International Journal of Innovative Research in Computer and Communication Engineering
ISSN ONLINE(2320-9801) PRINT (2320-9798)
ISSN ONLINE(2320-9801) PRINT (2320-9798)
| Nisha, Rafiya Shahana, Mustafa B Bearys Institute of Technology, Mangalore, India |
| Related article at Pubmed, Scholar Google |
Visit for more related articles at International Journal of Innovative Research in Computer and Communication Engineering
With the increasing proliferation of multicore processors, parallelization of applications has become a priority task. One considers parallelism while writing new applications, to exploit the available computing power. Similarly, parallelization of legacy applications for performance benefits is also important. In modern computersystems loops present a great deal of opportunities for increasing Instruction Level andThread Level Parallelism. Techniques are needed to avoid unnecessary checks to assure that only the correct number of iterations are executed. In this paper we present a survey of basic loop transformation techniquesthat can improve the performance by eliminating some unnecessary conditional instructions checking for iteration bounds. The objective of this work is to come up with a nice survey of loop transformations. We present information on the number of instructionseliminated as well as on thegeneral transformations, mostly at the source level. Depending on the target architecture, the goal of loops transformations are: improve data reuse and data locality, efficient use of memory hierarchy, reducing overheads associated with executing loops, instructions pipeline, maximize parallelism.Loop transformations can be performed at different levels by the programmer, the compileror specialized tools. Loop optimization is the process of the increasing execution speed and reducing the overheads associated of loops. Thus, loops optimization is critical in high performance computing. Our techniques are applicable to mostmodern architecture including superscalar, multithreaded, VLIW or EPIC systems.
KEYWORDS |
| Loop transformation technique, Loop optimization,parallelization. |
I. INTRODUCTION |
| Most of the time, the most time consuming part of a program is on loops. Loop-level parallelism is well known techniques in parallel programming. Domain decomposition is used for solving computer vision applications, while loop-level parallelism is a common approach used by standards like Open MP. Thus, loops optimization is critical in high performance computing. Depending on the target architecture, Loop transformations have the following goals: Improve data reuse and data locality, efficient use of memory hierarchy, reducing overheads associated with executing loops instructions pipeline and to maximize parallelism. |
| Loop transformations can be performed at different levels by the programmer, the compiler, or specialized tools. At high level, some well known transformations commonly considered are: Loop interchange, Loop reversal, Loop skewing, Loop blocking, Loop (node) splitting, Loop fusion, Loop fission, Loop unrolling, Loop un-switching, Loop inversion, Loop vectorization and Loop parallelization.c |
II. MOTIVATION |
| Main motivation is to enabling portable programming without sacrificing performance. Loop transformation can change the order in which the iteration space is traversed. It can also expose parallelism, increase available ILP, or improve memory behavior. Dependence testing is required to check validity of transformation. |
| Optimizing frame-work includes improving the order of memory accesses to exploit all levels of the memory hierarchy, such as in cache line size. It also improves cache reuse by dividing the iteration space into tiles and iterating over these tiles. In order to provide greater ILP, we can unroll the loop such that each new iteration actually corresponds to several iterations of the original loop. Thus unrolling is useful in a variety of processors, including simple pipelines, statically scheduled Superscalar and VLIW systems. |
| There exists a dependence if there two statement instances that refer to the same memory location and (at least) one of them is a write.There should not be a write between these two statement instances. Also dependency occurs if there is a flow dependence between two statements S1 and S2 in a loop, then S1 writes to a variable in an earlier iteration than S2 reads that variable. The various dependency tests available are: Separability test, GCD test, Range test and Fourier-Motzkin test.For time critical applications, expensive tests like Omega test can be used. |
III. LOOP TRANSFORMATIONS |
| The various loop transformations such as loop interchange, reversal, skewing and blocking are useful for two important goals: parallelism and efficient use of the memory hierarchy.A survey of the various loop transformation is given as follows: |
| A. SCALAR EXPANSION: |
| To overcome from the dependencies we use scalar expansion for removing false dependencies by introducing extra storage.Scalars introduce S2_aS1 dependence in loops. They can manifest as compiler generated temporaries. |
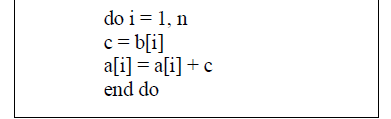 |
| This dependence can be eliminated by expanding the scalar into an array, effectively giving each iteration a private copy |
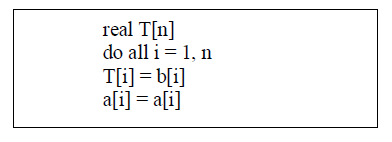 |
| B. LOOP PERMUTATION: |
| Loop interchange simply exchanges the position of two loops in a loop nest. One of the main uses is to improve the behavior of accesses to an array. It is also known as loop interchange. Loop interchange simply exchanges the position of two loops in a loop nest. |
| For example, given a column-major storage order1, the following code accesses a[] with astride of n. This may interact very poorly with the cache, especially if the stride is larger than the length of a cache line or is a multiple of a power of two, causing collisions in set-associative caches. |
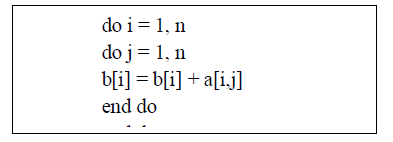 |
| Interchanging the loops alters the access pattern to be along consecutive memory locations of a[], greatly increasing the effectiveness of the cache. |
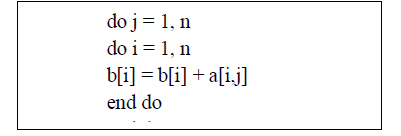 |
| However, loop interchange is only legal if the dependence vector of the loop nest remains lexicographically positive after the interchange, which alters the order of dependencies to match the new loop order. For example, the following loop nest cannot be interchanged since its dependency vector is (1, −1). The interchanged loops would end up using future, uncomputed values in the array. |
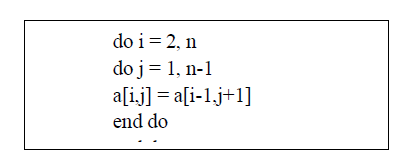 |
| Similarly, loop interchange can be used to control the granularity of the work in nested loops. For example, by moving a parallel loop outwards, the necessarily serial work is moved towards the inner loop, increasing the amount of work done per fork-join operation. |
| C. LOOP REVERSAL: |
| Loop reversal reverses the order in which values are assigned to the index variable. This is a subtle optimization which can help eliminate dependencies and thus enable other optimizations. Also, certain architectures utilize looping constructs at Assembly language level that count in a single direction only (e.g. decrement-jump-if-not-zero (DJNZ)). For example, the following code cannot be interchanged or have its inner loop parallelized because of (1, −1) dependencies. |
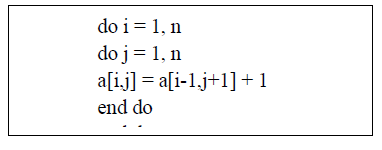 |
| Reversing the inner loop yields (1, 1) dependencies. The loops can now be interchanged and/or the inner loop made parallel. |
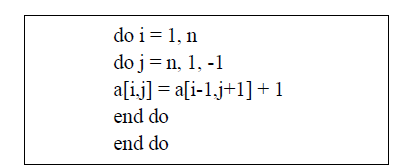 |
| D. LOOP SKEWING |
| Loop skewing takes a nested loop iterating over a multidimensional array, where each iteration of the inner loop depends on previous iterations, and rearranges its array accesses so that the only dependencies are between iterations of the outer loop. |
| Let’s illustrate the process with the following simple loop: |
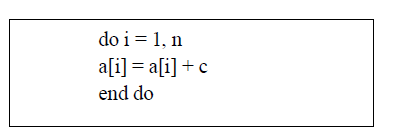 |
| Let’s assume that strips of 64 array elements are desirable. The first new line computes the multiple of 64 closest to n. The outer loop iterates towards this multiple in increments of 64. A new inner loop performs the original loop on the current strip. Finally, a fix up loop may be required if n is not a multiple of 64. |
| Note that this inner loop could also be converted into a do all loop. |
 |
| F. LOOP (NODE) SPLITTING: |
| Cyclic dependencies in a loop prevent loop fission (Section 4.8). For example, the following loop has a flow dependence S1_f0S2 and an anti-dependence S2_a1S1 bothon a[], forming a cycle. |
 |
| H. LOOP FISSION: |
| Loop fission/distribution attempts to break a loop into multiple loops over the same index range but each taking only a part of the loop's body. This can improve locality of reference, both of the data being accessed in the loop and the code in the loop's body. |
| The following code shows this by having a distance zero flow dependence from the first to second statement. |
 |
| J. LOOP UNSWITCHING: |
| Unswitching moves a conditional inside a loop outside of it by duplicating the loop's body, and placing a version of it inside each of the if and else clauses of the conditional.The following example shows a loop with a conditional execution path in its body.Having to perform a test and jump inside every iteration reduces the performance of the loop as it prevents the CPU, barring sophisticated mechanisms such as trace caches or speculative branching, from efficiently executing the body of the loop in a pipeline. The conditional also inhibits do all parallelization of the loop since any conditional statement must execute in order after the test. |
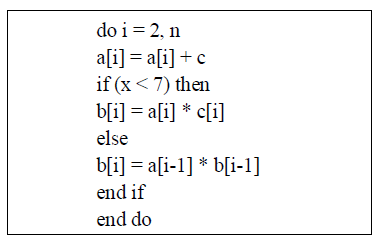 |
| Similarly to Loop-Invariant Code Motion, if the loop-invariant expression is a conditional, then it can be moved to the outside of the loop, with each possible execution path replicated as independent loops in each branch. This multiplies the total code size, but reduces the running set of each possible branch, can expose parallelism in some of them, plays well with CPU pipelining, and eliminates therepeated branch test calculations. Note that a guard may also be necessary to avoid branching to a loop that would never execute over a given range. |
 |
| K. LOOP INVERSION: |
| This technique changes a standard while loop into a do-while (a.k.a. repeat/until) loop wrapped in an if conditional, reducing the number of jumps by two for cases where the loop is executed. Doing so duplicates the condition check (increasing the size of the code) but is more efficient because jumps usually cause a pipeline stall. Additionally, if the initial condition is known at compile-time and is known to be side-effect-free, the if guard can be skipped. |
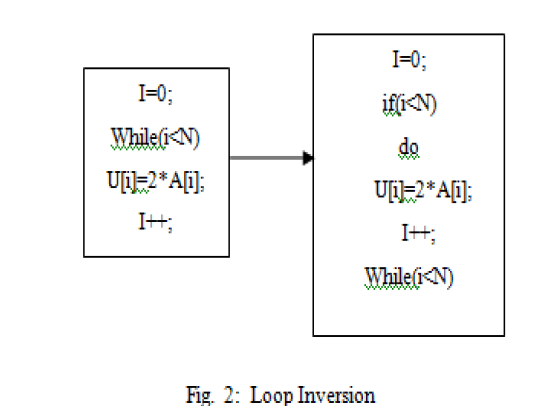 |
| L. LOOP VECTORIZATION: |
| Vectorization attempts to run as many of the loop iterations as possible at the same time on a multiple-processor system.Loop vectorization attempts to rewrite the loop in order to execute its body using vector instructions. Such instructions are commonly referred as SIMD (Single Instruction Multiple Data), where multiple identical operations are performed simultaneously by the hardware. |
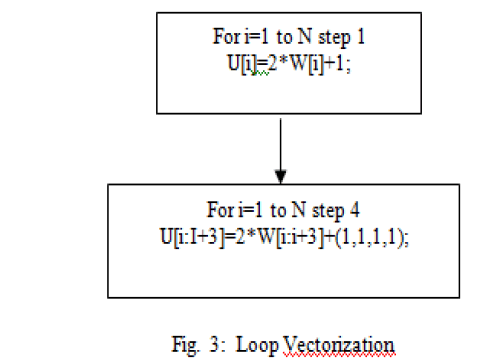 |
| M. LOOP PARALLELIZATION: |
| Loop parallelization is a special case for Automatic parallelization focusing on loops, restructuring them to run efficiently on multiprocessor systems. It can be done automatically by compilers (named automatic parallelization) or manually (inserting parallel directives like OpenMP). |
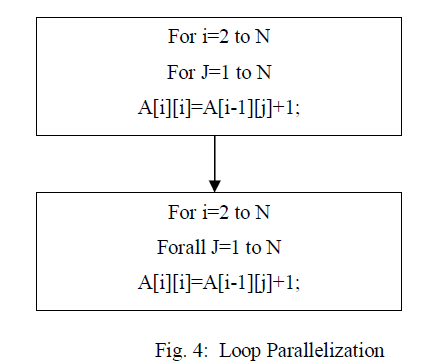 |
IV. CONCLUSION |
| The survey of the various transformations for general loop nests was carried out in this work. Different kinds of loop transformations can be applied in order to expose the parallelism before moving into explicit parallelization.In this paper we surveyed the loop transformation techniques and they have been shown useful for extracting parallelism from nested loops for a large class of machine, from vector machine and VLIW machine to multi processors architectures. |
References |
|