRP cases is between (3 to 8 msec) |
| As shown in Fig. 9, the end-to-end delay of the CBRP is moderate compared with that of the other routing protocols. The least end-to-end delay can be obtained using DSR. In this protocol, when the number of nodes decreases, the endto- end delay increases, and vice versa, but AODV shows the highest delay. |
| D-Number of Dropped Packets: As shown in Table.5, the number of dropped packets in CBRP is small and this amount is slightly increased as the number of the nodes increased the amount of increasing is between (4 to 7 packets), the difference between CBRP and other routing protocols is between (10 to 36 packets), which is considered a very great amount and reflected clearly on the performance of the whole network. |
| As shown in Fig.10, the CBRP registers the least number of dropped packets, and this number increases with an increase in the number of nodes. The CBRP is followed by DSDV and DSR. The largest number of dropped packets is observed in AODV; this number always increases as the number of nodes increases. |
CONCLUSION
|
| This study shows that the clustering algorithm can be used to reduce routing traffic by dividing the network into a number of clusters. The results of this study prove that the CBRP has a moderate packet delivery ratio and has the best throughput, even when the network size is increased. These performance results are attributed to the great reduction in flooding in the route discovery process. The CBRP has more delay time compared with DSR and DSDV because it consumes a considerable amount of time for maintaining the cluster structure. The number of dropped packets in the CBRP is the lowest among the routing protocols because of the clustering structure and the transferring process of any cluster, which is limited to the group of nodes separated from the other clusters. Considering all findings, we conclude that the clustering algorithm can be used to enhance the performance of ad hoc networks. |
Tables at a glance
|
 |
|
|
|
|
| Table 1 |
Table 2 |
Table 3 |
Table 4 |
Table 5 |
|
Figures at a glance
|
 |
 |
 |
 |
 |
| Figure 1 |
Figure 2 |
Figure 3 |
Figure 4 |
Figure 5 |
|
|
|
|
|
|
| Figure 6 |
Figure 7 |
Figure 8 |
Figure 9 |
Figure 10 |
|
References
|
- WAN C., "An Introduction on Ad-Hoc Networks", Wiley Publisher,pp.15,2006.
- Sangeetha T.,Venkatesh K. K, Rajesh M., Manikandan S. K., "QoS Aware Routing Protocol to Improve Packet Transmission in Shadow-FadingEnvironment for Mobile Ad Hoc Networks", Scientific Research Publishing,vol.5, pp.611-617,2013,.
- Mainak C., Sajal K., and Damla T.,"WCA: A Weighted Clustering Algorithm for MobileAd Hoc Networks", Kluwer Academic Publishers,Netherlands , pp. 193–204, 2002.
- Turgut D., Turgut B., Elmasri R., and Than V. L., "Optimizing Clustering Algorithm in Mobile Ad hoc Networks Using Simulated Annealing",Proceedings of IEEE Wireless Communications and Networking Conference (WCNC), pp. 1492-1497,2003.
- Inn E., Winston K., SeahG.,"Mobility-based d-Hop Clustering Algorithm for Mobile Ad Hoc Networks",Journal of Computer and SystemSciences, Vol. 72, Issue 7, pp. 1144–1155, 2006.
- Muthuramalingam S., Raja R. R., KothaiP. and Karthiga V. D.,"A Dynamic Clustering Algorithm for MANETs by modifying Weighted ClusteringAlgorithm with Mobility Prediction" , International Journal of Computer and Electrical Engineering, Vol. 2, No. 4, pp.1793-8163, 2010.
- Alak R., Manasi H., Mrinal K. D., "Energy Efficient Cluster Based Routing in MANET", International Conference on Communication, Information& Computing Technology (ICCICT), pp.1-5, 2012,.
- Dongfeng X., Qi S., Qianwei Z., Yunzhou Q., and Xiaobing Y., "An Efficient Clustering Protocol for Wireless Sensor Networks Based onLocalized Game Theoretical Approach", International Journal of Distributed Sensor Networks, Vol. 2013, pp.1-11,2013.
- Damianos G., Grammati P., Charalampos K., BasilisM.,"Clustering of Mobile Ad Hoc Networks: An Adaptive Broadcast Period Approach", IEEEInternational Conference on Communications, pp.4034-4036, 2006.
- Stefano B.,"Distributed Clustering for Ad Hoc Networks", Parallel Architectures, Algorithms, and Networks, Proceedings. Fourth InternationalSymposium, pp.310-315, 1999.
- Ching-Chuan C., Hsiao K. W., Winston L., and Mario G., “ Routing in clustered multihop, mobile wireless networks with fading channel,.”Proceedings of IEEE Singapore International Conference on Networks (SICON ’97), pp.197–211, 1997.
- Basu P., Khan N., and Little T. D. , "A Mobility Based Metric for Clustering in Mobile Ad Hoc Networks ", Distributed Computing System,,Workshop on Wireless Networks and Mobile Computing, Phoenix, IEEE conference publications , pp.413-418, 2001, .
- Osama Y., Marwan K. and Ramasubramanian, , "Node clustering for sensor wireless network", IEEE Network Magazine, pp.1-36, 2006.
- Rui X., Wunsch D., "Survey of clustering algorithm", IEEE Transaction on Neural Networks, Vol. 16, Issue 3, pp.510-514, 2007.
- Basagni S., "Distributed Clustering for Ad Hoc Networks", Proceedings of the International Symposium on Parallel Architectures, Algorithms andNetworks (ISPAN), pp.310-315, 2012.
- Chun S.Y.,"A PERFORMANCE COMPARISON OF CLUSTERING ALGORITHMS IN AD HOC NETWORKS", Master thesis, College ofEngineering and Computer Science, University of Central Florida Orlando,2006.
- Ratish A., Roopam G., Mahesh M., "REVIEW OF WEIGHTED CLUSTERING ALGORITHMS FOR MOBILE AD HOC NETWORKS",Computer Science and Telecommunications Journal, Vol.1, pp.71-74, 2011.
- "Clustering in Mobile Ad hoc Networks, internet drafts, university central Florida, 2002 .
- Norrozila S., Osamah I. K., Ghaidaa M. A., Muamer N. M. and Ayoob A. A, "Effect of Using Different QoS Parameters in Performance ofAODV, DSR, DSDV AND OLSR Routing Protocols In MANET", Proc. of the International Conference .on Advances in Computing andInformation Technology—ACIT, pp.72-76, 2014.
- Tsai H. W., Chen T.S. and Chu C.P., “An On-Demand Routing Protocol with Backtracking for Mobile Ad Hoc Networks",IEEE WirelessCommunications and Networking Conference, Vol.3, pp.1557-1562, 2004.
- Jiang M., Li J. and Tay Y.C.,“Cluster Based Routing Protocol (CBRP),”Functional Specification Internet Draft, draft-ietf-manet-cbrp.txt,1999.
- Norrozila S., Ghaidaa M. A., Osamah I. K.andMuamer N. M., "Effect of Using Different Propagations on Performance of OLSR and DSDVRouting Protocols", The 5th IEEE International Conference on Intelligent Systems, Modelling and Simulation, Langkawi, Malaysia, pp. 27 - 34,2014.
- Bikram K.M., Nihar R.N., Amiya K.R. and Sagarika S.,“IMPROVING THE EFFICIENCY OF CLUSTERING BY USING AN ENHANCEDCLUSTERING METHODOLOGY”, International Journal of Advances in Engineering & Technology (IJAET),Vol.4, Issue-2, pp. 415-424,2012.
- Nor S., Mohamad U., Azizol A. and Ahmad F. A., “Performance Evaluation of AODV, DSDV & DSR Routing Protocol in GridEnvironment”, IJCSNS International Journal of Computer Science and Network Security, VOL.9 NO.7, pp.261-269, 2009.
|